
第一次个人编程作业
一、github链接
二、计算模块接口的设计与实现过程
- 流程图
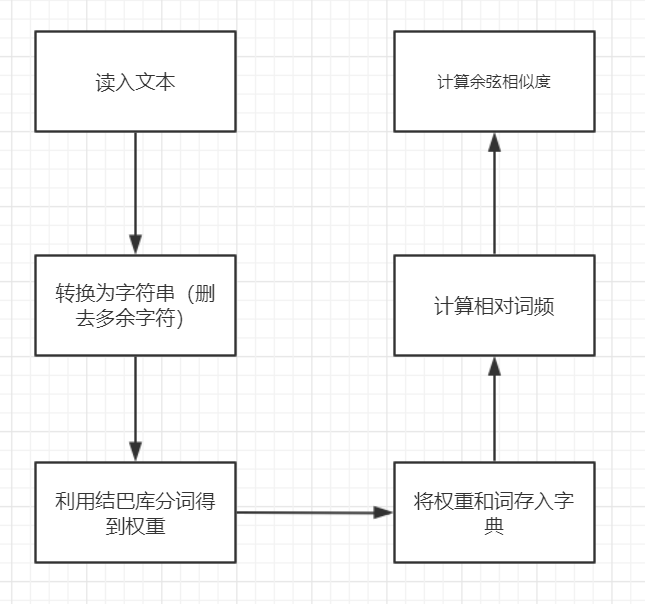
- 算法介绍
对于菜鸡的我,选择面向百度编程。在百度的建议下,我选择用余弦相似度算法求论文重复率。这里丢下参考的链接:
- 模块介绍
python库:
-
jieba.analyse:用于分词并返回权重
-
sys:调用命令行输入参数
-
math:开根号
-
整体用一个Document类实现
-
类的构造函数
def __init__(self, f1_, f2_, topK):
self.f1 = f1_
self.f2 = f2_
self.topK = topK
self.vector1 = {}
self.vector2 = {}
- 去除多余符号
def delsim(self):
str_ = [',', '。', '《', '》', ':', '\n', '、', '“', '”', '?', '—', ' ']
for i in str_:
self.f1 = self.f1.replace(i, '')
self.f2 = self.f2.replace(i, '')
- 构建字典存储向量
def vector(self):
cut1 = jieba.analyse.extract_tags(f1, topK=K, withWeight=True)
cut2 = jieba.analyse.extract_tags(f2, topK=K, withWeight=True)
# 构建向量
for i, j in cut1:
self.vector1[i] = j
for i, j in cut2:
self.vector2[i] = j
# 将两个文本中没有的关键词填充0
for key in self.vector1:
self.vector2[key] = self.vector2.get(key, 0)
for key in self.vector2:
self.vector1[key] = self.vector1.get(key, 0)
# 计算相对词频
def level(vdict_):
_min = min(vdict_.values())
_max = max(vdict_.values())
_mid = _max - _min
for key_ in vdict_:
vdict_[key_] = (vdict_[key_] - _min) / _mid
return vdict_
self.vector1 = level(self.vector1)
self.vector2 = level(self.vector2)
- 计算向量余弦值
def similar(self):
self.vector()
self.delsim()
sum_ = 0
for key in self.vector1:
sum_ += self.vector1[key] * self.vector2[key]
a = sqrt(reduce(lambda x, y: x + y, map(lambda x: x * x, self.vector1.values())))
b = sqrt(reduce(lambda x, y: x + y, map(lambda x: x * x, self.vector2.values())))
return sum_ / (a * b)
- 最后是主函数读入文件并得到结果
if __name__ == '__main__':
orifile = sys.argv[1]
copyfile = sys.argv[2]
ansfile = sys.argv[3]
# 读入文件
try:
