linux 的一些脑洞操作
把当前文件夹的文件名用","连接成一行,或者将多行转变为一行
ls | paste -s -d "," # -s 选项将输入进行一次性粘贴
ls | xargs | sed 's/ /,/g' #xargs 将输入作为参数(空格分隔)传入
ls | awk '{printf "%s,",$0}'
将行逆序输出
sed '1!G;h;$!d'file # 1!G 第一行不执行G命令,从第二行开始执行;$!d 最后一行不删除;第一行自动存入模式空间,将模式空间内容(第一行)放到保持空间(h),然后删除模式空间内容(d,否则它会自动输出),第二行自动存入模式空间,(开始用G)将保持空间(第一行内容)接到模式空间(第二行)后,将当前模式空间(第二行+第一行)放到保持空间(h),然后删除当前模式空间(d),依次类推,最后一行不删除模式空间,再自动输出模式空间内容
tac file
删除#开头的注释行
sed '/^#.*/d' test.txt
去掉每行开头4个字符
cut -c 4- test.csv
对文件第一列进行统计
awk -F "," '{count[$1]++} END{for (record in count) print record,count[record] }' test.csv #count[$1]++创建关联数组count[$1]并进行计数
对文件第四列用":"切割成两列并将最后一列结果+1,然后输出全部列
awk -F "," '{split($4,array,":");print $1,$2,$3,array[1],array[2]+1}' test.csv #split切割$4存到数组array中,array[1]和arrya[2]即为切割后的两个区域
对文件第二列求均值
awk -F "," '{sum+=$2} END {print "Average = ", sum/NR}' test.csv
实现DNA序列反向互补
cat seq.txt | sed 'y/ATGC/TACG/' |rev
某一行插入另外一个文件的内容
sed '2 r a.txt' test.csv
对一个文件按照第一列进行筛选,筛选条件是必须在另外一个文件的第一列出现过
awk -F "," '{if(NR==FNR){count[$1]=1}else if(count[$1]==1){print $0}}' chr.txt test.csv #将第一个文件第一列的值存入关联数组,并给值为1,如果第二个文件建立的关联数组对应值为1,说明在第一个文件第一列出现过,则输出整行
对文件第二列和第三列进行展开
展开前四列

展开后成为三列

awk -F "," '{for (i=$2;i<=$3;i++) {print $1,i,$4}}' test.csv
对三个文件依次merge
这里三个文件行数相等,其中ampl列将新的和旧的染色体、位置联系起来,第一个文件将第五列(ampl列,值为ampl1,ampl2...)存入一二三列(旧染色体,旧起始位置,旧结束位置)为下标的关联数组ampl,第二个文件按照一二三列(旧染色体,旧起始位置,旧结束位置)取出关联数组的值(ampl1,ampl2...),将关联数组的值作为关联数组下标新创建关联数组Ampl,将第二个文件的值(1,2,3,4,5列,其中4、5列是我们要的信息)用sprintf生成字符串存入Ampl,第三文件按照第四列(ampl1,ampl2...),用split切割sprintf生成的字符串,取出第二个文件存入的值(这里只取出了需要的4,5列,123列的值输出第三个文件的123列(新染色体,新起始位置,新结束位置)的值)。这样Oldpanel_start_end.sort.bed 对应的旧的染色体和位置,被hg38amplicon_start_end.bed新的一个染色体和位置取代,并且将旧文件染色体和位置在amplGChg19.txt 对应的信息成功转移到新生成的新位置文件中
awk 'BEGIN{FS="\t";OFS="\t"}{if(NR==FNR){ampl[$1,$2,$3]=$5;N=NR}else if(NR<=2*N){Ampl[ampl[$1,$2,$3]]=sprintf("%s,%d,%d,%s,%s",$1,$2,$3,$4,$5);}else{split(Ampl[$4],array,",");print $1,$2,$3,array[4],array[5],$4}}' Oldpanel_start_end.sort.bed amplGChg19.txt hg38amplicon_start_end.bed | sort -k1 > hg38amplicon_Gene_GC.txt
对两个文件去重取并集
cat NewpanelGene.bed Oldpanel.gene.bed | sort -u > merge.gene.bed #sort -u = sort | uniq ,相当于sort 之后,将重复相邻行变成只有一行
对文件按照标志开头的行进行分割
比如
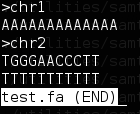
awk '/>chr/{split($0,array,">");out=array[2]};{print > out}' test.fa
输出chr1,chr2两个文件
输出文件奇数行和偶数行
sed -n 'p;n' test.txt #输出奇数行
sed -n 'n;p' test.txt #输出偶数行
统计GC含量
echo "TTCCTTGAAATAAGTGTGATT" | awk '{s=gsub("[GC]","N",$0);print s/length}'
去除windows换行符
cat test.txt | sed 's/\r//g'

 浙公网安备 33010602011771号
浙公网安备 33010602011771号