Clickhouse MergeTree家族
参考博客:
1、MergeTree:它拥有主键,但是它的主键却没有唯一键的约束,即可以写入重复数据
1.1 场景
MergeTree用于存储全量的明细数据,对外提供实时查询
1.2 特性
a)只有MergeTree系列的表引擎才支持主键索引,数据分区,数据副本,数据采样这些特性,只有此系列的表引擎才支持ALTER操作
b)MergeTree表引擎在写入一批数据的时候,数据总会以数据片段的形式写入磁盘,并且数据片段不可修改。为了避免片段过多,
clickhouse会通过后台的线程,定期合并这些数据片段,属于不同分区的数据片段会被合并成一个新的片段。
1.3 建表必填项
建表必填项:
1.ENGINE:创建MergeTree的表引擎指定ENGINE = MergeTree() 2.ORDER BY语句:sorting key 排序键,用于指定在一个数据片段内数据以何种标准排序。默认情况下是主键primary key 与排序键相同。排序键可以单个列字段,也可以多个列字段。 选填项: 1.PARTITION BY :分区键 用于指定表数据以何种标准进行分区。分区键可以单个列字段,也可以是通过元祖形式使用的多个列字段,还可以支持使用列表达式。 若不声明分区键则clickhouse会生成一个名为all的分区。合理使用分区 可以有效减少查询数据文件的扫描范围。 2.primary key:主键 声明后会按照主键字段生成一级索引,用于加速表查询。默认情况下主键与排序键相同, 所以通常直接使用order by 指定主键,无须刻意通过primary key声明。在一般情况下,在单个数据片段内 数据与一级索引以相同的规则升序排列。 MergeTree主键允许存在重复数据(ReplacingMergeTree可以去重)。 3.sample by:抽样表达式,用于声明数据以何种标准进行采样。若使用了此配置选项则在主键的配置中也需要声明同样的表达式。 抽样表达式需要配合sample by 子查询使用,这项功能对于选取抽样数据十分有用。 4.TTL:指定表级别的数据存活策略
1.4 MergeTree表引擎中的数据是拥有物理存储的,数据会按照分区目录的形式存储到磁盘之上
1.partition 分区目录partition_n目录下的各类数据文件都是以分区形式被组织存放的,属于相同分区的数据最终会被合并到同一个分区目录内。 2.checksums.txt:校验文件,使用二进制存储,保存了各类文件的size大小和size的哈希值,用于快速校验文件的完整性和正确性。 3.columns.txt:列信息文件,使用文本文件存储,用于保存分区下的列字段信息。 4.count.txt:计数文件,文本文件存储,用于记录当前数据分区目录下数据的总行数。 5.primary.idx:以及索引文件,使用二进制格式存储。用于存放稀疏索引,一张MergeTree表只能声明一次一级索引 (通过order by或者primary key)。借助稀疏索引在数据查询的时候能够排除主键范围之外的数据文件,从而减少数据扫描范围,加速查询速度。 6.[column].bin:数据文件,使用压缩格式存储,默认使用LZ4压缩格式,用于存储某一列的数据。由于MergeTree采用列式存储,每个列字段都拥有独立的bin数据文件,并以列字段命名。 7.[column].mrk列字段标记,使用二进制格式存储。标记文件中保存了bin文件中数据的偏移量信息,标记文件与稀疏文件对齐,又与bin文件一一对应,所以MergeTree通过标记文件建立了primary.idx稀疏索引与bin数据文件的隐射关系。 首先通过primary.idx找到对应数据的偏移量信息(.mrk),再通过偏移量直接从bin文件中读取数据。由于.mrk标记文件与.bin文件一一对应,所以MergeTree中的每个列字段都会拥有与其对应的.mrk文件。 8.[column].mrk2 如使用了自适应大小的索引间隔,则标记文件会以.mrk2命名。工作原理和作用和.mrk标记文件相同。 9.partition.dat和minmax_[column].idx: 若使用了分区键则会额外生成partition.dat和minmax索引文件,均使用二进制格式存储。partition.dat用于保存当前分区下 分区表达式最终生成值,minmax索引文件用于记录当前分区字段对应原始数据的最小值和最大值。 在分区索引作用下,进行数据查询时候能够快速跳过不必要的数据分区目录,从而减少最终需要扫描的数据范围。 10.skp_idx_[column].idx和skp_idx_[column].mrk: 若在建表语句中声明了二级索引则会额外生成相应的二级索引与标记文件,他们同样用二进制存储。 二级索引在clickhouse中又称之为跳数索引,目前拥有minmax,set,ngrambf_v1和tokenbf_v1四种类型。 这些索引的目标和一级稀疏索引相同,为了进一步减少所需要扫描的数据范围,以加速整个查询过程
