
PaddleOCR 安装与实践(CPU版)
0、glibc升级至2.23以及python升级至3.7
https://blog.csdn.net/qq_20989105/article/details/90712139 # glibc 2.23升级
https://www.cnblogs.com/goldsunshine/p/12938654.html # python3.7 升级
1、安装(请按照官网的安装,本人使用docker方式,也是推荐方式,至于克隆源码,我用的是gitee中的,汗......github太慢了.....)
https://hub.fastgit.org/PaddlePaddle/PaddleOCR/blob/release/2.1/doc/doc_ch/installation.md
2、测试是否安装成功,标红说明安装成功啦!
λ ywj-computer /home/PaddleOCR/tools {release/2.0} python3
Python 3.7.0 (default, Apr 13 2021, 06:08:34)
[GCC 8.2.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import paddle
grep: warning: GREP_OPTIONS is deprecated; please use an alias or script
>>>
3、测试官网例子玩玩,(标红的地方可以自己上传自己的图片,更换文件名即可)
python3 tools/infer/predict_system.py --image_dir="./doc/imgs/11.jpg" --det_model_dir="./inference/ch_ppocr_mobile_v2.0_det_infer/" --rec_model_dir="./inference/ch_ppocr_mobile_v2.0_rec_infer/" --cls_model_dir="./inference/ch_ppocr_mobile_v2.0_cls_infer/" --use_angle_cls=True --use_space_char=True python3 tools/infer/predict_system.py --image_dir="./doc/imgs/" --det_model_dir="./inference/ch_ppocr_mobile_v2.0_det_infer/" --rec_model_dir="./inference/ch_ppocr_mobile_v2.0_rec_infer/" --cls_model_dir="./inference/ch_ppocr_mobile_v2.0_cls_infer/" --use_angle_cls=True --use_space_char=True python3 tools/infer/predict_system.py --image_dir="./doc/imgs/3.jpg" --det_model_dir="./inference/ch_ppocr_mobile_v2.0_det_infer/" --rec_model_dir="./inference/ch_ppocr_mobile_v2.0_rec_infer/" --cls_model_dir="./inference/ch_ppocr_mobile_v2.0_cls_infer/" --use_angle_cls=True --use_space_char=True --use_gpu=False
[2021/04/13 07:12:57] root INFO: dt_boxes num : 17, elapse : 0.9136314392089844 [2021/04/13 07:12:57] root INFO: cls num : 17, elapse : 0.08672833442687988 [2021/04/13 07:12:58] root INFO: rec_res num : 17, elapse : 0.17425131797790527 [2021/04/13 07:12:58] root INFO: Predict time of ./doc/imgs/4.jpg: 1.227s [2021/04/13 07:12:58] root INFO: 性出住, 0.932 [2021/04/13 07:12:58] root INFO: 公民身份号码, 0.999 [2021/04/13 07:12:58] root INFO: 名, 1.000 [2021/04/13 07:12:58] root INFO: 男, 0.812 [2021/04/13 07:12:58] root INFO: 1991年7月7日, 0.998 [2021/04/13 07:12:58] root INFO: 杨深度, 0.990 [2021/04/13 07:12:58] root INFO: 村XXX, 0.999 [2021/04/13 07:12:58] root INFO: 湖南省XXXXXX, 0.991 [2021/04/13 07:12:58] root INFO: 民族汉, 0.924 [2021/04/13 07:12:58] root INFO: 43052XXXXXXXXXXX, 0.995 [2021/04/13 07:12:58] root INFO: The visualized image saved in ./inference_results/4.jpg
识别十分准确,只是要获取自己想要的格式以及信息提取还要优化很多
======================安装完成,部署测试==============================
1、部署有两种方式,我这边使用的是hub方式
部署安装文档说明:https://hub.fastgit.org/PaddlePaddle/PaddleOCR/tree/release/2.1/deploy/hubserving
2、返回需要的text字段
1、cd /home/PaddleOCR/deploy/hubserving/ocr_system 2、修改module.py文件: for dno in range(dt_num): text, score = rec_res[dno] rec_res_final.append({ 'text': text # 'confidence': float(score), # 'text_region': dt_boxes[dno].astype(np.int).tolist() }) all_results.append(rec_res_final) 3、可以看上面的注释部分是我们不需要的,我们只需要text部分
3、参数调节params.py(这里我没有做调整)
4、使用flask部署web框架
1、安装flask pip3 install flask pip3 install flask-cors
2、mv test_hubserving.py test_myocr.py,整体代码如下:
# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved. # # Licensed under the Apache License, Version 2.0 (the "License"); # you may not use this file except in compliance with the License. # You may obtain a copy of the License at # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, software # distributed under the License is distributed on an "AS IS" BASIS, # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # See the License for the specific language governing permissions and # limitations under the License. import os import sys __dir__ = os.path.dirname(os.path.abspath(__file__)) sys.path.append(__dir__) sys.path.append(os.path.abspath(os.path.join(__dir__, '..'))) from ppocr.utils.logging import get_logger logger = get_logger() import cv2 import numpy as np import time from PIL import Image from ppocr.utils.utility import get_image_file_list from tools.infer.utility import draw_ocr, draw_boxes import requests import json import base64 from flask import Flask,request from flask_cors import CORS import requests app = Flask(__name__) CORS(app) # 解决跨域问题 def cv2_to_base64(image): return base64.b64encode(image).decode('utf8') def