
python之scrapy爬取jd和qq招聘信息
1、settings.py文件


# -*- coding: utf-8 -*- # Scrapy settings for jd project # # For simplicity, this file contains only settings considered important or # commonly used. You can find more settings consulting the documentation: # # https://doc.scrapy.org/en/latest/topics/settings.html # https://doc.scrapy.org/en/latest/topics/downloader-middleware.html # https://doc.scrapy.org/en/latest/topics/spider-middleware.html BOT_NAME = 'jd' SPIDER_MODULES = ['jd.spiders'] NEWSPIDER_MODULE = 'jd.spiders' LOG_LEVEL="WARNING" LOG_FILE="./jingdong1.log" # Crawl responsibly by identifying yourself (and your website) on the user-agent #USER_AGENT = 'jd (+http://www.yourdomain.com)' # Obey robots.txt rules ROBOTSTXT_OBEY = True # Configure maximum concurrent requests performed by Scrapy (default: 16) #CONCURRENT_REQUESTS = 32 # Configure a delay for requests for the same website (default: 0) # See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay # See also autothrottle settings and docs #DOWNLOAD_DELAY = 3 # The download delay setting will honor only one of: #CONCURRENT_REQUESTS_PER_DOMAIN = 16 #CONCURRENT_REQUESTS_PER_IP = 16 # Disable cookies (enabled by default) #COOKIES_ENABLED = False # Disable Telnet Console (enabled by default) #TELNETCONSOLE_ENABLED = False # Override the default request headers: #DEFAULT_REQUEST_HEADERS = { # 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', # 'Accept-Language': 'en', #} # Enable or disable spider middlewares # See https://doc.scrapy.org/en/latest/topics/spider-middleware.html #SPIDER_MIDDLEWARES = { # 'jd.middlewares.JdSpiderMiddleware': 543, #} # Enable or disable downloader middlewares # See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html #DOWNLOADER_MIDDLEWARES = { # 'jd.middlewares.JdDownloaderMiddleware': 543, #} # Enable or disable extensions # See https://doc.scrapy.org/en/latest/topics/extensions.html #EXTENSIONS = { # 'scrapy.extensions.telnet.TelnetConsole': None, #} # Configure item pipelines # See https://doc.scrapy.org/en/latest/topics/item-pipeline.html #ITEM_PIPELINES = { # 'jd.pipelines.JdPipeline': 300, #} # Enable and configure the AutoThrottle extension (disabled by default) # See https://doc.scrapy.org/en/latest/topics/autothrottle.html #AUTOTHROTTLE_ENABLED = True # The initial download delay #AUTOTHROTTLE_START_DELAY = 5 # The maximum download delay to be set in case of high latencies #AUTOTHROTTLE_MAX_DELAY = 60 # The average number of requests Scrapy should be sending in parallel to # each remote server #AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0 # Enable showing throttling stats for every response received: #AUTOTHROTTLE_DEBUG = False # Enable and configure HTTP caching (disabled by default) # See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings #HTTPCACHE_ENABLED = True #HTTPCACHE_EXPIRATION_SECS = 0 #HTTPCACHE_DIR = 'httpcache' #HTTPCACHE_IGNORE_HTTP_CODES = [] #HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
2、jingdong.py文件
# -*- coding: utf-8 -*- import scrapy import logging import json logger = logging.getLogger(__name__) class JingdongSpider(scrapy.Spider): name = 'jingdong' allowed_domains = ['zhaopin.jd.com'] start_urls = ['http://zhaopin.jd.com/web/job/job_list?page=1'] pageNum = 1 def parse(self, response): content = response.body.decode() content = json.loads(content) ##########去除列表中字典集中的空值########### for i in range(len(content)): #list(content[i].keys()获取当前字典中的key for key in list(content[i].keys()): #content[i]为字典 if not content[i].get(key):#content[i].get(key)根据key获取value del content[i][key] #删除空值字典 for i in range(len(content)): logging.warning(content[i]) self.pageNum = self.pageNum+1 if self.pageNum<=355: next_url = "http://zhaopin.jd.com/web/job/job_list?page="+str(self.pageNum) yield scrapy.Request( next_url, callback=self.parse ) pass
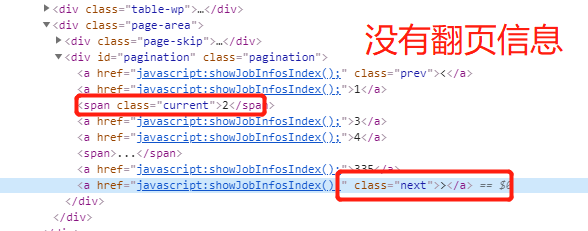
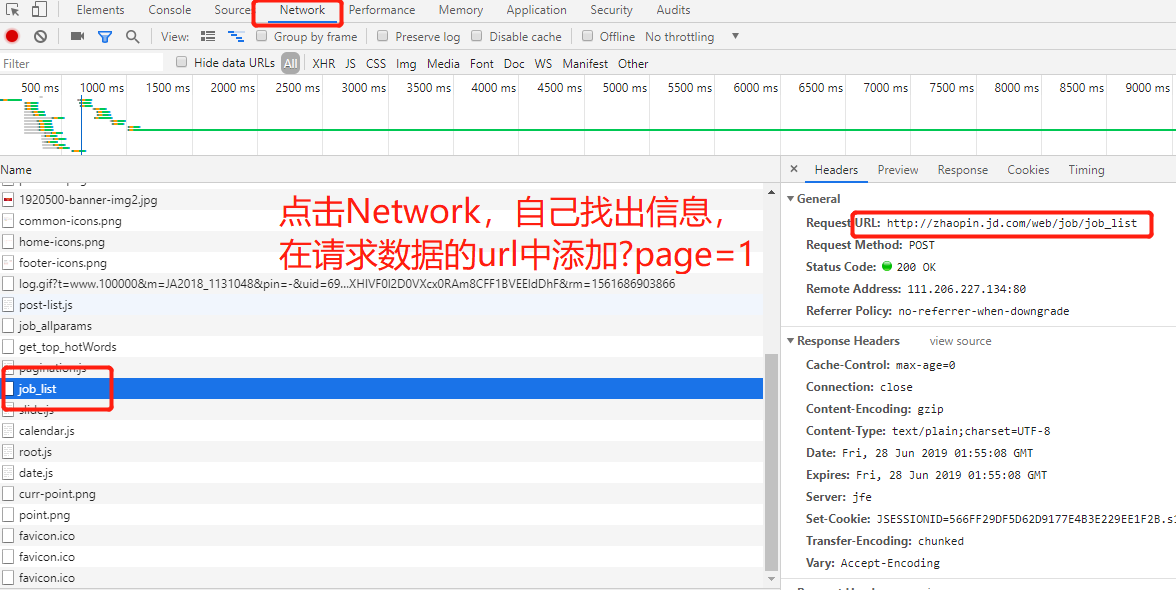
3、注意点,针对jingdong的招聘翻页是使用javascrapt,所以无法使用crawlscrapy进行自动翻页,但是我们再network中查看其获取数据的方法。
如:http://zhaopin.jd.com/web/job/job_list?page=2
#############jingdong可以了,那么试试tencent公司的招聘信息吧###############
测试下吧!
