使用DQN训练AI玩游戏
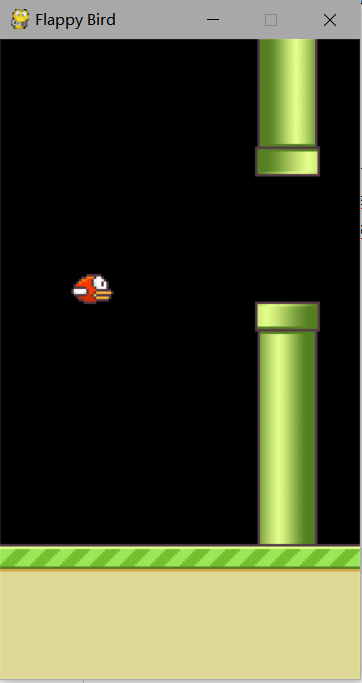
实验结果
实验源代码


#wrapped_flappy_bird.py import numpy as np import sys import random import pygame import flappy_bird_utils import pygame.surfarray as surfarray from pygame.locals import * from itertools import cycle FPS = 30 SCREENWIDTH = 288 SCREENHEIGHT = 512 pygame.init() FPSCLOCK = pygame.time.Clock() SCREEN = pygame.display.set_mode((SCREENWIDTH, SCREENHEIGHT)) pygame.display.set_caption('Flappy Bird') IMAGES, SOUNDS, HITMASKS = flappy_bird_utils.load() PIPEGAPSIZE = 100 # gap between upper and lower part of pipe BASEY = SCREENHEIGHT * 0.79 PLAYER_WIDTH = IMAGES['player'][0].get_width() PLAYER_HEIGHT = IMAGES['player'][0].get_height() PIPE_WIDTH = IMAGES['pipe'][0].get_width() PIPE_HEIGHT = IMAGES['pipe'][0].get_height() BACKGROUND_WIDTH = IMAGES['background'].get_width() PLAYER_INDEX_GEN = cycle([0, 1, 2, 1]) class GameState: def __init__(self): self.score = self.playerIndex = self.loopIter = 0 self.playerx = int(SCREENWIDTH * 0.2) self.playery = int((SCREENHEIGHT - PLAYER_HEIGHT) / 2) self.basex = 0 self.baseShift = IMAGES['base'].get_width() - BACKGROUND_WIDTH newPipe1 = getRandomPipe() newPipe2 = getRandomPipe() self.upperPipes = [ {'x': SCREENWIDTH, 'y': newPipe1[0]['y']}, {'x': SCREENWIDTH + (SCREENWIDTH / 2), 'y': newPipe2[0]['y']}, ] self.lowerPipes = [ {'x': SCREENWIDTH, 'y': newPipe1[1]['y']}, {'x': SCREENWIDTH + (SCREENWIDTH / 2), 'y': newPipe2[1]['y']}, ] # player velocity, max velocity, downward accleration, accleration on flap self.pipeVelX = -4 self.playerVelY = 0 # player's velocity along Y, default same as playerFlapped self.playerMaxVelY = 10 # max vel along Y, max descend speed self.playerMinVelY = -8 # min vel along Y, max ascend speed self.playerAccY = 1 # players downward accleration self.playerFlapAcc = -7 # players speed on flapping self.playerFlapped = False # True when player flaps def frame_step(self, input_actions): pygame.event.pump() reward = 0.1 terminal = False if sum(input_actions) != 1: raise ValueError('Multiple input actions!') # input_actions[0] == 1: do nothing # input_actions[1] == 1: flap the bird if input_actions[1] == 1: if self.playery > -2 * PLAYER_HEIGHT: self.playerVelY = self.playerFlapAcc self.playerFlapped = True #SOUNDS['wing'].play() # check for score playerMidPos = self.playerx + PLAYER_WIDTH / 2 for pipe in self.upperPipes: pipeMidPos = pipe['x'] + PIPE_WIDTH / 2 if pipeMidPos <= playerMidPos < pipeMidPos + 4: self.score += 1 #SOUNDS['point'].play() reward = 1 # playerIndex basex change if (self.loopIter + 1) % 3 == 0: self.playerIndex = next(PLAYER_INDEX_GEN) self.loopIter = (self.loopIter + 1) % 30 self.basex = -((-self.basex + 100) % self.baseShift) # player's movement if self.playerVelY < self.playerMaxVelY and not self.playerFlapped: self.playerVelY += self.playerAccY if self.playerFlapped: self.playerFlapped = False self.playery += min(self.playerVelY, BASEY - self.playery - PLAYER_HEIGHT) if self.playery < 0: self.playery = 0 # move pipes to left for uPipe, lPipe in zip(self.upperPipes, self.lowerPipes): uPipe['x'] += self.pipeVelX