
机器学习之决策树
# coding = utf-8 from sklearn.datasets import load_iris, fetch_20newsgroups, load_boston from sklearn.model_selection import train_test_split, GridSearchCV from sklearn.neighbors import KNeighborsClassifier from sklearn.preprocessing import StandardScaler from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.naive_bayes import MultinomialNB from sklearn.metrics import classification_report from sklearn.feature_extraction import DictVectorizer from sklearn.tree import DecisionTreeClassifier, export_graphviz from sklearn.ensemble import RandomForestClassifier import pandas as pd ''' 信息熵:H(x) = -P(x)logP(x) ,P(x)目标值的概率 信息增益:属性(特征)的信息熵,目的是消除不确定性信息 特征的信息增益越大,说明更具有代表 划分依据: 信息增益最大原则:ID3 信息增益比最大原则:C4.5 回归树:平方误差最小 分类树:基尼系数, API:sklearn.tree import DecisionTreeClassifier sklearn.tree.DecisionTreeClassifier(criterion=’gini’, max_depth=None,random_state=None) 决策树分类器 criterion:默认是’gini’系数,也可以选择信息增益的熵’entropy’ max_depth:树的深度大小 random_state:随机数种子 method: decision_path:返回决策树的路径 pd转换字典:x_train.to_dict(orient="records") 优点: 数目可视化 数据量不需要很大 缺点:容易过拟合 ,解决方法:剪枝操作 算法步骤: 1、pd读取数据 2、选择有影响的特征,处理缺失值 3、进行特征工程,pd转换字典,特征抽取 x_train.to_dict(orient="records") 4、决策树估计器流程 决策树优点: 能够有效地运行在大数据集上 能够处理具有高维特征的输入样本,而且不需要降维 能够评估各个特征在分类问题上的重要性 对于缺省值问题也能够获得很好得结果 随机森林:是一个包含多个决策树的分类器,并且其输出的类别是由个别树输出的类别的众数而定。 即对n样本中进行n次抽样 ,同样对m特征进行m次抽取,建立一颗决策树 随机森林API: sklearn.ensemble.RandomForestClassifier(n_estimators=10, criterion=’gini’, max_depth=None, bootstrap=True, random_state=None) 随机森林分类器 n_estimators:integer,optional(default = 10) 森林里的树木数量 criteria:string,可选(default =“gini”)分割特征的测量方法 max_depth:integer或None,可选(默认=无)树的最大深度 bootstrap:boolean,optional(default = True)是否在构建树时使用放回抽样
查看决策树生成的树状结构图.dot文件
1、安装 graphviz
2、运行 dot -Tpng tree.dot -o tree.png
''' def decision(): """ 决策树对泰坦尼克号进行预测生死 :return: None """ # 获取数据 titan = pd.read_csv("http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic.txt") # 处理数据,找出特征值和目标值 x = titan[['pclass', 'age', 'sex']] y = titan['survived'] print(x) # 缺失值处理 x['age'].fillna(x['age'].mean(), inplace=True) # 分割数据集到训练集合测试集 x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.25) # 进行处理(特征工程)特征-》类别-》one_hot编码 dict = DictVectorizer(sparse=False) x_train = dict.fit_transform(x_train.to_dict(orient="records")) print(dict.get_feature_names()) x_test = dict.transform(x_test.to_dict(orient="records")) # print(x_train) # 用决策树进行预测 # dec = DecisionTreeClassifier() # # dec.fit(x_train, y_train) # # # 预测准确率 # print("预测的准确率:", dec.score(x_test, y_test)) # # # 导出决策树的结构 # export_graphviz(dec, out_file="./tree.dot", feature_names=['年龄', 'pclass=1st', 'pclass=2nd', 'pclass=3rd', '女性', '男性']) # 随机森林进行预测 (超参数调优) rf = RandomForestClassifier(n_jobs=-1) #网格搜索,共30次搜索过程 param = {"n_estimators": [120, 200, 300, 500, 800, 1200], "max_depth": [5, 8, 15, 25, 30]} # 网格搜索与交叉验证 gc = GridSearchCV(rf, param_grid=param, cv=2) gc.fit(x_train, y_train) print("准确率:", gc.score(x_test, y_test)) print("查看选择的参数模型:", gc.best_params_) return None
计算方法:
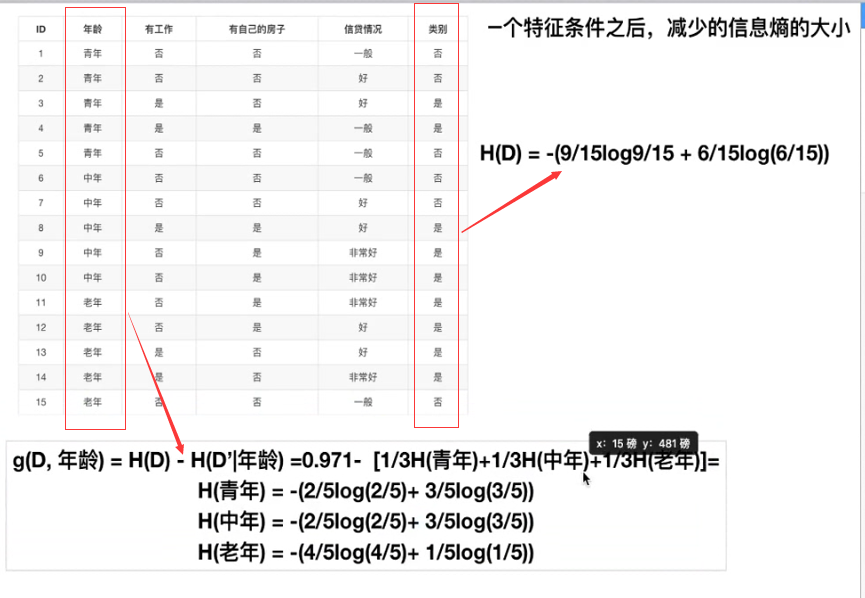
本文来自博客园,作者:小白啊小白,Fighting,转载请注明原文链接:https://www.cnblogs.com/ywjfx/p/10883805.html