with open(orifile, encoding='utf-8') as file1:
f1 = file1.read()
with open(copyfile, encoding='utf-8') as file2:
f2 = file2.read()
except:
print('路径有错')
K = int(len(f1) * 0.8)
s = Document(f1, f2, K)
sim = round(s.similar(), 2)
# 输出文件
try:
with open(ansfile, 'w+', encoding='utf-8') as file3:
file3.write(str(sim))
except:
print('路径有错')
s.similar()
三、计算模块接口部分的性能改进
- 这里放上pycharm自带profile跑的图,截不全还很小将就着看了
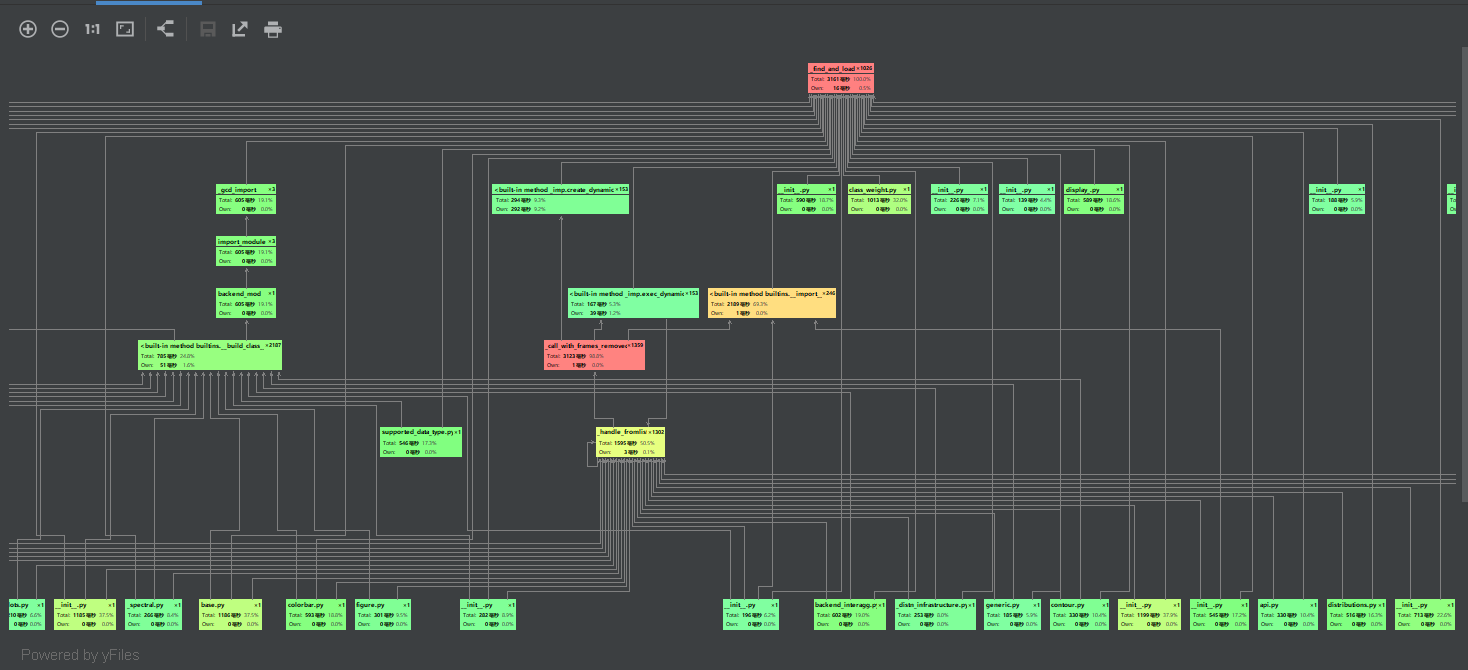
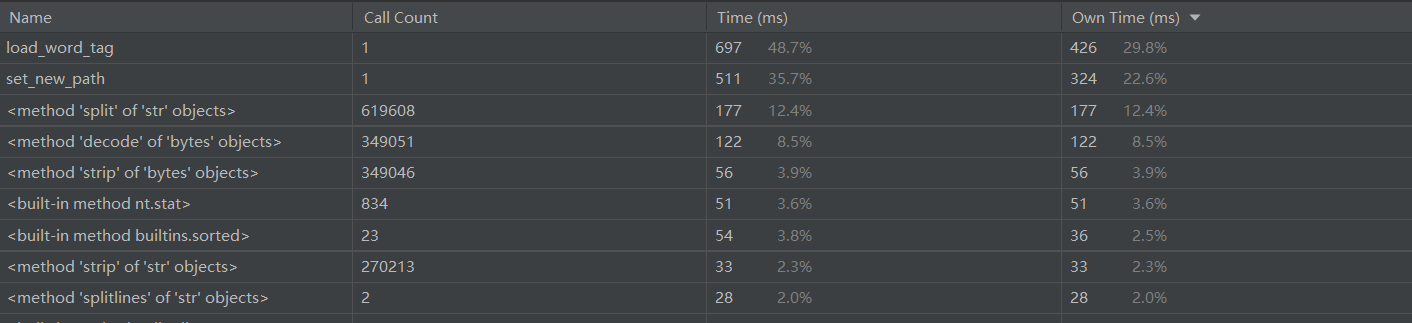
- 总耗时还是符合要求的

- 至于优化,
能做出来就不错了需要更好的分词法,因为不能调用停用词表所以也不知道咋搞了
四、计算模块部分单元测试展示
-
看了大佬们的博客自己照猫画虎也写了个测试样例,因为跑出来已经很艰难了,所以只测试了给的样例文件
还是太菜了
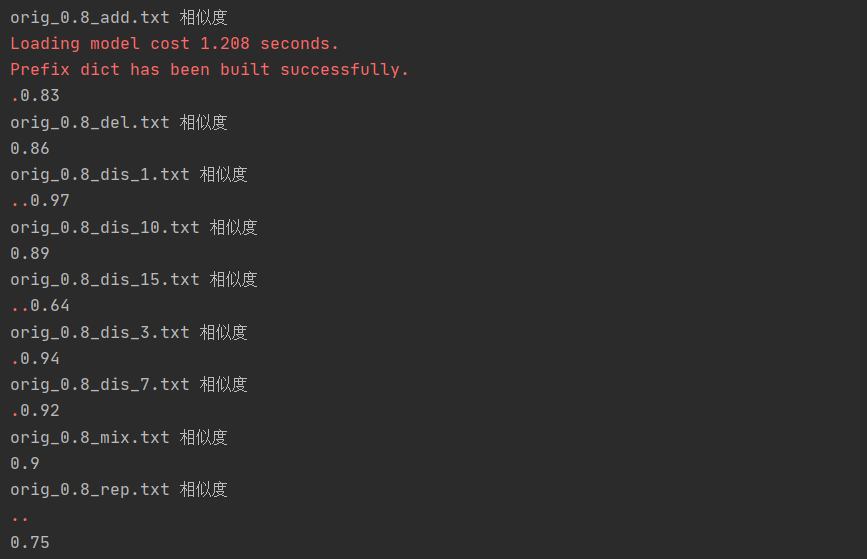
-
小红点不知道是什么情况导致的,处理不了。。 跑出来的结果大部分还是符合预期,但是对于dis乱序的我的算法就没法求精确的重复率了
-
测试单元代码
import unittest
import project
class MyTest(unittest.TestCase):
def test_add(self):
print("orig_0.8_add.txt 相似度")
with open("orig.txt", "r", encoding='utf-8') as fp:
orig_text = fp.read()
with open("orig_0.8_add.txt", "r", encoding='utf-8') as fp:
copy_text = fp.read()
similarity = project.Document(orig_text, copy_text)
similarity = round(similarity.similar(), 2)
print(similarity)
def test_del(self):
print("orig_0.8_del.txt 相似度")
with open("orig.txt", "r", encoding='utf-8') as fp:
orig_text = fp.read()
with open("orig_0.8_del.txt", "r", encoding='utf-8') as fp:
copy_text = fp.read()
similarity = project.Document(orig_text, copy_text)
similarity = round(similarity.similar(), 2)
print(similarity)
def test_dis_1(self):
print("orig_0.8_dis_1.txt 相似度")
with open("orig.txt", "r", encoding='utf-8') as fp:
orig_text = fp.read()
with open("orig_0.8_dis_1.txt", "r", encoding='utf-8') as fp:
copy_text = fp.read()
similarity = project.Document(orig_text, copy_text)
similarity = round(similarity.similar(), 2)
print(similarity)
def test_dis_3(self):
print("orig_0.8_dis_3.txt 相似度")
with open("orig.txt", "r", encoding='utf-8') as fp:
orig_text = fp.read()
with open("orig_0.8_dis_3.txt", "r", encoding='utf-8') as fp:
copy_text = fp.read()
similarity = project.Document(orig_text, copy_text)
similarity = round(similarity.similar(), 2)
print(similarity)
def test_dis_7(self):
print("orig_0.8_dis_7.txt 相似度")
with open("orig.txt", "r", encoding='utf-8') as fp:
orig_text = fp.read()
with open("orig_0.8_dis_7.txt", "r", encoding='utf-8') as fp:
copy_text = fp.read()
similarity = project.Document(orig_text, copy_text)
similarity = round(similarity.similar(), 2)
print(similarity)
def test_dis_10(self):
print("orig_0.8_dis_10.txt 相似度")
with open("orig.txt", "r", encoding='utf-8') as fp:
orig_text = fp.read()
with open("orig_0.8_dis_10.txt", "r", encoding='utf-8') as fp:
copy_text = fp.read()
similarity = project.Document(orig_text, copy_text)
similarity = round(similarity.similar(), 2)
print(similarity)
def test_dis_15(self):
print("orig_0.8_dis_15.txt 相似度")
with open("orig.txt", "r", encoding='utf-8') as fp:
orig_text = fp.read()
with open("orig_0.8_dis_15.txt", "r", encoding='utf-8') as fp:
copy_text = fp.read()
similarity = project.Document(orig_text, copy_text)
similarity = round(similarity.similar(), 2)
print(similarity)
def test_mix(self):
print("orig_0.8_mix.txt 相似度")
with open("orig.txt", "r", encoding='utf-8') as fp:
orig_text = fp.read()
with open("orig_0.8_mix.txt", "r", encoding='utf-8') as fp:
copy_text = fp.read()
