
SpringBoot+Elasticsearch7.7.0实战
一:什么是Elasticsearch
1.Elasticsearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java语言开发的,并作为Apache许可条款下的开放源码发布,是一种流行的企业级搜索引擎。Elasticsearch用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。官方客户端在Java、.NET(C#)、PHP、Python、Apache Groovy、Ruby和许多其他语言中都是可用的。根据DB-Engines的排名显示,Elasticsearch是最受欢迎的企业搜索引擎,其次是Apache Solr,也是基于Lucene
1.1什么是ELK?
ELK=elasticsearch+Logstash+kibana
elasticsearch:后台分布式存储以及全文检索
logstash: 日志加工、“搬运工”
kibana:数据可视化展示。
ELK架构为数据分布式存储、可视化查询和日志解析创建了一个功能强大的管理链。 三者相互配合,取长补短,共同完成分布式大数据处理工作。
2.不仅仅是全文搜索引擎
- 分布式实时文件存储,并将每一个字段都编入索引,使其可以被搜索。
- 实时分析的分布式搜索引擎。
- 可以扩展到上百台服务器,处理PB级别的结构化或非结构化数据。
二:安装并运行Elasticsearch
1.官网下载:https://www.elastic.co/cn/downloads/elasticsearch
2.解压并运行 elasticsearch.bat
3.修改配置文件elasticsearch.yml,解决与ElasticSearch-head整合跨域问题(开启跨域配置)
http.cors.enabled: true
http.cors.allow-origin: "*"

3:ElasticSearch-head 插件安装:在GitHub上找到head插件,地址:https://github.com/mobz/elasticsearch-head。将其下载/克隆到本地(elasticsearch-head)
# 安装插件;由于需要下载一些数据,所以可能会比较慢。
npm install
# 启动
npm run start
4:ES运行成功页面
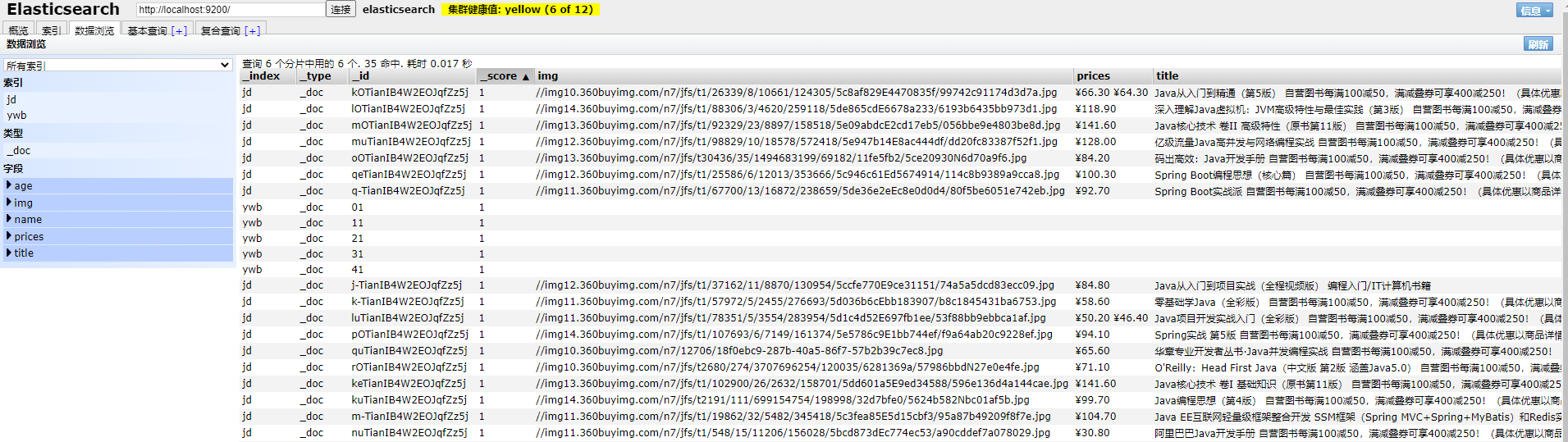
5:运行Kibana(进入config下的kibana.yml 修改配置为)
# 本机的端口
server.port: 5601