lPipe['x'] += self.pipeVelX # add new pipe when first pipe is about to touch left of screen if 0 < self.upperPipes[0]['x'] < 5: newPipe = getRandomPipe() self.upperPipes.append(newPipe[0]) self.lowerPipes.append(newPipe[1]) # remove first pipe if its out of the screen if self.upperPipes[0]['x'] < -PIPE_WIDTH: self.upperPipes.pop(0) self.lowerPipes.pop(0) # check if crash here isCrash= checkCrash({'x': self.playerx, 'y': self.playery, 'index': self.playerIndex}, self.upperPipes, self.lowerPipes) if isCrash: #SOUNDS['hit'].play() #SOUNDS['die'].play() terminal = True self.__init__() reward = -1 # draw sprites SCREEN.blit(IMAGES['background'], (0,0)) for uPipe, lPipe in zip(self.upperPipes, self.lowerPipes): SCREEN.blit(IMAGES['pipe'][0], (uPipe['x'], uPipe['y'])) SCREEN.blit(IMAGES['pipe'][1], (lPipe['x'], lPipe['y'])) SCREEN.blit(IMAGES['base'], (self.basex, BASEY)) # print score so player overlaps the score # showScore(self.score) SCREEN.blit(IMAGES['player'][self.playerIndex], (self.playerx, self.playery)) image_data = pygame.surfarray.array3d(pygame.display.get_surface()) pygame.display.update() FPSCLOCK.tick(FPS) #print self.upperPipes[0]['y'] + PIPE_HEIGHT - int(BASEY * 0.2) return image_data, reward, terminal def getRandomPipe(): """returns a randomly generated pipe""" # y of gap between upper and lower pipe gapYs = [20, 30, 40, 50, 60, 70, 80, 90] index = random.randint(0, len(gapYs)-1) gapY = gapYs[index] gapY += int(BASEY * 0.2) pipeX = SCREENWIDTH + 10 return [ {'x': pipeX, 'y': gapY - PIPE_HEIGHT}, # upper pipe {'x': pipeX, 'y': gapY + PIPEGAPSIZE}, # lower pipe ] def showScore(score): """displays score in center of screen""" scoreDigits = [int(x) for x in list(str(score))] totalWidth = 0 # total width of all numbers to be printed for digit in scoreDigits: totalWidth += IMAGES['numbers'][digit].get_width() Xoffset = (SCREENWIDTH - totalWidth) / 2 for digit in scoreDigits: SCREEN.blit(IMAGES['numbers'][digit], (Xoffset, SCREENHEIGHT * 0.1)) Xoffset += IMAGES['numbers'][digit].get_width() def checkCrash(player, upperPipes, lowerPipes): """returns True if player collders with base or pipes.""" pi = player['index'] player['w'] = IMAGES['player'][0].get_width() player['h'] = IMAGES['player'][0].get_height() # if player crashes into ground if player['y'] + player['h'] >= BASEY - 1: return True else: playerRect = pygame.Rect(player['x'], player['y'], player['w'], player['h']) for uPipe, lPipe in zip(upperPipes, lowerPipes): # upper and lower pipe rects uPipeRect = pygame.Rect(uPipe['x'], uPipe['y'], PIPE_WIDTH, PIPE_HEIGHT) lPipeRect = pygame.Rect(lPipe['x'], lPipe['y'], PIPE_WIDTH, PIPE_HEIGHT) # player and upper/lower pipe hitmasks pHitMask = HITMASKS['player'][pi] uHitmask = HITMASKS['pipe'][0] lHitmask = HITMASKS['pipe'][1] # if bird collided with upipe or lpipe uCollide = pixelCollision(playerRect, uPipeRect, pHitMask, uHitmask) lCollide = pixelCollision(playerRect, lPipeRect, pHitMask, lHitmask) if uCollide or lCollide: return True return False def pixelCollision(rect1, rect2, hitmask1, hitmask2): """Checks if two objects