draw_server_result(image_file, res): img = cv2.imread(image_file) image = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB)) if len(res) == 0: return np.array(image) keys = res[0].keys() if 'text_region' not in keys: # for ocr_rec, draw function is invalid logger.info("draw function is invalid for ocr_rec!") return None elif 'text' not in keys: # for ocr_det logger.info("draw text boxes only!") boxes = [] for dno in range(len(res)): boxes.append(res[dno]['text_region']) boxes = np.array(boxes) draw_img = draw_boxes(image, boxes) return draw_img else: # for ocr_system logger.info("draw boxes and texts!") boxes = [] texts = [] scores = [] for dno in range(len(res)): boxes.append(res[dno]['text_region']) texts.append(res[dno]['text']) scores.append(res[dno]['confidence']) boxes = np.array(boxes) scores = np.array(scores) draw_img = draw_ocr( image, boxes, texts, scores, draw_txt=True, drop_score=0.5) return draw_img @app.route("/test") def test(): return 'Hello World!' @app.route("/myocr", methods=["POST"] ) def myocr(): # 输入参数 image_file = request.files['file'] basepath = os.path.dirname(__file__) logger.info("{} basepath".format(basepath)) savepath = os.path.join(basepath, image_file.filename) image_file.save(savepath) img = open(savepath, 'rb').read() if img is None: logger.info("error in loading image:{}".format(image_file)) # 转为 base64 data = {'images': [cv2_to_base64(img)]} # 发送请求 url = "http://127.0.0.1:8866/predict/ocr_system" headers = {"Content-type": "application/json"} r = requests.post(url=url, headers=headers, data=json.dumps(data)) # 返回结果 res = r.json()["results"][0] logger.info(res) return json.dumps(res) if __name__ == '__main__': app.run(host='0.0.0.0', port=5000)
####只提取身份证号以及包含带X的####


# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved. # # Licensed under the Apache License, Version 2.0 (the "License"); # you may not use this file except in compliance with the License. # You may obtain a copy of the License at # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, software # distributed under the License is distributed on an "AS IS" BASIS, # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # See the License for the specific language governing permissions and # limitations under the License. import os import sys __dir__ = os.path.dirname(os.path.abspath(__file__)) sys.path.append(__dir__) sys.path.append(os.path.abspath(os.path.join(__dir__, '..'))) from ppocr.utils.logging import get_logger logger = get_logger() import cv2 import numpy as np import time from PIL import Image from ppocr.utils.utility import get_image_file_list from tools.infer.utility import draw_ocr, draw_boxes import requests import json import base64 from flask import Flask, request from flask_cors import CORS import re import requests app = Flask(__name__) CORS(app) # 解决跨域问题 sys.setrecursionlimit(10000) # 解决循环调用限制 def cv2_to_base64(image): return base64.b64encode(image).decode('utf8') def draw_server_result(image_file, res): img = cv2.imread(image_file) image = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB)) if len(res) == 0: return np.array(image) keys = res[0].keys() if 'text_region' not in keys: # for ocr_rec, draw function is invalid logger.info("draw function is invalid for ocr_rec!") return None elif 'text' not in keys: # for ocr_det logger.info("draw text boxes only!") boxes = [] for dno in range(len(res)): boxes.append(res[dno]['text_region']) boxes = np.array(boxes) draw_img = draw_boxes(image, boxes) return draw_img else: # for ocr_system logger.info("draw boxes and texts!") boxes = [] texts = [] scores = [] for dno in range(len(res)): boxes.append(res[dno]['text_region']) texts.append(res[dno]['text']) scores.append(res[dno]['confidence']) boxes = np.array(boxes) scores = np.array(scores) draw_img = draw_ocr( image, boxes, texts, scores, draw_txt=True, drop_score=0.5) return draw_img @app.route("/ocr", methods=['POST']) def ocr_test(): file = request.files['file'] image_path = file url = "http://127.0.0.1:8866/predict/ocr_system" image_file_list = get_image_file_list(image_path) is_visualize = False headers = {"Content-type": "application/json"} cnt = 0 total_time = 0 for image_file in image_file_list: img = open(image_file, 'rb').read() if img is None: logger.info("error in loading