RNN的深入理解
针对有着前后序列关系的数据,比如说随着时间变化的数据,显然使用rnn的效果会更好。
循环神经网络的简单结构如下图:简单表示是左边这幅图,展开来看就是右边对每个时刻的数据的处理。单层的RNN网络只有一个单元,前一时刻的数据输入之后得到输出结果然后再传给自己,与下一个时序的数据一块输入。
RNN的前向传播就是一个一个时序的数据输入

RNN的计算公式如下:
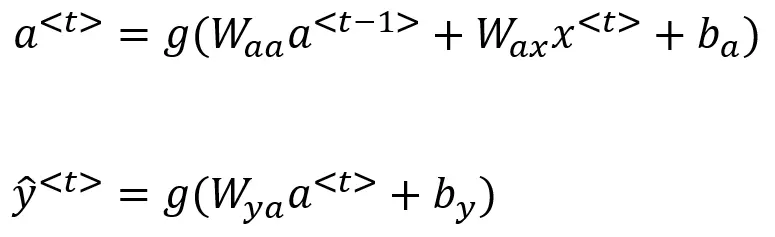
其中x<t>是当前时序的数据,W为权重,b为偏置,g是一个激活函数,a<t>是激活状态(相当于输出的初步结果),y<t>是最终输出
因此对于每个时序,RNN都是输入当前时序的输入x<t> 和来自之前时序的状态a<t-1>,x<t>可以理解为当前的信息,而a<t-1>可以理解为对之前信息的总结。
RNN存在的问题:
随着时序长度边长,rnn的深度也就变深,这样就会产生深度学习的共同问题梯度爆炸和梯度消失,梯度爆炸可以通过剪枝来解决,而梯度消失一直是很难处理的问题,这里
出现两种RNN的改进,GRU以及LSTM,这两种改进都是加入了门结构来控制信息的更新。
首先是简单的GRU,1.在GRU中,引入了记忆细胞,以提供记忆能力,能够在当前时刻联想到之前的。
2.在GRU中,a<t>和c<t>是相同的,但是在lstm中表达的含义是不同的,a<t>是激活值,c<t>是记忆细胞的值
3.在GRU中,还引入了门结构,公式中的第二个就是为了给出如何更新记忆细胞的值。
4.第三个公式可以看出,当前时刻的记忆细胞值的输入有:c-<t>以及c<t-1>和门结构

接下来是Full GRU
相比简单GRU又加入了一个门结构来控制记忆细胞的输出,r代表相关性,γr门告诉你计算出的c~<t>与c<t−1>有多大的相关性。

最后是LSTM,长短期记忆模型
经典的LSTM结构如下:

LSTM相对于GRU加入了其他的门结构,
忘记门,更新门,输出门。
计算公式如下:
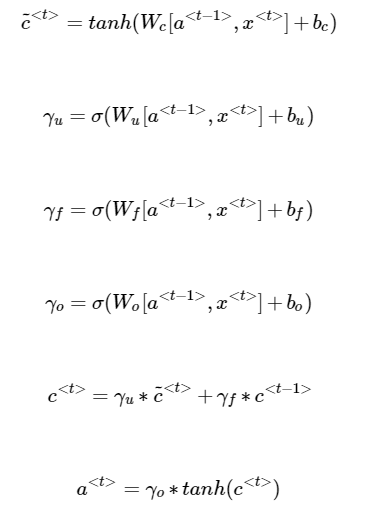
LSTM加入了三个新的门结构,使模型更加完备;
遗忘门代替上面几个模型中的(1-yu),更鲜明,但是引入了更多参数,其中每个门的输入都是a<t-1>,x<t>,每个门都是一个权值偏置后再经过一个激活函数得到输出值。
为什么LSTM能够预防梯度消失?

因为我们可以清晰地看到,在LSTM的上部长期记忆c从头到尾贯穿,每次只有更新的时候才会对它进行修改。而又因为门函数是sigmoid函数的原因,所以可以对信息进行很好的保留。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号