2、ReplacingMergeTree:为了数据去重设计的,能够在合并分区的时候删除重复的数据,在某种程度上解决了重复数据的问题
参考博客:https://blog.csdn.net/tototuzuoquan/article/details/110913968
2.1合并分区
optimize table tableName final;
2.2 合并查看数据
select * from tableName FORMAT PrettyCompactMonoBlock;
2.3 建表语句
CREATE TABLE org ( `org_code` varchar(8), `org_name` varchar(256), `createtime` Datetime ) ENGINE = ReplacingMergeTree() PARTITION BY toYYYYMM(createtime) ##按年月进行分区 PRIMARY KEY org_code #主键 ORDER BY (org_code, org_name) #排序 注意:在去除重复数据的时候是以ORDER by 为基准,而不是primary key。
2.4 总结
1.使用ORDER BY 排序键作为判断重复数据的唯一键。 2.只有在合并分区的时候才会触发删除重复数据的逻辑。 3.以数据分区为单位删除重复数据。当分区合并时候,同一分区内的重复数据会被删除;不同分区之间的重复数据不会被删除。 4.在进行数据去重时候,因为分区的数据已经基于order by进行排序,所以能够找到相邻的重复数据。 5.数据去重策略: 若没有version 则保留同一组重复数据的最后一行 若设置了version版本号,则保留同一组重复数据中的version取值最大的一行
3、SummingMergeTree:只需要查询汇总值而不太关心明细数据的,且数据的汇总条件是预先明确的则可以直接使用MergeTree存储数据,然后通过group by 聚合查询 并利用SUM聚合函数汇总结果
3.1 场景
聚合求值
3.2 建表语句
CREATE TABLE orders ( `city_id` String, `city_name` varchar(64), `users` int, `orders` int, `amount` decimal(22, 2), `createtime` datetime ) ENGINE = SummingMergeTree() PARTITION BY toYYYYMM(createtime) PRIMARY KEY city_id ORDER BY (city_id, city_name)
3.3 SummingMergeTree 支持嵌套类型的字段,在适用嵌套类型字段的时候需要SUM汇总的字段名称必须以Map后缀结尾
3.2.1建表语句 CREATE TABLE orders_sum ( `city_id` int, `city_name` varchar(32), `statMap` Nested( month int, orders int, amount decimal(22, 2)), `createtime` datetime ) ENGINE = SummingMergeTree() PARTITION BY toYYYYMM(createtime) ORDER BY city_id 3.2.1 optimize table orders_sum final;
3.4 SummingMergeTree的处理逻辑
1.用ORDER BY 排序键作为聚合数据的条件key 2.只有在合并分区的时候才会触发汇总的逻辑 3.以数据分区为单位聚合数据。当分区合并的时候同一数据分区内聚合key相同的数据会被合并汇总,而不同分区之间的数据则不会被汇总。 4.如在定义引擎的时候指定了columns汇总列(非主键的数值类型字段)则sum汇总了这些字段;若未指定则聚合所有非主键的数值类型字段。 5.在进行数据汇总时候因为分区内的数据已经基于order by排序所以能找到相邻且拥有相同聚合key的数据 6.汇总数据时候统一分区内相同聚合key的多行数据会合并成一行。其中汇总字段会进行SUM计算,对于那些非汇总字段则使用第一行数据的取值。 7.支持嵌套结构,单列字段名必须要以Map后缀结尾。嵌套类型中默认以第一个字段作为聚合key。除了第一个字段以外, 任何一Key,id或者Type为后缀结尾的字段,都将和第一个字段一起组合Key.