image:{}".format(image_file)) continue # 发送HTTP请求 starttime = time.time() data = {'images': [cv2_to_base64(img)]} r = requests.post(url=url, headers=headers, data=json.dumps(data)) elapse = time.time() - starttime total_time += elapse logger.info("Predict time of %s: %.3fs" % (image_file, elapse)) res = r.json()["results"][0] logger.info(res) if is_visualize: draw_img = draw_server_result(image_file, res) if draw_img is not None: draw_img_save = "./server_results/" if not os.path.exists(draw_img_save): os.makedirs(draw_img_save) cv2.imwrite( os.path.join(draw_img_save, os.path.basename(image_file)), draw_img[:, :, ::-1]) logger.info("The visualized image saved in {}".format( os.path.join(draw_img_save, os.path.basename(image_file)))) cnt += 1 if cnt % 100 == 0: logger.info("{} processed".format(cnt)) logger.info("avg time cost: {}".format(float(total_time) / cnt)) @app.route("/test") def test(): return 'Hello World!' @app.route("/recImg", methods=["POST"]) def recImg(): # 输入参数 image_file = request.files['file'] basepath = os.path.dirname(__file__) logger.info("{} basepath".format(basepath)) savepath = os.path.join(basepath, image_file.filename) image_file.save(savepath) img = open(savepath, 'rb').read() if img is None: logger.info("error in loading image:{}".format(image_file)) # 转为 base64 data = {'images': [cv2_to_base64(img)]} # 发送请求 url = "http://127.0.0.1:8866/predict/ocr_system" headers = {"Content-type": "application/json"} r = requests.post(url=url, headers=headers, data=json.dumps(data)) # 返回结果 res = r.json()["results"][0] logger.info(res) # 删除保存的img os.remove(savepath) # 提取身份证号码 idCardJson = json.dumps(res, ensure_ascii=False) return idCardJson @app.route("/", methods=["POST"]) def myocr(): # 输入参数 image_file = request.files['file'] basepath = os.path.dirname(__file__) logger.info("{} basepath".format(basepath)) savepath = os.path.join(basepath, image_file.filename) image_file.save(savepath) img = open(savepath, 'rb').read() if img is None: logger.info("error in loading image:{}".format(image_file)) # 转为 base64 data = {'images': [cv2_to_base64(img)]} # 发送请求 url = "http://127.0.0.1:8866/predict/ocr_system" headers = {"Content-type": "application/json"} r = requests.post(url=url, headers=headers, data=json.dumps(data)) # 返回结果 res = r.json()["results"][0] logger.info(res) # 删除保存的img os.remove(savepath) # 提取身份证号码 idCardJson = getIDCard(json.dumps(res, ensure_ascii=False)) return idCardJson def getIDCard(text): # logger.info("getIDCard接受的结果 is %s" % (text)) # IDs = re.findall(r"\d{18}|\d{17}[X|x|×]", text) # logger.info("IDs is %s: %s" % (type(IDs), IDs)) # if (len(IDs) != 1): # return "Extract IdCard Error" # idDict = {} # idDict['idCard'] = handleIdCard(IDs[0]) # idCardJson = json.dumps(idDict, ensure_ascii=False) # return idCardJson # 对带X的用户进行处理 logger.info("getIDCard接受的结果 is %s" % (text)) # 国内用户 chIds = re.findall(r"\d{18}|\d{17}[X|x|×]", text) # 港澳用户 hkIDs = re.findall(r"[H|M]\d{8}", text) logger.info("chIds is %s: %s" % (type(chIds), chIds)) logger.info("hkIDs is %s: %s" % (type(hkIDs), hkIDs)) # len(chIds) != 1 表示只有一个数组 idDict = {} if len(chIds) == 1: if len(chIds[0]) == 18: idDict['data'] = handleIdCard(chIds[0]) idDict['code'] = "200" return json.dumps(idDict, ensure_ascii=False) if len(hkIDs) == 1: if len(hkIDs[0]) == 9 and (hkIDs[0].startswith('H') or hkIDs[0].startswith('M')): idDict['data'] = hkIDs[0] idDict['code'] = "200" return json.dumps(idDict, ensure_ascii=False) idDict['code'] = "500" idDict['data'] = "Extract IdCard Error" return json.dumps(idDict, ensure_ascii=False) def handleIdCard(text): if len(text) == 18: logger.info("这是啥====== %s" % (text[len(text) - 1])) if is_number(text[len(text) - 1]): return text else: return text[0:-1] + "X" def is_number(s): try: float(s) return True except ValueError: pass try: import unicodedata unicodedata.numeric(s) return True except (TypeError, ValueError): pass return False if __name__ == '__main__': app.run(host='0.0.0.0', port=5000)
5、运行与测试
1、启动ocr_system:hub serving start -m ocr_system &
2、启动web服务: python3 test_myocr.py &
grep: warning: GREP_OPTIONS is deprecated; please use an alias or script
* Serving Flask app "yangwj" (lazy loading)
* Environment: production
WARNING: This is a development server. Do not use it in a production deployment.
