Deeplab v3+的结构的理解,图像分割最新成果
Deeplab v3+ 结构的精髓:
1.继续使用ASPP结构, SPP 利用对多种比例(rates)和多种有效感受野的不同分辨率特征处理,来挖掘多尺度的上下文内容信息. 解编码结构逐步重构空间信息来更好的捕捉物体边界.
2.添加新的解码模块,重构边界信息
3.尝试使用改进的xception模块(深度可分离卷积结构depthwise separable convolution)来作为网络的骨干,减少参数量。
结构的简单对比:

与之前相比,加入了新的解码模块,逐步精确地重构物体的边界。
其中采用的Xception模块的深度可分离卷积结构如下:由DW+PW组成,参数量和运算成本低。

DeepLabV3+ 提出的解码模块,如图:
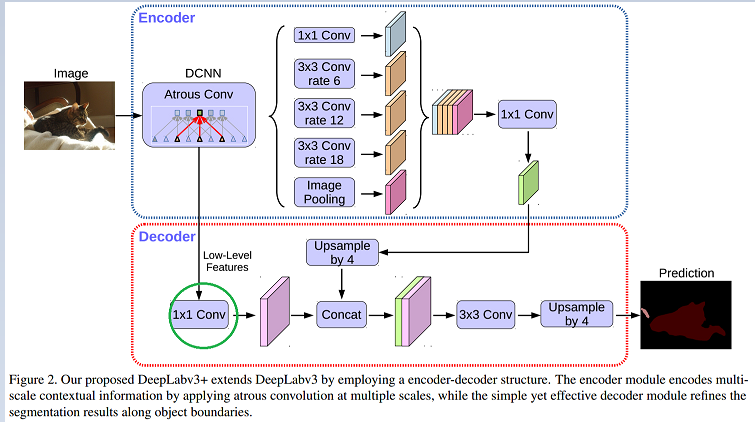
把经过ASPP以及1*1卷积之后的编码特征进行4倍上采样操作,然后拼接从主干网络中得出的相同分辨率的特征,再通过卷积以及上采样得到结果。
