
Hadoop及其三大组件原理
Hadoop是什么?
由Apache基金会开发的分布式系统基础架构
海量数据的存储和分析计算
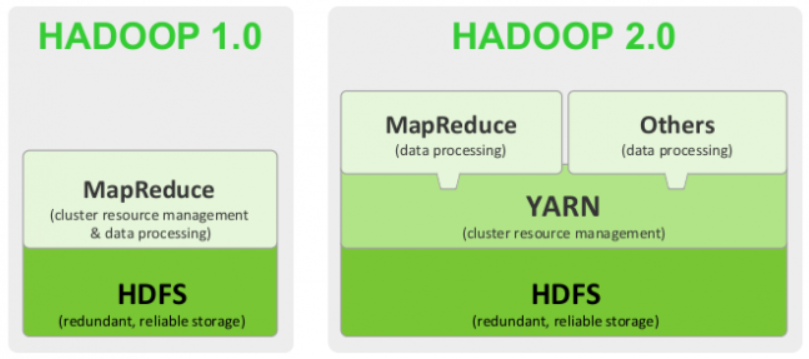
Hadoop架构历史:
1.0 HDFS和MapReduce
2.0 在1.0基础上增加了YARN(任务调度),解放了MapReduce
3.0 和2.0类似,着重优化
Hadoop优势:
1)高可靠性 多数据副本
2)高扩展性 动态扩展,动态删除(有案例)
3)高效性:并行工作,加快任务处理速度
3)高容错性:自动将失败的任务重新分配
Hadoop的三大组件:
A.HDFS:
分布式文件系统(存储海量非结构化数据)
1)通用分布式文件系统,可挂载,但性能差,代表lustre.MooseFS
2)专用分布式文件系统,基本都是GFS思想,上传后不能修改,不能挂载,需要专有的API对文件进行访问,代表:GFS(谷歌),HDFS,TFS(淘宝开源)
B.组成:
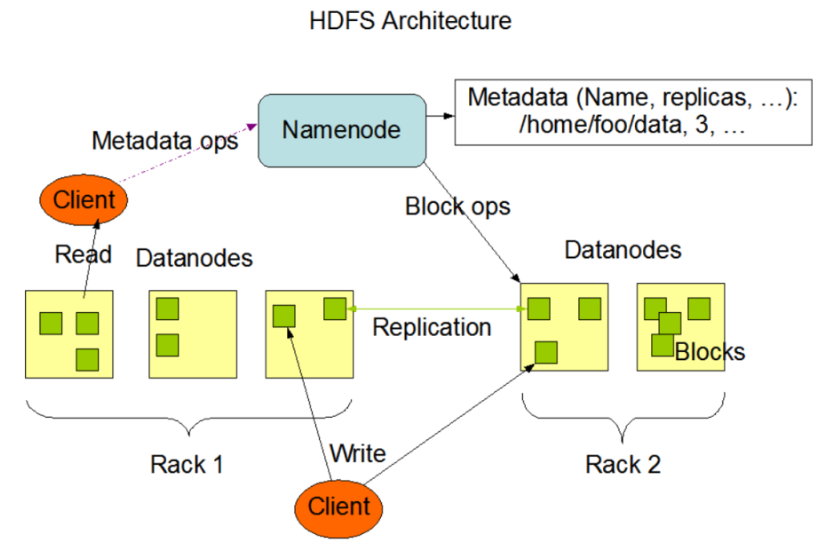
NameNode NN:
Master主管 记录文件存放的位置(元数据)
设置副本策略:文件有几个副本 A文件:1个 B文件:2个
处理客户端的读写请求,客户端和NN进行应答
DateNode DN : 具体存储数据
Slaver,执行实际操作,存储数据,执行数据块的读写
Hadoop HDFS DN工作机制:
DN主动向NN报道,汇报自己的块信息,这就是为什么fsimage里面没有记录快信息的原因。
DN与NN之间时刻保持通信,每隔一个小时,DN向NN上报块信息。
当NN发现某个DN迟迟未上报自己的块信息,
那NN会自己去做副本的配置找一台机器去复制出一份副本来。
但是一个小时的汇报很慢,所以,DN还需要每隔3s找NN说一次话(心跳),告诉NN我还是活着的。
在这次心跳中,NN会顺带着给DN一些指令要做的事情。
Secondary NameNode(2NN):每隔一段时间对NN元数据进行备份 SN,辅助恢复NN,非NN的热备
2NN要做的事情:
1、存数据
2、汇报快信息
3、发送心跳信息
4、接收nn的指令,来处理事情
假设某个DN在三秒内没有和NN去发生心跳,NN会再等等,容忍一下,如果等了十分钟又加三十秒,NN会认为DN已经光荣牺牲了。就会把这个DN剔除该集群。
Client:客户端:
1)文件切分
2)与NN交互,获取文件位置信息
3)与DN交互,读取或写入数据
4)通过命令管理HDFS,比如NN格式化,对HDFS增删改查
场景:适合一次写入,多次读出。一个文件经过创建,写入和关闭之后就不需要改变
C.原理:
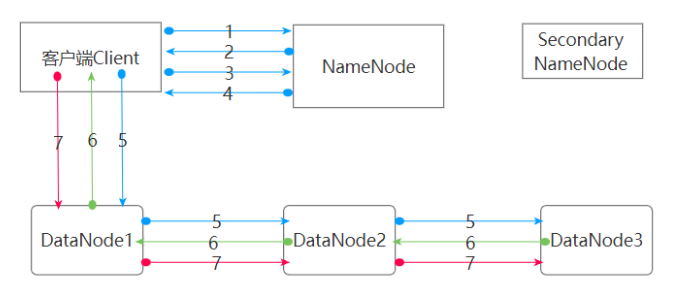
写数据流程
1.文件A 请求上传
2.NN对文件A进行校验,权限,并响应
3.上传第一个Block,请求返回DN
4.NN根据策略(节点距离,负载)返回DN的节点,表示来存储数据