Use a production WSGI server instead.
* Debug mode: off
* Running on http://0.0.0.0:5000/ (Press CTRL+C to quit)
3、postman 测试与结果
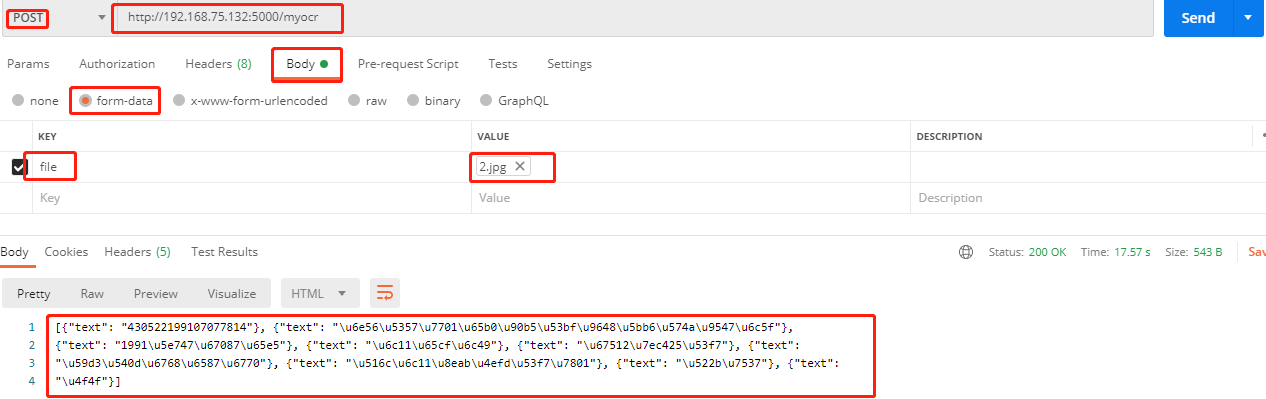
这样一个ocr算法程序就部署好了.............
6、转为uwsgi部署
a) 安装 uwsgi
1、卸载pip uninstall uwsgi 2、安装pip install uwsgi --no-cache-dir
参考博客:https://blog.csdn.net/qq_43590972/article/details/88622750
b) 在tools目录下增加myocr.ini
[uwsgi] #socket配和nginx使用 #socket = 0.0.0.0:8080 #Http请求 http = 0.0.0.0:8080 #项目地址 chdir = /home/PaddleOCR/tools #flask 请使用app callable = app wsgi-file = yangwj.py processes = 2 threads = 4 #最大支持5M buffer-size = 5242880 master = true #支持post请求 post-buffering = 1 pidfile = uwsgi.pid #日志文件 daemonize = ./logs/uwsgi.log
c) 清除uwsgi进程和启动uwsgi进程
pkill -9 uwsgi
uwsgi --ini xxx/uwsgi.ini #请尽量使用绝对路径
d) 访问地址 http://localhost:8080
==============机器重启后,进入容器步骤==================
1、开启python3的虚拟环境
export WORKON_HOME=$HOME/.virtualenvs source /usr/local/bin/virtualenvwrapper.sh source ~/.bashrc
2、workon paddleocr
3、docker restart containerId
4、进入容器
sudo docker container exec -it ppocr /bin/bash
本文来自博客园,作者:小白啊小白,Fighting,转载请注明原文链接:https://www.cnblogs.com/ywjfx/p/14656792.html

