
Spark SQL数据源
背景
Spark SQL是Spark的一个模块,用于结构化数据的处理。
++++++++++++++ +++++++++++++++++++++
| SQL | | Dataset API |
++++++++++++++ +++++++++++++++++++++
+++++++++++++++++++++++++++++++++++++
| Spark SQL |
+++++++++++++++++++++++++++++++++++++
使用Spark SQL的方式有2种,可以通过SQL或者Dataset API,这两种使用方式在本文都会涉及。
其中,通过SQL接口使用的方法具体又可分为3种:
- 在程序中执行
- 使用命令行
- Jdbc/ODBC
这里只会介绍第一种方式。
Spark关于分布式数据集的抽象原本是RDD,Dataset是其升级版本。DataFrame是特殊的Dataset,它限定元素是按照命名的列来组织的,从这一点看相当于关系型数据库中的表。DataFrame等价于Dataset[Row],而且DataFrame是本文内容的核心。
DataFrame支持丰富的数据源:
+++++++++++++++++++
| 结构数据文件 |
| |
| +++++++++++++ | ++++++++++++++++
| | parquet | | | Hive table |
| +++++++++++++ | ++++++++++++++++
| |
| +++++++++++++ | ++++++++++++++++
| | csv | | | 关系数据库 |
| +++++++++++++ | ++++++++++++++++
| |
| +++++++++++++ | ++++++++++++++++
| | json | | | RDD |
| +++++++++++++ | ++++++++++++++++
| |
+++++++++++++++++++
这里的每一种数据源我们都会进行介绍。
本文主要介绍DataFrame和各数据源的IO操作,后面再写一篇文章介绍基于DataFrame的使用操作。即:本文关注如何得到一个DataFrame,如何将一个DataFrame进行持久化;后面要写的文章则关注如何使用DataFrame。
相关的开源项目demo-spark在github上。
数据源
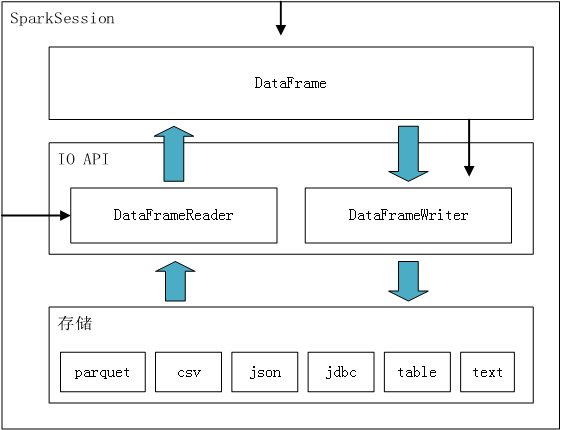
这个图概述了本文介绍的主要内容,它也可以作为后续的备忘和参考。
这个图中包含两种箭头,宽箭头表示数据的流向,细箭头表示提供构造实例的方法。
比如DataFrame - DataFrameWriter - 存储的粗箭头,表示数据从内存通过DataFrameWriter流向存储;SparkSession - DataFrameReader的细箭头,表示可以从SparkSession对象创建DataFrameReader对象。
SparkSession
使用Spark SQL必须先构造SparkSession实例,时候之后需要调用其stop方法释放资源。模板如下:
val spark = org.apache.spark.sql.SparkSession
.builder()
.appName("Spark SQL basic demo")
.master("local")
.getOrCreate()
// work with spark
spark.stop()
下文中出现的所有的spark,如无特殊说明,都是指按照上述代码创建的SparkSession对象。
parquet
parquet文件是怎么样的?
PAR1 "&, @ Alyssa Ben
,
0 red 88,
@ \Hexample.avro.User
% name%
%favorite_color% 5 favorite_numbers %array
<&
% nameDH& &P
5 favorite_color<@&P &?
% (favorite_numbersarray
ZZ&? ?
avro.schema?{"type":"record","name":"User","namespace":"example.avro","fields":[{"name":"name","type":"string"},{"name":"favorite_color","type":["string","null"]},{"name":"favorite_numbers","type":{"type":"array","items":"int"}}]} parquet-mr version 1.4.3 ? PAR1
它不是一个单纯的文本文件,包含了一些无法渲染的特殊字符。
parquet是默认的格式。从一个parquet文件读取数据的代码如下:
val usersDF = spark.read.load("src/main/resources/users.parquet")
spark.read返回DataFrameReader对象,其load方法加载文件中的数据并返回DataFrame对象。这个可以参照上文的闭环图理解。
我们可以调用Dataset#show()方法查看其内容:
usersDF.show()
输出结果:
+------+--------------+----------------+
| name|favorite_color|favorite_numbers|
+------+--------------+----------------+
|Alyssa| null| [3, 9, 15, 20]|
| Ben| red| []|
+------+--------------+----------------+
将一个DataFrame写到parquet文件的代码如下:
usersDF.write.save("output/parquet/")
DataFrame#write()方法返回DataFrameWriter对象实例,save方法将数据持久化为parquet格式的文件。save的参数是一个目录,而且要求最底层的目录是不存在的,下文类同。
另外一种写的方式是:
peopleDF.write.parquet("output/parquet/")
这两种方式的本质相同。
csv
csv是什么样的?