5.建立Block传输通道,请求通道(为什么不是同时到DN1,DN2,DN3,为了数据的可靠,也避免客户端连接所有的DN,减少IO)
6.应答成功
7.传输数据 Packet(最小64K) 边写边传=》边吃边拉
读数据流程:串行读数据
1.请求下载文件A
2.NN判断权限,是否有该文件-》返回元数据
3.创建流,去读取数据,选择节点距离最近的读,其次是负载能力
4.传输数据

B.MapReduce:
什么是MapReduce?
是一个分布式运算程序的编程框架,核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发行在一个Hadoop集群上
分为Map和Reduce
Map:分任务
Reduce:计算并汇总结果
和SparkCore(SparkStreaming 实时计算和Flink)计算的区别,MapReduce是离线计算,Spark Core基于内存计算
额外:
离线计算和实时计算是成对出现,主要是在数据处理延迟性上有不同的需求。
处理这两种模式,有流处理和批处理两种概念。
流处理要求更高的实时性,批处理主要在数据处理规模上,典型代表Hadoop MapReduce
实时计算的场景已经是主流,比如商品推荐,主流框架Spark Streaming,Storm,Flink等框架
优点:
1)易于编程,只需完成串行执行的接口,就可以完成一个分布式程序,举例?
2)良好的扩展性:动态增加服务器,解决计算不够的问题
3)高容错性(其中一台机器挂了,可以把上面的计算任务交给另外一个节点运行,不至于失败,这个功能比较牛逼)
4)海量数据的离线处理 TB/PB
缺点:不擅长实时计算,不擅长流式计算,不擅长DAG计算
C.Yarn:
概念:管理集群资源,给任务合理分配资源=》资源调度平台
组成:
ResourceManager
1)监控NodeManager
2)启动ApplicationMaster
3)资源的分配与调度
NodeMager:
1)管理单个节点资源
2)处理来自RM的命令,来自ApplicationMaster的命令
ApplicationMaster:
1)为应用程序申请资源并分配内部的任务
2)任务的监控和容错
4)Contianer:YARN中的资源抽象,封装了很多资源:内存,CPU,磁盘,网络
三者合起来的原理图:
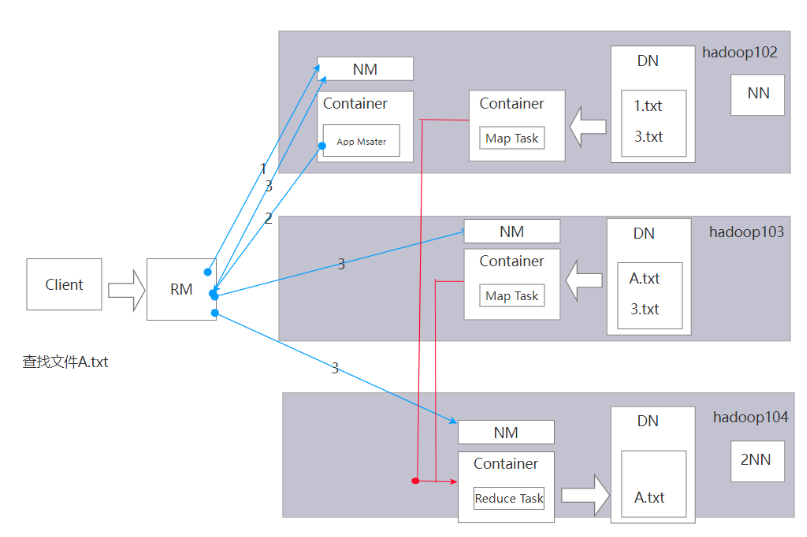
提交任务,RM开启一个节点,然后放置一个任务在节点上,叫做ApplicationMaster
任务向RM申请资源,RM开启了102和103上的资源MapTask,就是MapReduce中的Map阶段.每一个Map独立工作,并把计算的结果写入到HDFS(104),这就是Recude阶段.DataNode负责存储的操作,2NN和NN负责记录
以上,仅用于学习和总结!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号