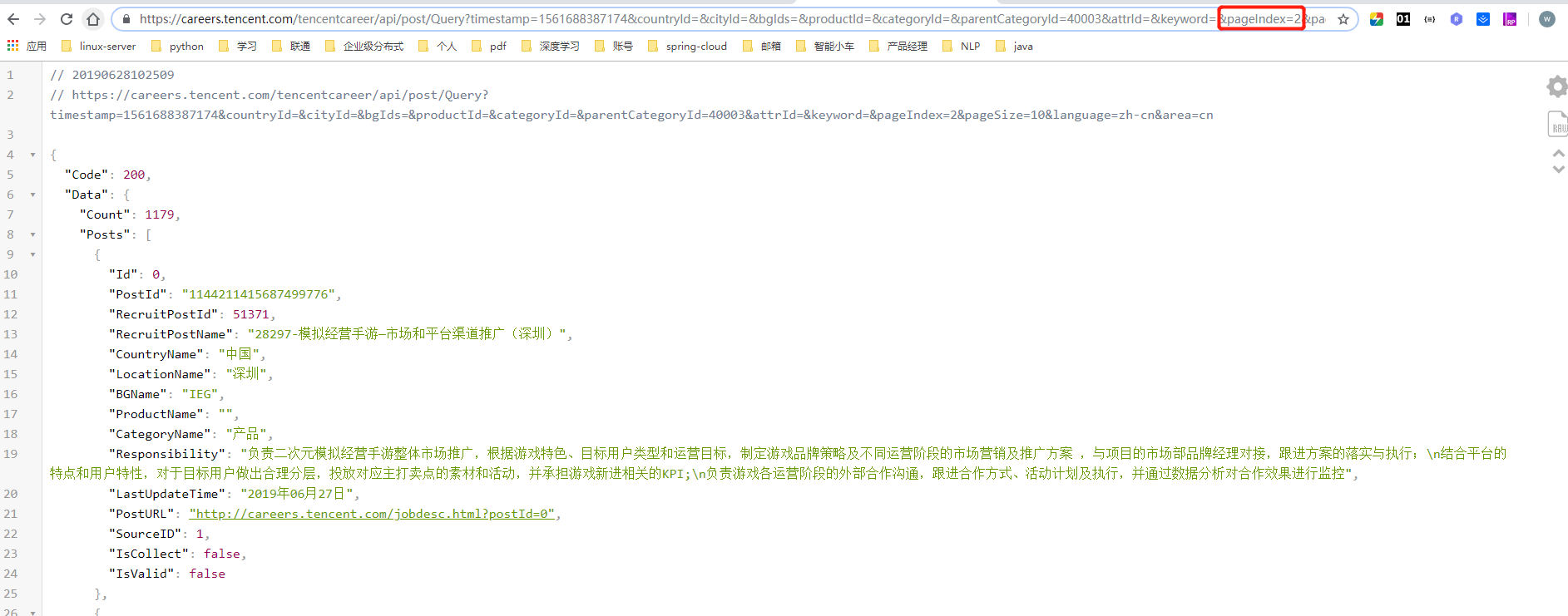
结果知道了吧!!!!! 开始干活!!!!!!!!!!
1、settings.py
# -*- coding: utf-8 -*- # Scrapy settings for tencent project # # For simplicity, this file contains only settings considered important or # commonly used. You can find more settings consulting the documentation: # # https://doc.scrapy.org/en/latest/topics/settings.html # https://doc.scrapy.org/en/latest/topics/downloader-middleware.html # https://doc.scrapy.org/en/latest/topics/spider-middleware.html BOT_NAME = 'tencent' SPIDER_MODULES = ['tencent.spiders'] NEWSPIDER_MODULE = 'tencent.spiders' LOG_LEVEL="WARNING" LOG_FILE="./qq.log" # Crawl responsibly by identifying yourself (and your website) on the user-agent USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36' # Obey robots.txt rules #ROBOTSTXT_OBEY = True # Configure maximum concurrent requests performed by Scrapy (default: 16) #CONCURRENT_REQUESTS = 32 # Configure a delay for requests for the same website (default: 0) # See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay # See also autothrottle settings and docs #DOWNLOAD_DELAY = 3 # The download delay setting will honor only one of: #CONCURRENT_REQUESTS_PER_DOMAIN = 16 #CONCURRENT_REQUESTS_PER_IP = 16 # Disable cookies (enabled by default) #COOKIES_ENABLED = False # Disable Telnet Console (enabled by default) #TELNETCONSOLE_ENABLED = False # Override the default request headers: #DEFAULT_REQUEST_HEADERS = { # 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', # 'Accept-Language': 'en', #} # Enable or disable spider middlewares # See https://doc.scrapy.org/en/latest/topics/spider-middleware.html #SPIDER_MIDDLEWARES = { # 'tencent.middlewares.TencentSpiderMiddleware': 543, #} # Enable or disable downloader middlewares # See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html #DOWNLOADER_MIDDLEWARES = { # 'tencent.middlewares.TencentDownloaderMiddleware': 543, #} # Enable or disable extensions # See https://doc.scrapy.org/en/latest/topics/extensions.html #EXTENSIONS = { # 'scrapy.extensions.telnet.TelnetConsole': None, #} # Configure item pipelines # See https://doc.scrapy.org/en/latest/topics/item-pipeline.html #ITEM_PIPELINES = { # 'tencent.pipelines.TencentPipeline': 300, #} # Enable and configure the AutoThrottle extension (disabled by default) # See https://doc.scrapy.org/en/latest/topics/autothrottle.html #AUTOTHROTTLE_ENABLED = True # The initial download delay #AUTOTHROTTLE_START_DELAY = 5 # The maximum download delay to be set in case of high latencies #AUTOTHROTTLE_MAX_DELAY = 60 # The average number of requests Scrapy should be sending in parallel to # each remote server #AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0 # Enable showing throttling stats for every response received: #AUTOTHROTTLE_DEBUG = False # Enable and configure HTTP caching (disabled by default) # See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings #HTTPCACHE_ENABLED = True #HTTPCACHE_EXPIRATION_SECS = 0 #HTTPCACHE_DIR = 'httpcache' #HTTPCACHE_IGNORE_HTTP_CODES = [] #HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
2、mahuateng.py
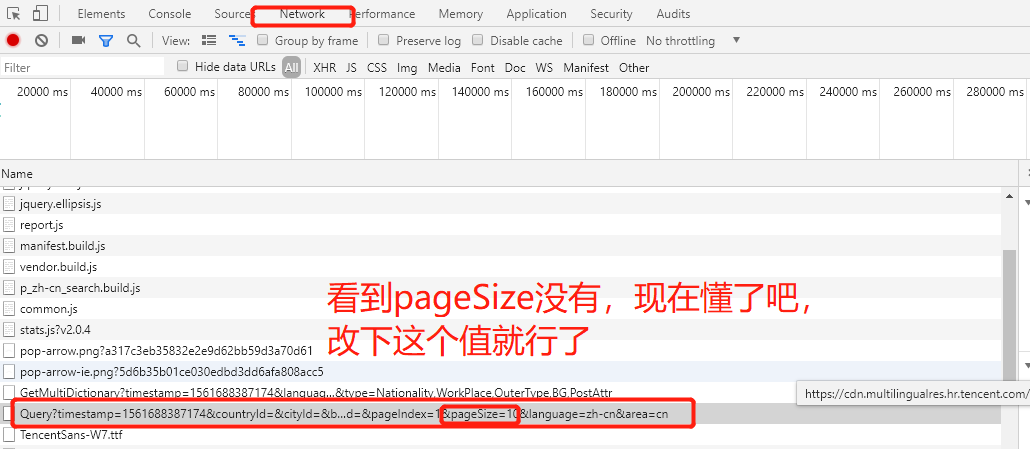
# -*- coding: utf-8 -*- import scrapy import json import logging class MahuatengSpider(scrapy.Spider): name = 'mahuateng' allowed_domains = ['careers.tencent.com'] start_urls = ['https://careers.tencent.com/tencentcareer/api/post/Query?timestamp=1561688387174&countryId=&cityId=&bgIds=&productId=&categoryId=&parentCategoryId=40003&attrId=&keyword=&pageIndex=1&pageSize=10&language=zh-cn&area=cn'] pageNum = 1 def parse(self, response): content = response.body.decode() content = json.loads(content) content=content['Data']['Posts'] #删除空字典 for con in content: #print(con) for key in list(con.keys()): if not con.get(key): del con[key] #记录每一个岗位信息 for con in content: logging.warning(con) #####翻页###### self.pageNum = self.pageNum+1 if self.pageNum<=118: next_url = "https://careers.tencent.com/tencentcareer/api/post/Query?timestamp=1561688387174&countryId=&cityId=&bgIds=&productId=&categoryId=&parentCategoryId=40003&attrId=&keyword=&pageIndex="+str(self.pageNum)+"&pageSize=10&language=zh-cn&area=cn" yield scrapy.Request( next_url, callback=self.parse )
个人测试是可以的,你们的就看运气了,哈哈!
这些都是个人玩的,码的比较丑陋。
本文来自博客园,作者:小白啊小白,Fighting,转载请注明原文链接:https://www.cnblogs.com/ywjfx/p/11101091.html