csv又称为逗号分隔符,即:使用逗号分隔一条数据中各字段的值。csv文件可以被excel解析,但是其本质只是一个文本文件。比如下面是一份csv文件的内容:
age,name
,Michael
30,Andy
19,Justin
第一行是表头,但是它和下面的数据并没有什么区别。所以在读取的时候,必须告诉读入器这个文件是有表头的,它(第一行)才会被解析成表头,否则就会被当成数据。
比如,解析表头的读:
spark.read.option("header", true).format("csv").load("output/csv/").show()
其中的option("header", true)就是告诉读入器这个文件是有表头的。
输出为:
+----+-------+
| age| name|
+----+-------+
|null|Michael|
| 30| Andy|
| 19| Justin|
+----+-------+
不解析表头的读:
spark.read.format("csv").load("output/csv/").show()
输出为:
+----+-------+
| _c0| _c1|
+----+-------+
| age| name|
|null|Michael|
| 30| Andy|
| 19| Justin|
+----+-------+
spark自动构建了两个字段:_c0和_c1,而把age和name当成了一行数据。
另外一种简化的读法:
spark.read.option("header", true).csv("output/csv/")
其原理和上文中介绍的其他格式的文件相同。
将DataFrame写入到csv文件时也需要注意表头,将表头也写入文件的方式:
peopleDF.write.option("header", true).format("csv").save("output/csv/")
不写表头,只写数据的方式:
peopleDF.write.format("csv").save("output/csv/")
另外一种简化的写法是:
peopleDF.write.csv("output/csv/")
json
json文件是怎么样的?
上文中说过,DataFrame相当于关系数据库中的表,那么每一条数据相当于一行记录。关系数据库表又可以相当于一个类,每一行数据相当于具体的对象,所以DataFrame的每一条数据相当于一个对象。
DataFrame对要读取的json有特殊的要求:即每一条数据作为一行,整体不能包装成数组。比如:
{"name":"Michael"}
{"name":"Andy", "age":30}
{"name":"Justin", "age":19}
而一个标准的json应该是下面这样:
[{
"name": "Michael"
}, {
"name": "Andy",
"age": 30
}, {
"name": "Justin",
"age": 19
}
]
使用下面的方式读取json文件内容:
val peopleDF = spark.read.format("json").load(path)
这种读取的方式和上文parquet的读取方式一致,最终都是调用load方法。只是多了一段format("json"),这是因为parquet是默认的格式,而json不是,所以必须明确声明。
还有一种简化的方式,其本质还是上述的代码:
val peopleDF = spark.read.json(path)
将一个DataFrame写到json文件的方式:
peopleDF.write.format("json").save("output/json/")
同样的道理,和保存为parquet格式文件相比,这里多了一段format("json")代码。
另外一种简略的写法:
peopleDF.write.json("output/json/")
两者的本质是相同的。
jdbc
spark可以直接通过jdbc读取关系型数据库中指定的表。有两种读取的方式,一种是将所有的参数都作为option一条条设置:
val url = "jdbc:mysql://localhost:3306/vulcanus_ljl?autoReconnect=true&createDatabaseIfNotExist=true&allowMultiQueries=true&zeroDateTimeBehavior=convertToNull&transformedBitIsBoolean=true"
val jdbcDF = spark.read
.format("jdbc")
.option("url", url)
.option("dbtable", "vulcanus_ljl.data_dict")
.option("user", "vulcanus_ljl")
.option("password", "mypassword")
.load()
另一种是预先将参数封装到Properties对象里:
val url = "jdbc:mysql://localhost:3306/vulcanus_ljl?autoReconnect=true&createDatabaseIfNotExist=true&allowMultiQueries=true&zeroDateTimeBehavior=convertToNull&transformedBitIsBoolean=true"
val connectionProperties = new Properties()
connectionProperties.put("user", "vulcanus_ljl")
connectionProperties.put("password", "mypassword")
val jdbcDF2 = spark.read
.jdbc(url, "vulcanus_ljl.data_dict", connectionProperties)
spark还可以通过jdbc将DataFrame写入到一张新表(表必须不存在),写入的方式同样分为两种:
jdbcDF.write
.format("jdbc")
.option("url", url)
.option("dbtable", "vulcanus_ljl.data_dict_temp1")
.option("user", "vulcanus_ljl")
.option("password", "mypassword")
.option("createTableColumnTypes", "dict_name varchar(60), dict_type varchar(60)") // 没有指定的字段使用默认的类型
.save()
和
jdbcDF2.write
.jdbc(url, "vulcanus_ljl.data_dict_temp2", connectionProperties)
其中,url和connectionProperties的内容同上文读取时的设置。
写入时可以通过createTableColumnTypes设置指定多个字段的类型,其他没有指定的字段会使用默认的类型。
table
准备table
Spark SQL不需要依赖于一个已经存在的Hive,可以通过下面的代码生成本地的仓库:
