RetinaFace论文阅读笔记,简要总结
RetinaFace: Single-stageDenseFaceLocalisationintheWild
retinaface是一个鲁棒性较强的单阶段人脸检测器,比较突出的工作是加入了 extra-supervised 和 self-supervised ;
大部分人脸检测重点关注人脸分类和人脸框定位这两部分,retinaface加入了face landmark 回归( five facial landmarks)以及dense face regression(主要是3d相关);
加入的任务如下图所示:
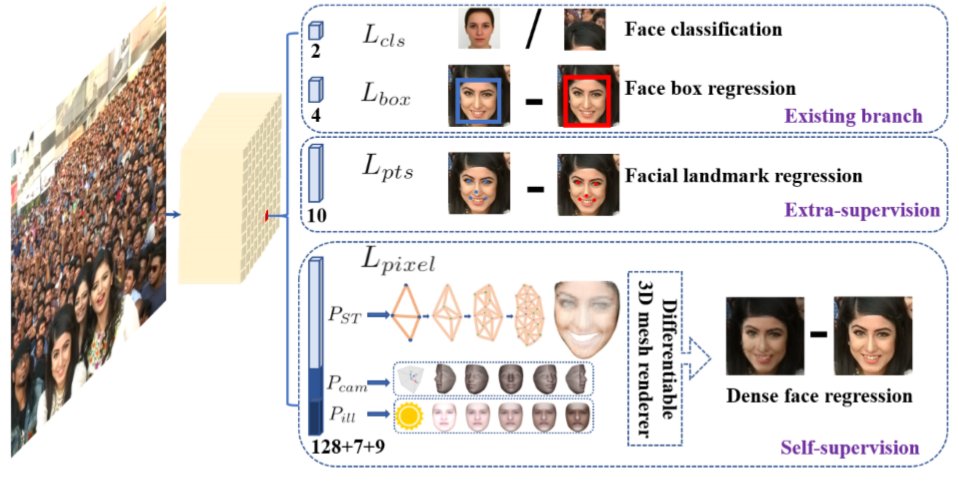
retinaface结构特点主要以下几点:
feature pyramid,采用特征金字塔提取多尺度特征, (to increase the receptive field and enhance the rigid context modelling power)
single-stage,单阶段,快捷高效,用mobile-net时在arm上可以实时
Context Modelling, (to increase the receptive field and enhance the rigid context modelling power)
Multi-task Learning ,额外监督信息
结构图如下:

loss函数设计:Multi-taskLoss
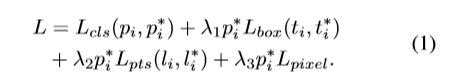
第一部分是分类Loss, 第二部分是人脸框回归Loss, 第三部分是人脸关键点回归loss,第四部分是dense regression loss;
在实现的时候,还有些细节。
1.使用可行变卷积代替lateral connections和context modules中的3*3卷积 (further strengthens the non-rigid context modelling capacity);
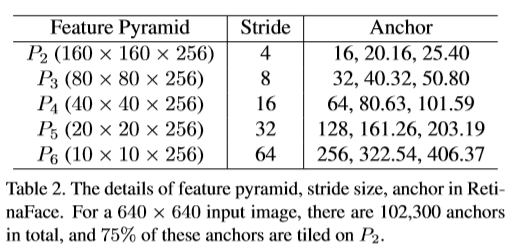
2.anchor的设置,fpn每层输出对应不同的anchor尺寸。
3.Extra Annotations,数据集部分做额外的标注信息
3.1定义了五个等级的人脸质量,根据清晰度检测难度定义;
3.2定义人脸关键点。


结果:
在WIDER FACE dataset上,96.9% (Easy), 96.1% (Medium) and 91.8% (Hard) for validation set, and 96.3% (Easy), 95.6% (Medium) and 91.4% (Hard) for test set.