collide and not just their rects""" rect = rect1.clip(rect2) if rect.width == 0 or rect.height == 0: return False x1, y1 = rect.x - rect1.x, rect.y - rect1.y x2, y2 = rect.x - rect2.x, rect.y - rect2.y for x in range(rect.width): for y in range(rect.height): if hitmask1[x1+x][y1+y] and hitmask2[x2+x][y2+y]: return True return False flappy_bird_utils.py import pygame import sys def load(): # path of player with different states PLAYER_PATH = ( 'assets/sprites/redbird-upflap.png', 'assets/sprites/redbird-midflap.png', 'assets/sprites/redbird-downflap.png' ) # path of background BACKGROUND_PATH = 'assets/sprites/background-black.png' # path of pipe PIPE_PATH = 'assets/sprites/pipe-green.png' IMAGES, SOUNDS, HITMASKS = {}, {}, {} # numbers sprites for score display IMAGES['numbers'] = ( pygame.image.load('assets/sprites/0.png').convert_alpha(), pygame.image.load('assets/sprites/1.png').convert_alpha(), pygame.image.load('assets/sprites/2.png').convert_alpha(), pygame.image.load('assets/sprites/3.png').convert_alpha(), pygame.image.load('assets/sprites/4.png').convert_alpha(), pygame.image.load('assets/sprites/5.png').convert_alpha(), pygame.image.load('assets/sprites/6.png').convert_alpha(), pygame.image.load('assets/sprites/7.png').convert_alpha(), pygame.image.load('assets/sprites/8.png').convert_alpha(), pygame.image.load('assets/sprites/9.png').convert_alpha() ) # base (ground) sprite IMAGES['base'] = pygame.image.load('assets/sprites/base.png').convert_alpha() # sounds if 'win' in sys.platform: soundExt = '.wav' else: soundExt = '.ogg' SOUNDS['die'] = pygame.mixer.Sound('assets/audio/die' + soundExt) SOUNDS['hit'] = pygame.mixer.Sound('assets/audio/hit' + soundExt) SOUNDS['point'] = pygame.mixer.Sound('assets/audio/point' + soundExt) SOUNDS['swoosh'] = pygame.mixer.Sound('assets/audio/swoosh' + soundExt) SOUNDS['wing'] = pygame.mixer.Sound('assets/audio/wing' + soundExt) # select random background sprites IMAGES['background'] = pygame.image.load(BACKGROUND_PATH).convert() # select random player sprites IMAGES['player'] = ( pygame.image.load(PLAYER_PATH[0]).convert_alpha(), pygame.image.load(PLAYER_PATH[1]).convert_alpha(), pygame.image.load(PLAYER_PATH[2]).convert_alpha(), ) # select random pipe sprites IMAGES['pipe'] = ( pygame.transform.rotate( pygame.image.load(PIPE_PATH).convert_alpha(), 180), pygame.image.load(PIPE_PATH).convert_alpha(), ) # hismask for pipes HITMASKS['pipe'] = ( getHitmask(IMAGES['pipe'][0]), getHitmask(IMAGES['pipe'][1]), ) # hitmask for player HITMASKS['player'] = ( getHitmask(IMAGES['player'][0]), getHitmask(IMAGES['player'][1]), getHitmask(IMAGES['player'][2]), ) return IMAGES, SOUNDS, HITMASKS def getHitmask(image): """returns a hitmask using an image's alpha.""" mask = [] for x in range(image.get_width()): mask.append([]) for y in range(image.get_height()): mask[x].append(bool(image.get_at((x,y))[3])) return mask # BrainDQN_NIPS.py import tensorflow as tf import numpy as np import random from collections import deque # Hyper Parameters: FRAME_PER_ACTION = 1 GAMMA = 0.99 # decay rate of past observations