PSENET阅读笔记
Shape Robust Text Detection with Progressive Scale Expansion Network
PSENET全称叫做渐进式扩展网络,是一种由缩放的文本核逐渐扩展为真实文本的算法;主要解决的就是距离很近的文本无法很好区分其边界的问题。
优点是:检测任意形状的文本;检测距离很近的文本
缺点是:速度较慢,但第二版pan对于速度有很大提升
整体结构简洁,主要分为FPN提取特征图阶段和渐进扩展阶段
第一阶段特征图提取
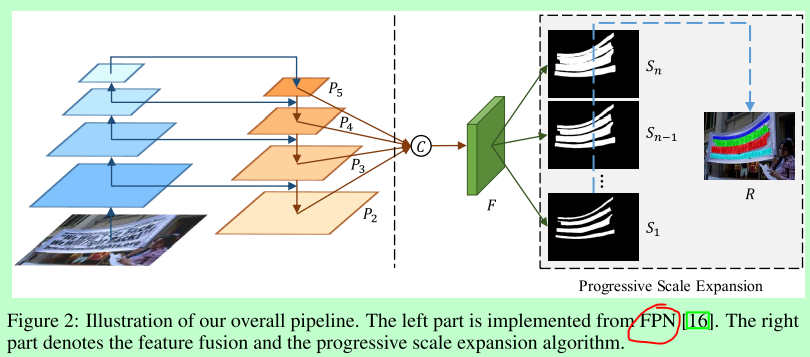
与FPN基本类似,在得到p2、p3、p4、p5特征图后,concat起来,用分割的方法逐像素预测文本核(上图的s1-sn)
文本核是本文算法的核心,下面的渐进扩展就是利用每个文本核进行;
文本核是相对于原始的文本标签进行一定程度的缩放,上图中的s1-sn是不同比例的缩放,s1为最原始的文本核也是最小的文本核,sn为最大的文本核
渐进扩展
渐进扩展部分主要目的是从里向外扩展以区分靠近的文本,而不是直接预测
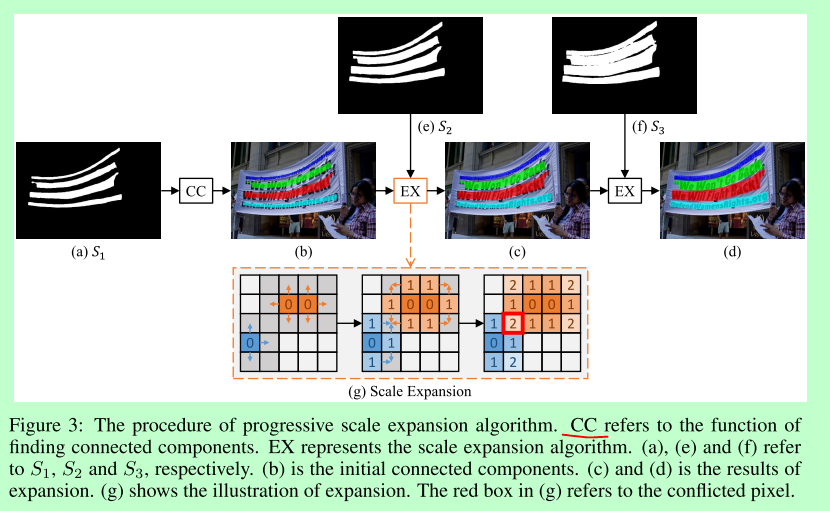
s1-sn为网络预测的不同缩放比例的文本核,CC为求像素的连通区域,EX为扩展,具体实现在(g),(b)为连通区域结果,(c,d)为每次扩展的结果
以s1,s2扩展为例:其余文本核的操作过程一样
s1内的元素作为扩展的基础,不同的文本寻找各自连通元素,
s2内元素作为边界限定(也就是说s2是个粗边界,s1扩展得到的要在s2中)
不同的颜色也就是不同个文本对象,若有冲突,按照队列先进先出的特点扩展。
停止扩展的条件是,sn中的元素没有连通区域在sn+1中
损失函数
损失函数有多个目标,需要对每个缩放的文本核也进行Loss计算,故

Lc是表示没有进行缩放时候的损失函数,即相对于原始大小的groundtruth的损失函数,表示的是相对于缩放后的框的损失函数。
采用的是分割常用的dice loss,优点是直接从任务本身出发,类似Iou loss,缺点是loss曲线不稳定不易观察何时停止。
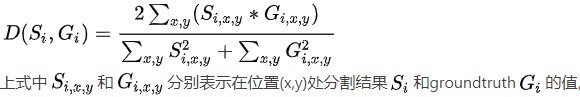
而且,为了避免计算冗余,对于缩小的核loss计算,Sn中非文本区域不算入loss。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号