图中绿色圆圈的目的是,从编码过程中得到的特这个可能由多个channels,所以通过1*1的卷积降低channels数目。
改进的Xception模块:
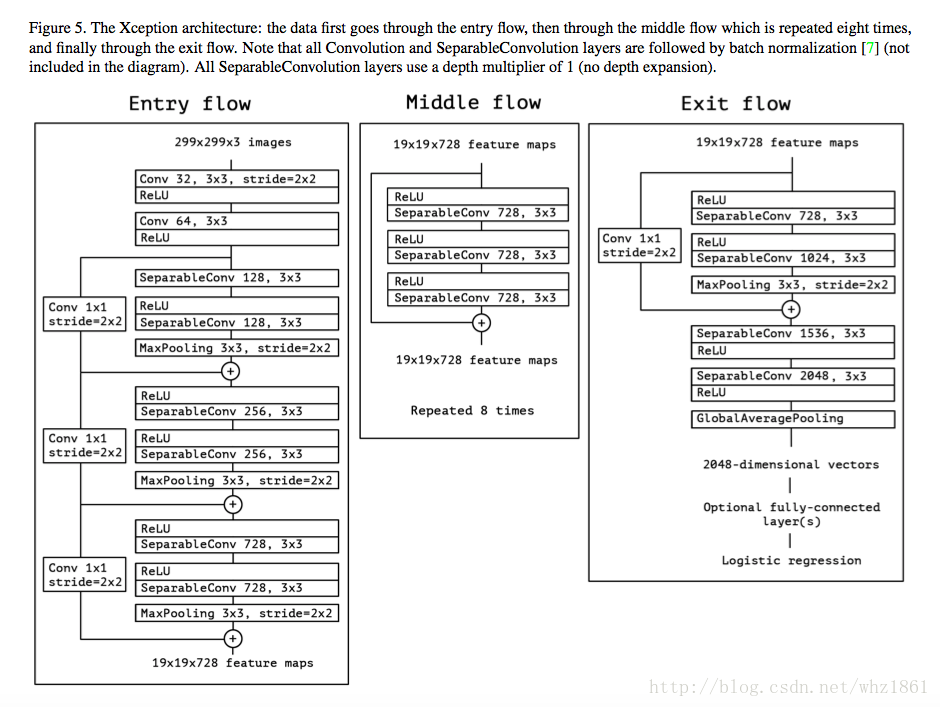
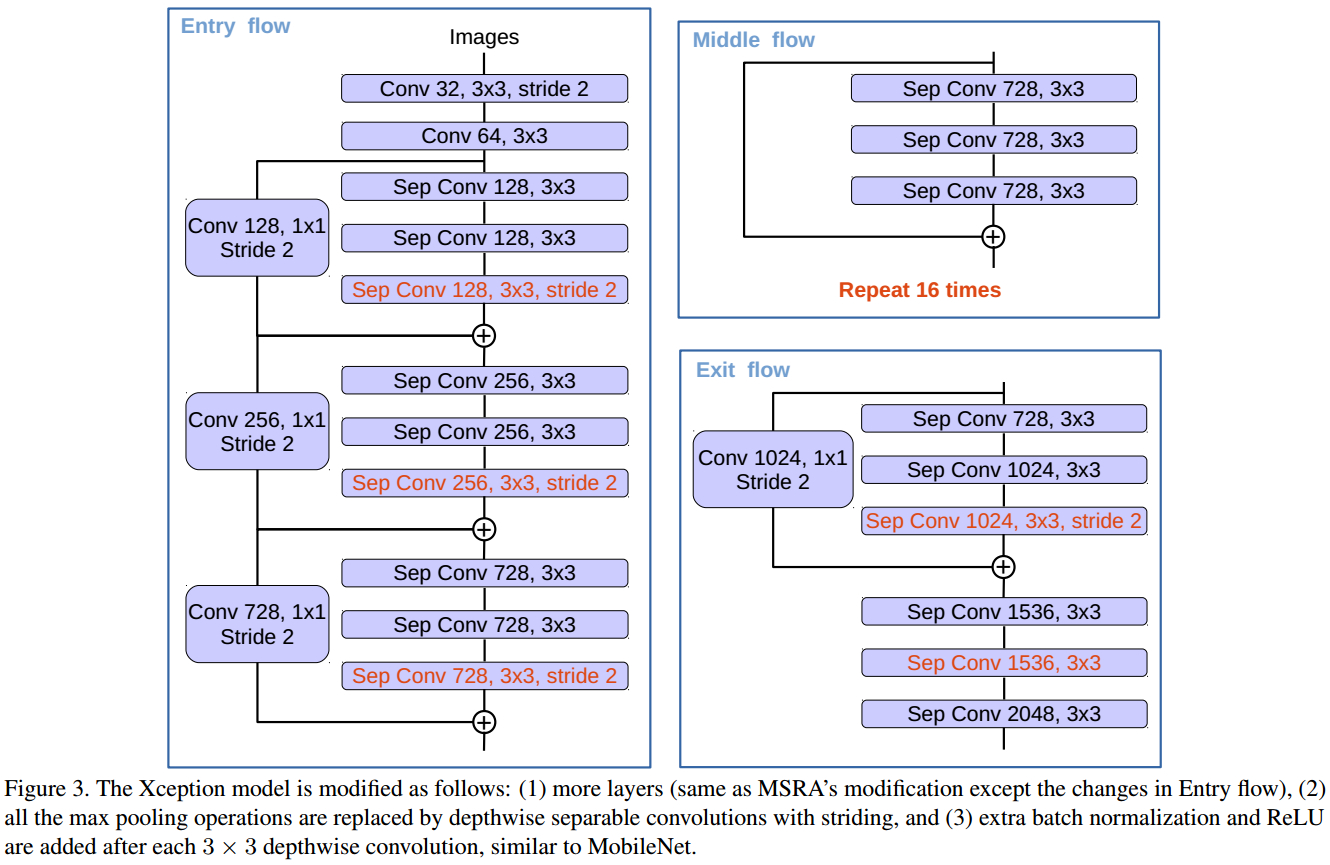
第一个为原先的xception模块,第二个为改进的;
改进的地方:
- 采用 depthwise separable conv 来替换所有的 max-pooling 操作,以利用 atrous separable conv 来提取任意分辨率的 feature maps.
- 在每个 3×3 depthwise conv 后,添加 BN 和 ReLU,类似于 MobileNet.
参考自:https://www.aiuai.cn/aifarm132.html
凤舞九天


