使用keras完成语音识别
使用案例,训练两个类型的语音,然后测试,对CPU和内存要求不高。内存使用在 1G 左右
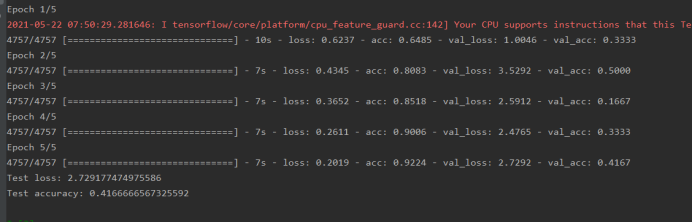
import wave import matplotlib.pyplot as plt import numpy as np import os import keras from keras.models import Sequential from keras.layers import Dense # 加载数据集 和 标签[并返回标签集的处理结果] def create_datasets(): wavs=[] labels=[] # labels 和 testlabels 这里面存的值都是对应标签的下标,下标对应的名字在labsInd中 testwavs=[] testlabels=[] labsInd=[] ## 训练集标签的名字 0:seven 1:stop testlabsInd=[] ## 测试集标签的名字 0:seven 1:stop path="E:/PycharmProjects/TensorFlow/实验/实验19-使用keras完成语音识别/wav/seven/" files = os.listdir(path) for i in files: # print(i) waveData = get_wav_mfcc(path+i) # print(waveData) wavs.append(waveData) if ("seven" in labsInd)==False: labsInd.append("seven") labels.append(labsInd.index("seven")) path="E:/PycharmProjects/TensorFlow/实验/实验19-使用keras完成语音识别/wav/stop/" files = os.listdir(path) for i in files: # print(i) waveData = get_wav_mfcc(path+i) wavs.append(waveData) if ("stop" in labsInd)==False: labsInd.append("stop") labels.append(labsInd.index("stop")) # 现在为了测试方便和快速直接写死,后面需要改成自动扫描文件夹和标签的形式 path="E:/PycharmProjects/TensorFlow/实验/实验19-使用keras完成语音识别/wav/test1/" files = os.listdir(path) for i in files: # print(i) waveData = get_wav_mfcc(path+i) testwavs.append(waveData) if ("seven" in testlabsInd)==False: testlabsInd.append("seven") testlabels.append(testlabsInd.index("seven")) path="E:/PycharmProjects/TensorFlow/实验/实验19-使用keras完成语音识别/wav/test2/" files = os.listdir(path) for i in files: # print(i) waveData = get_wav_mfcc(path+i) testwavs.append(waveData) if ("stop" in testlabsInd)==False: testlabsInd.append("stop") testlabels.append(testlabsInd.index("stop")) wavs=np.array(wavs) labels=np.array(labels) testwavs=np.array(testwavs) testlabels=np.array(testlabels) return (wavs,labels),(testwavs,testlabels),(labsInd,testlabsInd) def get_wav_mfcc(wav_path): f = wave.open(wav_path,'rb') params = f.getparams() # print("params:",params) nchannels, sampwidth, framerate, nframes = params[:4] strData = f.readframes(nframes)#读取音频,字符串格式 waveData = np.fromstring(strData,dtype=np.int16)#将字符串转化为int waveData = waveData*1.0/(max(abs(waveData)))#wave幅值归一化 waveData = np.reshape(waveData,[nframes,nchannels]).T f.close() # print(waveData) # plt.rcParams['savefig.dpi'] = 300 #图片像素 # plt.rcParams['figure.dpi'] = 300 #分辨率 # plt.specgram(waveData[0],Fs = framerate, scale_by_freq = True, sides = 'default') # plt.ylabel('Frequency(Hz)') # plt.xlabel('Time(s)') # plt.title('wa') # plt.show() ### 对音频数据进行长度大小的切割,保证每一个的长度都是一样的【因为训练文件全部是1秒钟长度,16000帧的,所以这里需要把每个语音文件的长度处理成一样的】 data = list(np.array(waveData[0])) # print(len(data)) while len(data)>16000: del data[len(waveData[0])-1] del data[0] # print(len(data)) while len(data)<16000: data.append(0) # print(len(data)) data=np.array(data) # 平方之后,开平方,取正数,值的范围在 0-1 之间 data = data ** 2 data = data ** 0.5 return data if __name__ == '__main__': (wavs,labels),(testwavs,testlabels),(labsInd,testlabsInd) = create_datasets() print(wavs.shape," ",labels.shape) print(testwavs.shape," ",testlabels.shape) print(labsInd," ",testlabsInd) # 标签转换为独热码 labels = keras.utils.to_categorical(labels, 2) testlabels = keras.utils.to_categorical(testlabels, 2) print(labels[0]) ## 类似 [1. 0] print(testlabels[0]) ## 类似 [0. 0] print(wavs.shape," ",labels.shape) print(testwavs.shape," ",testlabels.shape) # 构建模型 model = Sequential() model.add(Dense(512, activation='relu',input_shape=(16000,))) model.add(Dense(256, activation='relu')) model.add(Dense(64, activation='relu')) model.add(Dense(2, activation='softmax')) # [编译模型] 配置模型,损失函数采用交叉熵,优化采用Adadelta,将识别准确率作为模型评估 model.compile(loss=keras.losses.categorical_crossentropy, optimizer=keras.optimizers.Adadelta(), metrics=['accuracy']) # validation_data为验证集 model.fit(wavs, labels, batch_size=124, epochs=5, verbose=1, validation_data=(testwavs, testlabels)) # 开始评估模型效果 # verbose=0为不输出日志信息 score = model.evaluate(testwavs, testlabels, verbose=0) print('Test loss:', score[0]) print('Test accuracy:', score[1]) # 准确度 model.save('asr_model_weights.h5') # 保存训练模型