4、AggregatingMergeTree:在每个数据分区内会按照order by聚合,而使用何种聚合函数以及针对那些列字段计算则通过定义AggregateFunction数据类型实现的
4.1 场景
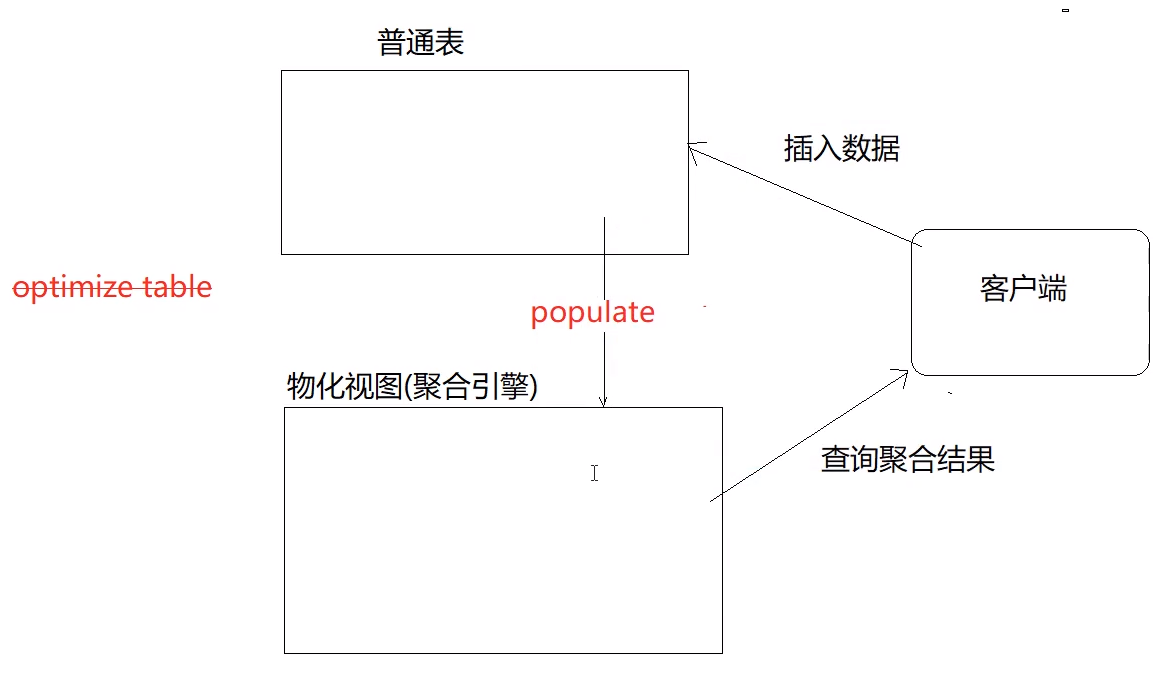
AggregatingMergeTree更为常见的应用场景是结合物化视图使用,作为物化视图的表引擎,而这里的物化视图则作为"其他数据(明细)表上层的一种查询视图(聚合)"
4.2 明细表(MergeTree引擎)
CREATE TABLE agg ( `city_id` varchar(32), `city_name` varchar(64), `item` varchar(32), `item_value` int ) ENGINE = MergeTree() PARTITION BY city_id ORDER BY (city_id, city_name)
4.3 聚合表(AggregatingMergeTree):在明细表上创建视图
CREATE MATERIALIZED VIEW agg_mv ENGINE = AggregatingMergeTree() PARTITION BY city_id ORDER BY (city_id, city_name) AS SELECT city_id, city_name, uniqState(item) AS item, sumState(item_value) AS value FROM agg GROUP BY city_id, city_name
4.4 AggregatingMergeTree处理逻辑
1.使用ORDER BY排序键作为聚合数据的条件key 2.使用AggregateFunction字段类型定义聚合函数的类型以及聚合的字段 3.只有在合并分区的时候才会触发聚合计算的逻辑 4.以数据分区为单位来聚合数据。当分区合并时候,同一数据分区内聚合key相同的数据会被合并计算,而不同分区之间的数据则不会被计算。 5.在进行数据计算时候,因为分区内的数据已经基于ORDER BY排序,所以能够找到那些相邻且拥有相同聚合key的数据。 6.在聚合数据时候,同一分区内相同聚合key的多行数据会合并成一行。对于那些非主键,非AggregateFunction类型字段则会使用第一行的数据取值。 7.AggregateFunction类型的字段使用二进制存储,在写入数据的时候,需要*State函数,在查询数据的时候,则需要调用相应的*Merge函数。其中*表示定义时使用的聚合函数。 8.AggregateMergeTree通常作为物化视图的表引擎,与普通MergeTree搭配使用
5、CollapsingMergeTree是一种以增待删的思路,支持行级别的表引擎
5.1 特征
通过定义一个sign标记字段,记录数据行的状态。sign为1表示当前行有效,sign为-1则表示此行数据需要删除;
当CollapsingMergeTree 分区合并的时候,同一数据分区内标记为1和-1的一组数据会抵消删除。
5.2 建表语句
CREATE TABLE collpase ( `id` String, `code` String, `createtime` datetime, `sign` tinyint #注意:sign字段必须为Int8类型或者为tinyint ) ENGINE = CollapsingMergeTree(sign) PARTITION BY toYYYYMM(createtime) ORDER BY id
5.3 强制合并数据(关键字:final)
select * from collpase final FORMAT PrettyCompactMonoBlock;
5.4 CollapsingMergeTree数据折叠规则
1.若sign=1 和sign=-1的数据多一行则保留最后一行sign=1的数据 2.若sign=1 和sign=-1的数据少一行则保留第一行sign=-1的数据 3.若sign=1 和sign=-1的数据行数一样多且最后一行是sign=1则保留第一行sign=-1和最后一行sign=1的数据。 4.若sign=1和sign=1的数据行一样多且最后一行是sign=-1 则什么也不保留 5.非以上情况则会打印警告信息,但是不会报错,此时查询结果不可预知
本文来自博客园,作者:小白啊小白,Fighting,转载请注明原文链接:https://www.cnblogs.com/ywjfx/p/14314309.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号