OBSERVE = 100. # timesteps to observe before training EXPLORE = 150000. # frames over which to anneal epsilon FINAL_EPSILON = 0.0 # final value of epsilon INITIAL_EPSILON = 0.9 # starting value of epsilon REPLAY_MEMORY = 50000 # number of previous transitions to remember BATCH_SIZE = 32 # size of minibatch class BrainDQN: def __init__(self,actions): # init replay memory self.replayMemory = deque() # init some parameters self.timeStep = 0 self.epsilon = INITIAL_EPSILON self.actions = actions # init Q network self.createQNetwork() def createQNetwork(self): # network weights W_conv1 = self.weight_variable([8,8,4,32]) b_conv1 = self.bias_variable([32]) W_conv2 = self.weight_variable([4,4,32,64]) b_conv2 = self.bias_variable([64]) W_conv3 = self.weight_variable([3,3,64,64]) b_conv3 = self.bias_variable([64]) W_fc1 = self.weight_variable([1600,512]) b_fc1 = self.bias_variable([512]) W_fc2 = self.weight_variable([512,self.actions]) b_fc2 = self.bias_variable([self.actions]) # input layer self.stateInput = tf.placeholder("float",[None,80,80,4]) # hidden layers h_conv1 = tf.nn.relu(self.conv2d(self.stateInput,W_conv1,4) + b_conv1) h_pool1 = self.max_pool_2x2(h_conv1) h_conv2 = tf.nn.relu(self.conv2d(h_pool1,W_conv2,2) + b_conv2) h_conv3 = tf.nn.relu(self.conv2d(h_conv2,W_conv3,1) + b_conv3) h_conv3_flat = tf.reshape(h_conv3,[-1,1600]) h_fc1 = tf.nn.relu(tf.matmul(h_conv3_flat,W_fc1) + b_fc1) # Q Value layer self.QValue = tf.matmul(h_fc1,W_fc2) + b_fc2 self.actionInput = tf.placeholder("float",[None,self.actions]) self.yInput = tf.placeholder("float", [None]) Q_action = tf.reduce_sum(tf.mul(self.QValue, self.actionInput), reduction_indices = 1) self.cost = tf.reduce_mean(tf.square(self.yInput - Q_action)) self.trainStep = tf.train.AdamOptimizer(1e-6).minimize(self.cost) # saving and loading networks self.saver = tf.train.Saver() self.session = tf.InteractiveSession() self.session.run(tf.initialize_all_variables()) checkpoint = tf.train.get_checkpoint_state("saved_networks") if checkpoint and checkpoint.model_checkpoint_path: self.saver.restore(self.session, checkpoint.model_checkpoint_path) print ("Successfully loaded:", checkpoint.model_checkpoint_path) else: print ("Could not find old network weights") def trainQNetwork(self): # Step 1: obtain random minibatch from replay memory minibatch = random.sample(self.replayMemory,BATCH_SIZE) state_batch = [data[0] for data in minibatch] action_batch = [data[1] for data in minibatch] reward_batch = [data[2] for data in minibatch] nextState_batch = [data[3] for data in minibatch] # Step 2: calculate y y_batch = [] QValue_batch = self.QValue.eval(feed_dict={self.stateInput:nextState_batch}) for i in range(0,BATCH_SIZE): terminal = minibatch[i][4] if terminal: y_batch.append(reward_batch[i]) else: y_batch.append(reward_batch[i] + GAMMA * np.max(QValue_batch[i])) self.trainStep.run(feed_dict={ self.yInput : y_batch, self.actionInput : action_batch, self.stateInput : state_batch }) # save network every 100000 iteration if self.timeStep % 10000 == 0: self.saver.save(self.session, 'saved_networks/' + 