import spark.sql
sql("CREATE TABLE IF NOT EXISTS src (key INT, value STRING)")
sql("LOAD DATA LOCAL INPATH 'src/main/resources/kv1.txt' INTO TABLE src")
CREATE TABLE...用来创建表,LOAD DATA用来将数据加载到表中。kv1.txt的文件内容如下:
238val_238
86val_86
311val_311
27val_27
165val_165
409val_409
255val_255
278val_278
98val_98
484val_484
读取
使用下面的代码读取指定表,并打印前5条数据:
spark.read.table("src").show(5)
输出:
+---+-------+
|key| value|
+---+-------+
|238|val_238|
| 86| val_86|
|311|val_311|
| 27| val_27|
|165|val_165|
+---+-------+
写入
使用下面的代码,将DataFrame的数据写入到一张新表:
tableDF.write.saveAsTable("src_bak")
如果要写入一张已经存在的表,需要按照下面的方式:
tableDF.write.mode(SaveMode.Append).saveAsTable("src_bak")
连接一个已存在的Hive
将hive-site.xml放到项目的src/main/resources目录下,spark会自动识别该配置文件,之后所有针对Hive table的读写都是根据配置作用于一个已存在的Hive的。
text
text文件是不包含格式信息的,将text读取为DataFrame需要额外补充格式信息,具体又细分为两种情况:一种是格式是提前约定好的,另一种是在运行时才能确定格式。
下面针对这两种不同的情况分别介绍如何读写text的文件,text文件的内容如下:
Michael, 29
Andy, 30
Justin, 19
格式提前确定
读入text文件:
case class Person(name: String, age: Long)
private def runInferSchemaExample(spark: SparkSession): Unit = {
// $example on:schema_inferring$
// For implicit conversions from RDDs to DataFrames
import spark.implicits._
// Create an RDD of Person objects from a text file, convert it to a Dataframe
val peopleDF = spark.read.textFile("src/main/resources/people.txt")
.map(_.split(","))
.map(attributes => Person(attributes(0), attributes(1).trim.toInt))
.toDF()
peopleDF.show()
}
case class Person就是提前约定的text文件的格式,spark.read.textFile返回的是Dataset[String]类型,text的每一行作为一条数据。
import spark.implicits._是必要的,否则会报异常(我还没有对这块进行研究,无法给出详细的解释)。
写DataFrame到text文件,必须先把DataFrame转换成只有一列的数据集。比如对于上面的peopleDF,它的元素类型是Person,含有name和age两列,直接写就会抛出下面的异常:
Exception in thread "main" org.apache.spark.sql.AnalysisException: path file:/E:/projects/shouzheng/demo-spark/output/text already exists.;
写的方式如下:
peopleDF.map(person => person.getAs[String]("name") + "," + person.getAs[String]("age")).write.text("output/text")
格式在运行时确定
格式在运行时确定,是说我们不是在编码阶段预知数据的格式,所以无法预先定义好对应的case class。可能是因为我们需要解析很多的数据格式,每一种格式都定义case class不合适;可能是因为我们需要支持格式的动态扩展,能支持新的格式;可能是因为我们要处理的格式不稳定,可能发生变化...不管什么原因,其结果一致:我们只能通过更加动态的方式来解析数据的格式。
在这种情况下,我们依然需要获取数据的格式。初步获取的结果可能是常见的形式,比如字符串,然后解析并构造特定的类型StructType来表示数据的格式。
然后我们读取text文件,将内容转换为RDD[Row]类型,其中每一个元素的属性和StructType类型中声明的field是一一对应的。
准备好了代表schema的StructType和代表数据的RDD[Row],我们就可以创建DataFrame对象了:
import spark.implicits._
val peopleRDD = spark.sparkContext.textFile("src/main/resources/people.txt")
// The schema is encoded in a string
val schemaString = "name age"
// Generate the schema based on the string of schema
val fields = schemaString.split(" ")
.map(fieldName => StructField(fieldName, StringType, nullable = true))
val schema = StructType(fields)
// Convert records of the RDD (people) to Rows
val rowRDD = peopleRDD
.map(_.split(","))
.map(attributes => Row(attributes(0), attributes(1).trim))
// Apply the schema to the RDD
val peopleDF = spark.createDataFrame(rowRDD, schema)
写的方式同上,不再赘述。
总结
- 最核心的思想都在上面的那张闭环图上。
- 大部分数据源都有两种读写的方式:一种是指定format,一种是直接以格式名作为方法名。
本文来自博客园,作者:一尾金鱼,转载请注明原文链接:https://www.cnblogs.com/ywjy/p/7747482.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号