速度:

表格里面单位ms;轻量级网轻松达到实时检测。
主网络结构代码:
import torch import torch.nn as nn import torchvision.models.detection.backbone_utils as backbone_utils import torchvision.models._utils as _utils import torch.nn.functional as F from collections import OrderedDict from models.net import MobileNetV1 as MobileNetV1 from models.net import FPN as FPN from models.net import SSH as SSH class ClassHead(nn.Module): def __init__(self,inchannels=512,num_anchors=3): super(ClassHead,self).__init__() self.num_anchors = num_anchors self.conv1x1 = nn.Conv2d(inchannels,self.num_anchors*2,kernel_size=(1,1),stride=1,padding=0) def forward(self,x): out = self.conv1x1(x) out = out.permute(0,2,3,1).contiguous() return out.view(out.shape[0], -1, 2) class BboxHead(nn.Module): def __init__(self,inchannels=512,num_anchors=3): super(BboxHead,self).__init__() self.conv1x1 = nn.Conv2d(inchannels,num_anchors*4,kernel_size=(1,1),stride=1,padding=0) def forward(self,x): out = self.conv1x1(x) out = out.permute(0,2,3,1).contiguous() return out.view(out.shape[0], -1, 4) class LandmarkHead(nn.Module): def __init__(self,inchannels=512,num_anchors=3): super(LandmarkHead,self).__init__() self.conv1x1 = nn.Conv2d(inchannels,num_anchors*10,kernel_size=(1,1),stride=1,padding=0) def forward(self,x): out = self.conv1x1(x) out = out.permute(0,2,3,1).contiguous() return out.view(out.shape[0], -1, 10) class RetinaFace(nn.Module): def __init__(self, cfg = None, phase = 'train'): """ :param cfg: Network related settings. :param phase: train or test. """ super(RetinaFace,self).__init__() self.phase = phase backbone = None if cfg['name'] == 'mobilenet0.25': backbone = MobileNetV1() if cfg['pretrain']: checkpoint = torch.load("./weights/mobilenetV1X0.25_pretrain.tar", map_location=torch.device('cpu')) from collections import OrderedDict new_state_dict = OrderedDict() for k, v in checkpoint['state_dict'].items(): name = k[7:] # remove module. new_state_dict[name] = v # load params backbone.load_state_dict(new_state_dict) elif cfg['name'] == 'Resnet50': import torchvision.models as models backbone = models.resnet50(pretrained=cfg['pretrain']) self.body = _utils.IntermediateLayerGetter(backbone, cfg['return_layers']) in_channels_stage2 = cfg['in_channel'] in_channels_list = [ in_channels_stage2 * 2, in_channels_stage2 * 4, in_channels_stage2 * 8, ] out_channels = cfg['out_channel'] self.fpn = FPN(in_channels_list,out_channels) self.ssh1 = SSH(out_channels, out_channels) self.ssh2 = SSH(out_channels, out_channels) self.ssh3 = SSH(out_channels, out_channels) self.ClassHead = self._make_class_head(fpn_num=3, inchannels=cfg['out_channel']) self.BboxHead = self._make_bbox_head(fpn_num=3, inchannels=cfg['out_channel']) self.LandmarkHead = self._make_landmark_head(fpn_num=3, inchannels=cfg['out_channel']) def _make_class_head(self,fpn_num=3,inchannels=64,anchor_num=2): classhead = nn.ModuleList() for i in range(fpn_num): classhead.append(ClassHead(inchannels,anchor_num)) return classhead def _make_bbox_head(self,fpn_num=3,inchannels=64,anchor_num=2): bboxhead = nn.ModuleList() for i in range(fpn_num): bboxhead.append(BboxHead(inchannels,anchor_num)) return bboxhead def _make_landmark_head(self,fpn_num=3,inchannels=64,anchor_num=2): landmarkhead = nn.ModuleList() for i in range(fpn_num): landmarkhead.append(LandmarkHead(inchannels,anchor_num)) return landmarkhead def forward(self,inputs): out = self.body(inputs) # FPN fpn = self.fpn(out) # SSH feature1 = self.ssh1(fpn[0]) feature2 = self.ssh2(fpn[1]) feature3 = self.ssh3(fpn[2]) features = [feature1, feature2, feature3] bbox_regressions = torch.cat([self.BboxHead[i](feature) for i, feature in enumerate(features)], dim=1) classifications = torch.cat([self.ClassHead[i](feature) for i, feature in enumerate(features)],dim=1) ldm_regressions = torch.cat([self.LandmarkHead[i](feature) for i, feature in enumerate(features)], dim=1) if self.phase == 'train': output = (bbox_regressions, classifications, ldm_regressions) else: output = (bbox_regressions, F.softmax(classifications, dim=-1), ldm_regressions) return output