similarity = project.Document(orig_text, copy_text)
similarity = round(similarity.similar(), 2)
print(similarity)
def test_rep(self):
print("orig_0.8_rep.txt 相似度")
with open("orig.txt", "r", encoding='utf-8') as fp:
orig_text = fp.read()
with open("orig_0.8_rep.txt", "r", encoding='utf-8') as fp:
copy_text = fp.read()
similarity = project.Document(orig_text, copy_text)
similarity = round(similarity.similar(), 2)
print(similarity)
if __name__ == '__main__':
unittest.main()
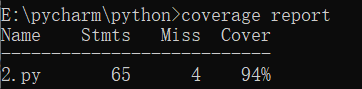
- 代码单元测试覆盖率
五、计算模块部分异常处理说明
- 空文本测试异常
对输入两篇空文本,求得的向量为零向量就会导致除零异常,所以要进行异常处理
try:
# 余弦值求解
# 如果无异常 返回所求的余弦值
except Exception as e:
print(e) # 异常类型
return 0.0 # 对于零向量 余弦值为0
六、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 30 |
| · Estimate | · 估计这个任务需要多少时间 | 40 | 50 |
| Development | 开发 | 180 | 240 |
| · Analysis | · 需求分析 (包括学习新技术) | 420 | 500 |
| · Design Spec | · 生成设计文档 | 30 | 30 |
| · Design Review | · 设计复审 | 20 | 30 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 15 | 20 |
| · Design | · 具体设计 | 30 | 50 |
| · Coding | · 具体编码 | 180 | 240 |
| · Code Review | · 代码复审 | 30 | 30 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 60 | 80 |
| Reporting | 报告 | 30 | 40 |
| · Test Repor | · 测试报告 | 20 | 30 |
| · Size Measurement | · 计算工作量 | 10 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 30 |
| · 合计 | 1125 | 1410 |
七、总结
- 当我从老师口中得知我们学这门课是痛苦的时候我没想到,是这么痛苦
还是太年轻了。而当我第一次看到编程题的时候,其实我是,是拒绝的果然
像老师说的,
要站在巨人的肩膀上抄代码要站在巨人的肩膀上学习。在大佬和百度的帮忙下才走出了第一步,真的难。 - 不过最让我没想到的是github的使用和各种代码测试分析的麻烦,自己还是太菜了,希望之后能够熟悉流程。
- 对于这次的作业确实做的不令人满意,许多方面没有做好,但是能走出第一步至少是个开始而不是直接选择放弃,接下去的作业我会选择付出更多时间的。
博客做的很平淡,将就着看吧