'network' + '-dqn', global_step = self.timeStep) def setPerception(self,nextObservation,action,reward,terminal): #newState = np.append(nextObservation,self.currentState[:,:,1:],axis = 2) newState = np.append(self.currentState[:,:,1:],nextObservation,axis = 2) self.replayMemory.append((self.currentState,action,reward,newState,terminal)) if len(self.replayMemory) > REPLAY_MEMORY: self.replayMemory.popleft() if self.timeStep > OBSERVE: # Train the network self.trainQNetwork() self.currentState = newState self.timeStep += 1 def getAction(self): QValue = self.QValue.eval(feed_dict= {self.stateInput:[self.currentState]})[0] action = np.zeros(self.actions) action_index = 0 if self.timeStep % FRAME_PER_ACTION == 0: if random.random() <= self.epsilon: action_index = random.randrange(self.actions) action[action_index] = 1 else: action_index = np.argmax(QValue) action[action_index] = 1 else: action[0] = 1 # do nothing # change episilon if self.epsilon > FINAL_EPSILON and self.timeStep > OBSERVE: self.epsilon -= (INITIAL_EPSILON - FINAL_EPSILON)/EXPLORE return action def setInitState(self,observation): self.currentState = np.stack((observation, observation, observation, observation), axis = 2) def weight_variable(self,shape): initial = tf.truncated_normal(shape, stddev = 0.01) return tf.Variable(initial) def bias_variable(self,shape): initial = tf.constant(0.01, shape = shape) return tf.Variable(initial) def conv2d(self,x, W, stride): return tf.nn.conv2d(x, W, strides = [1, stride, stride, 1], padding = "SAME") def max_pool_2x2(self,x): return tf.nn.max_pool(x, ksize = [1, 2, 2, 1], strides = [1, 2, 2, 1], padding = "SAME") # BrainDQN_Nature.py import tensorflow as tf import numpy as np import random from collections import deque # Hyper Parameters: FRAME_PER_ACTION = 1 GAMMA = 0.99 # decay rate of past observations OBSERVE = 100. # timesteps to observe before training EXPLORE = 200000. # frames over which to anneal epsilon FINAL_EPSILON = 0#0.001 # final value of epsilon INITIAL_EPSILON = 0#0.01 # starting value of epsilon REPLAY_MEMORY = 50000 # number of previous transitions to remember BATCH_SIZE = 32 # size of minibatch UPDATE_TIME = 100 try: tf.mul except: # For new version of tensorflow # tf.mul has been removed in new version of tensorflow # Using tf.multiply to replace tf.mul tf.mul = tf.multiply class BrainDQN: def __init__(self,actions): # init replay memory self.replayMemory = deque() # init some parameters self.timeStep = 0 self.epsilon = INITIAL_EPSILON self.actions = actions # init Q network self.stateInput,self.QValue,self.W_conv1,self.b_conv1,self.W_conv2,self.b_conv2,self.W_conv3,self.b_conv3,self.W_fc1,self.b_fc1,self.W_fc2,self.b_fc2 = self.createQNetwork() # init Target Q Network self.stateInputT,self.QValueT,self.W_conv1T,self.b_conv1T,self.W_conv2T,self.b_conv2T,self.W_conv3T,self.b_conv3T,self.W_fc1T,self.b_fc1T,self.W_fc2T,self.b_fc2T = self.createQNetwork() self.copyTargetQNetworkOperation = [self.W_conv1T.assign(self.W_conv1),self.b_conv1T.assign(self.b_conv1),self.W_conv2T.assign(self.W_conv2),self.b_conv2T.assign(self.b_conv2),self.W_conv3T.assign(self.W_conv3),self.b_conv3T.assign(self.b_conv3),self.W_fc1T.assign(self.W_fc1),self.b_fc1T.assign(self.b_fc1),self.W_fc2T.assign(self.W_fc2),self.b_fc2T.assign(self.b_fc2)] self.createTrainingMethod() # saving and loading networks self.saver = tf.train.Saver() self.session = tf.InteractiveSession() self.session.run(tf.initialize_all_variables()) checkpoint = tf.train.get_checkpoint_state("saved_networks") if checkpoint and checkpoint.model_checkpoint_path: self.saver.restore(self.session, checkpoint.model_checkpoint_path) print ("Successfully loaded:", checkpoint.model_checkpoint_path) else: print ("Could not find old network weights") def createQNetwork(self): # network weights W_conv1 = self.weight_variable([8,8,4,32]) b_conv1 = self.bias_variable([32]) W_conv2 = self.weight_variable([4,4,32,64]) b_conv2 = self.bias_variable([64]) W_conv3 = self.weight_variable([3,3,64,64]) b_conv3 = self.bias_variable([64]) W_fc1 = self.weight_variable([1600,512]) b_fc1 = self.bias_variable([512]) W_fc2 = self.weight_variable([512,self.actions]) b_fc2 = self.bias_variable([self.actions]) # input layer stateInput = tf.placeholder("float",[None,80,80,4]) # hidden layers h_conv1 = tf.nn.relu(self.conv2d(stateInput,W_conv1,4) + b_conv1) h_pool1 = self.max_pool_2x2(h_conv1) h_conv2 = tf.nn.relu(self.conv2d(h_pool1,W_conv2,2) + b_conv2) h_conv3 = tf.nn.relu(self.conv2d(h_conv2,W_conv3,1) + b_conv3) h_conv3_flat = tf.reshape(h_conv3,[-1,1600]) h_fc1 = tf.nn.relu(tf.matmul(h_conv3_flat,W_fc1) + b_fc1) # Q Value layer QValue = tf.matmul(h_fc1,W_fc2) + b_fc2 return stateInput,QValue,W_conv1,b_conv1,W_conv2,b_conv2,W_conv3,b_conv3,W_fc1,b_fc1,W_fc2,b_fc2 def copyTargetQNetwork(self): self.session.run(self.copyTargetQNetworkOperation) def createTrainingMethod(self): self.actionInput = tf.placeholder("float",[None,self.actions]) self.yInput = tf.placeholder("float", [None]) Q_Action = tf.reduce_sum(tf.mul(self.QValue, self.actionInput), reduction_indices = 1) self.cost = tf.reduce_mean(tf.square(self.yInput - Q_Action)) self.trainStep = tf.train.AdamOptimizer(1e-6).minimize(self.cost) def trainQNetwork(self): # Step 1: obtain random minibatch from replay memory minibatch = random.sample(self.replayMemory,BATCH_SIZE) state_batch = [data[0] for data in minibatch] action_batch = [data[1] for data in minibatch] reward_batch = [data[2] for data in minibatch] nextState_batch = [data[3] for data in minibatch] # Step 2: calculate y y_batch = [] QValue_batch = self.QValueT.eval(feed_dict={self.stateInputT:nextState_batch}) for i in range(0,BATCH_SIZE): terminal = minibatch[i][4] if terminal: y_batch.append(reward_batch[i]) else: y_batch.append(reward_batch[i] + GAMMA * np.max(QValue_batch[i])) self.trainStep.run(feed_dict={ self.yInput : y_batch, self.actionInput : action_batch, self.stateInput : state_batch }) # save network every 100000 iteration if self.timeStep % 10000 == 0: self.saver.save(self.session, 'saved_networks/' + 'network' + '-dqn', global_step = self.timeStep) if self.timeStep % UPDATE_TIME == 0: self.copyTargetQNetwork() def