引用的fpn,ssh等结构代码
import time import torch import torch.nn as nn import torchvision.models._utils as _utils import torchvision.models as models import torch.nn.functional as F from torch.autograd import Variable def conv_bn(inp, oup, stride = 1, leaky = 0): return nn.Sequential( nn.Conv2d(inp, oup, 3, stride, 1, bias=False), nn.BatchNorm2d(oup), nn.LeakyReLU(negative_slope=leaky, inplace=True) ) def conv_bn_no_relu(inp, oup, stride): return nn.Sequential( nn.Conv2d(inp, oup, 3, stride, 1, bias=False), nn.BatchNorm2d(oup), ) def conv_bn1X1(inp, oup, stride, leaky=0): return nn.Sequential( nn.Conv2d(inp, oup, 1, stride, padding=0, bias=False), nn.BatchNorm2d(oup), nn.LeakyReLU(negative_slope=leaky, inplace=True) ) def conv_dw(inp, oup, stride, leaky=0.1): return nn.Sequential( nn.Conv2d(inp, inp, 3, stride, 1, groups=inp, bias=False), nn.BatchNorm2d(inp), nn.LeakyReLU(negative_slope= leaky,inplace=True), nn.Conv2d(inp, oup, 1, 1, 0, bias=False), nn.BatchNorm2d(oup), nn.LeakyReLU(negative_slope= leaky,inplace=True), ) class SSH(nn.Module): def __init__(self, in_channel, out_channel): super(SSH, self).__init__() assert out_channel % 4 == 0 leaky = 0 if (out_channel <= 64): leaky = 0.1 self.conv3X3 = conv_bn_no_relu(in_channel, out_channel//2, stride=1) self.conv5X5_1 = conv_bn(in_channel, out_channel//4, stride=1, leaky = leaky) self.conv5X5_2 = conv_bn_no_relu(out_channel//4, out_channel//4, stride=1) self.conv7X7_2 = conv_bn(out_channel//4, out_channel//4, stride=1, leaky = leaky) self.conv7x7_3 = conv_bn_no_relu(out_channel//4, out_channel//4, stride=1) def forward(self, input): conv3X3 = self.conv3X3(input) conv5X5_1 = self.conv5X5_1(input) conv5X5 = self.conv5X5_2(conv5X5_1) conv7X7_2 = self.conv7X7_2(conv5X5_1) conv7X7 = self.conv7x7_3(conv7X7_2) out = torch.cat([conv3X3, conv5X5, conv7X7], dim=1) out = F.relu(out) return out class FPN(nn.Module): def __init__(self,in_channels_list,out_channels): super(FPN,self).__init__() leaky = 0 if (out_channels <= 64): leaky = 0.1 self.output1 = conv_bn1X1(in_channels_list[0], out_channels, stride = 1, leaky = leaky) self.output2 = conv_bn1X1(in_channels_list[1], out_channels, stride = 1, leaky = leaky) self.output3 = conv_bn1X1(in_channels_list[2], out_channels, stride = 1, leaky = leaky) self.merge1 = conv_bn(out_channels, out_channels, leaky = leaky) self.merge2 = conv_bn(out_channels, out_channels, leaky = leaky) def forward(self, input): # names = list(input.keys()) input = list(input.values()) output1 = self.output1(input[0]) output2 = self.output2(input[1]) output3 = self.output3(input[2]) up3 = F.interpolate(output3, size=[output2.size(2), output2.size(3)], mode="nearest") output2 = output2 + up3 output2 = self.merge2(output2) up2 = F.interpolate(output2, size=[output1.size(2), output1.size(3)], mode="nearest") output1 = output1 + up2 output1 = self.merge1(output1) out = [output1, output2, output3] return out class MobileNetV1(nn.Module): def __init__(self): super(MobileNetV1, self).__init__() self.stage1 = nn.Sequential( conv_bn(3, 8, 2, leaky = 0.1), # 3 conv_dw(8, 16, 1), # 7 conv_dw(16, 32, 2), # 11 conv_dw(32, 32, 1), # 19 conv_dw(32, 64, 2), # 27 conv_dw(64, 64, 1), # 43 ) self.stage2 = nn.Sequential( conv_dw(64, 128, 2), # 43 + 16 = 59 conv_dw(128, 128, 1), # 59 + 32 = 91 conv_dw(128, 128, 1), # 91 + 32 = 123 conv_dw(128, 128, 1), # 123 + 32 = 155 conv_dw(128, 128, 1), # 155 + 32 = 187 conv_dw(128, 128, 1), # 187 + 32 = 219 ) self.stage3 = nn.Sequential( conv_dw(128, 256, 2), # 219 +3 2 = 241 conv_dw(256, 256, 1), # 241 + 64 = 301 ) self.avg = nn.AdaptiveAvgPool2d((1,1)) self.fc = nn.Linear(256, 1000) def forward(self, x): x = self.stage1(x) x = self.stage2(x) x = self.stage3(x) x = self.avg(x) # x = self.model(x) x = x.view(-1, 256) x = self.fc(x) return x
代码链接:pytorch实现

 浙公网安备 33010602011771号
浙公网安备 33010602011771号