setPerception(self,nextObservation,action,reward,terminal): #newState = np.append(nextObservation,self.currentState[:,:,1:],axis = 2) newState = np.append(self.currentState[:,:,1:],nextObservation,axis = 2) self.replayMemory.append((self.currentState,action,reward,newState,terminal)) if len(self.replayMemory) > REPLAY_MEMORY: self.replayMemory.popleft() if self.timeStep > OBSERVE: # Train the network self.trainQNetwork() # print info state = "" if self.timeStep <= OBSERVE: state = "observe" elif self.timeStep > OBSERVE and self.timeStep <= OBSERVE + EXPLORE: state = "explore" else: state = "train" print ("TIMESTEP", self.timeStep, "/ STATE", state, \ "/ EPSILON", self.epsilon) self.currentState = newState self.timeStep += 1 def getAction(self): QValue = self.QValue.eval(feed_dict= {self.stateInput:[self.currentState]})[0] action = np.zeros(self.actions) action_index = 0 if self.timeStep % FRAME_PER_ACTION == 0: if random.random() <= self.epsilon: action_index = random.randrange(self.actions) action[action_index] = 1 else: action_index = np.argmax(QValue) action[action_index] = 1 else: action[0] = 1 # do nothing # change episilon if self.epsilon > FINAL_EPSILON and self.timeStep > OBSERVE: self.epsilon -= (INITIAL_EPSILON - FINAL_EPSILON)/EXPLORE return action def setInitState(self,observation): self.currentState = np.stack((observation, observation, observation, observation), axis = 2) def weight_variable(self,shape): initial = tf.truncated_normal(shape, stddev = 0.01) return tf.Variable(initial) def bias_variable(self,shape): initial = tf.constant(0.01, shape = shape) return tf.Variable(initial) def conv2d(self,x, W, stride): return tf.nn.conv2d(x, W, strides = [1, stride, stride, 1], padding = "SAME") def max_pool_2x2(self,x): return tf.nn.max_pool(x, ksize = [1, 2, 2, 1], strides = [1, 2, 2, 1], padding = "SAME") #FlappyBirdDQN.py import cv2 import sys sys.path.append("game/") import wrapped_flappy_bird as game from BrainDQN_Nature import BrainDQN import numpy as np # preprocess raw image to 80*80 gray image def preprocess(observation): observation = cv2.cvtColor(cv2.resize(observation, (80, 80)), cv2.COLOR_BGR2GRAY) ret, observation = cv2.threshold(observation,1,255,cv2.THRESH_BINARY) return np.reshape(observation,(80,80,1)) def playFlappyBird(): # Step 1: init BrainDQN actions = 2 brain = BrainDQN(actions) # Step 2: init Flappy Bird Game flappyBird = game.GameState() # Step 3: play game # Step 3.1: obtain init state action0 = np.array([1,0]) # do nothing observation0, reward0, terminal = flappyBird.frame_step(action0) observation0 = cv2.cvtColor(cv2.resize(observation0, (80, 80)), cv2.COLOR_BGR2GRAY) ret, observation0 = cv2.threshold(observation0,1,255,cv2.THRESH_BINARY) brain.setInitState(observation0) # Step 3.2: run the game while 1!= 0: action = brain.getAction() nextObservation,reward,terminal = flappyBird.frame_step(action) nextObservation = preprocess(nextObservation) brain.setPerception(nextObservation,action,reward,terminal) def main(): playFlappyBird() if __name__ == '__main__': main()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号