# 本机IP地址
server.host: "127.0.0.1"
# ES的服务IP+端口
elasticsearch.hosts: ["http://localhost:9200"]
启动命令
.\kibana.bat
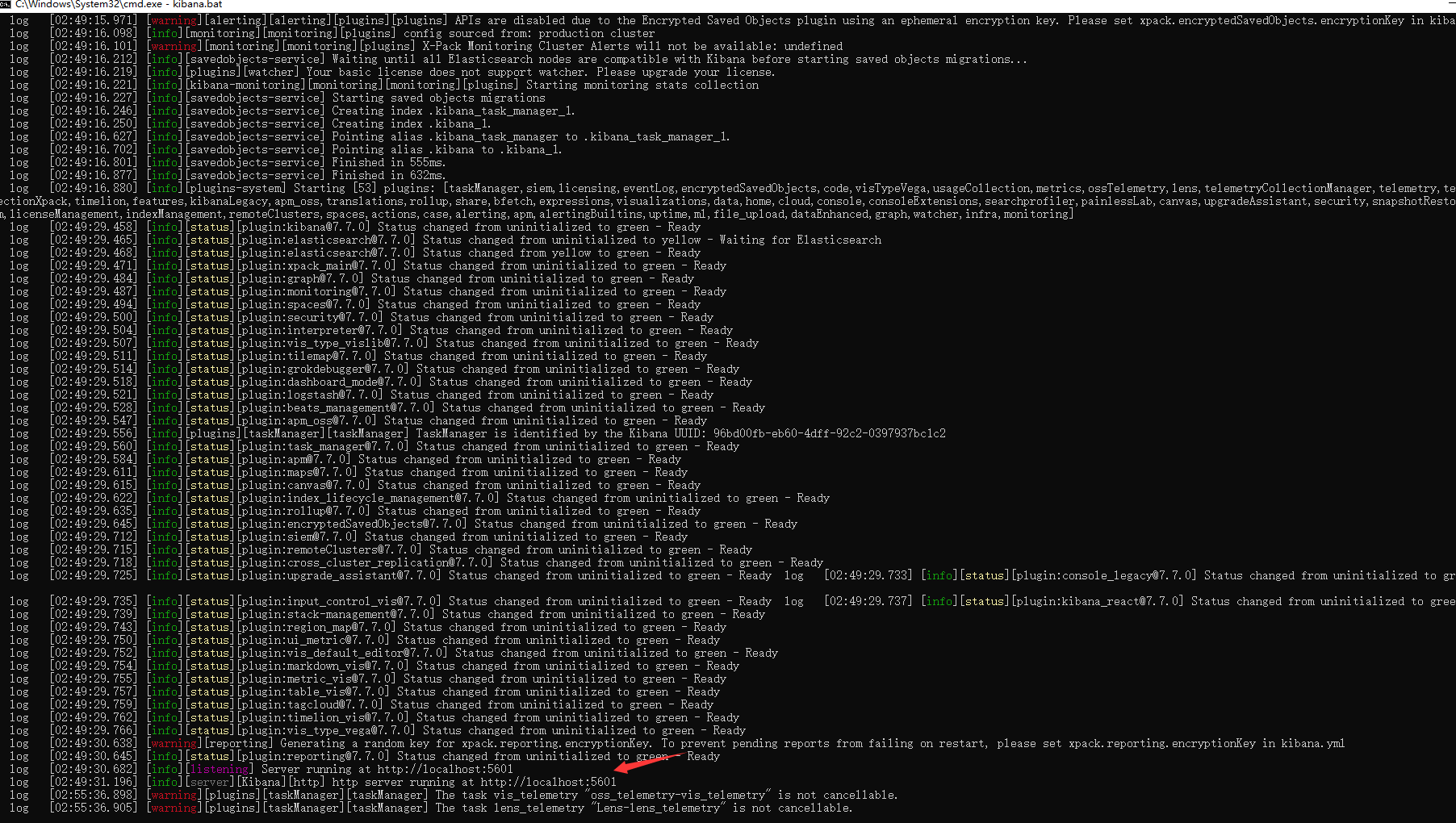
6:Kibana运行成功页面(http://localhost:5601/app/kibana#/home)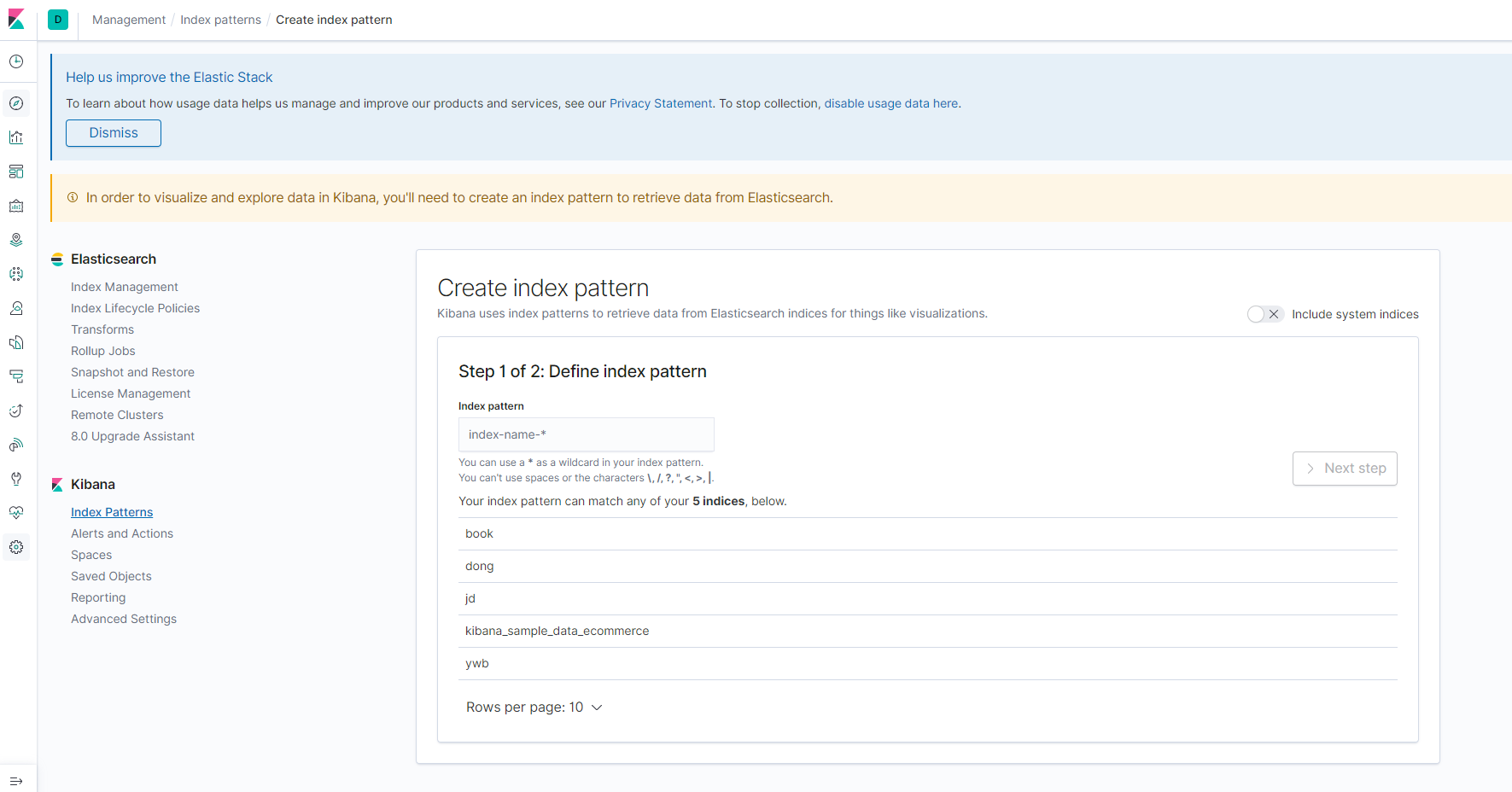
7:运行Logstash(进入E:\ELK\logstash-7.7.0\config 新建配置文件logstash.conf 修改内容如下)
input {
file {
type => "nginx_access"
path => "E:/ELK/logs/logstash.log"
}
}
output {
elasticsearch {
hosts => ["127.0.0.1:9200"]
index => "access-%{+YYYY.MM.dd}"
}
stdout {
codec => json_lines
}
}
8:启动logstash
.\logstash.bat -f ../config/logstash.conf
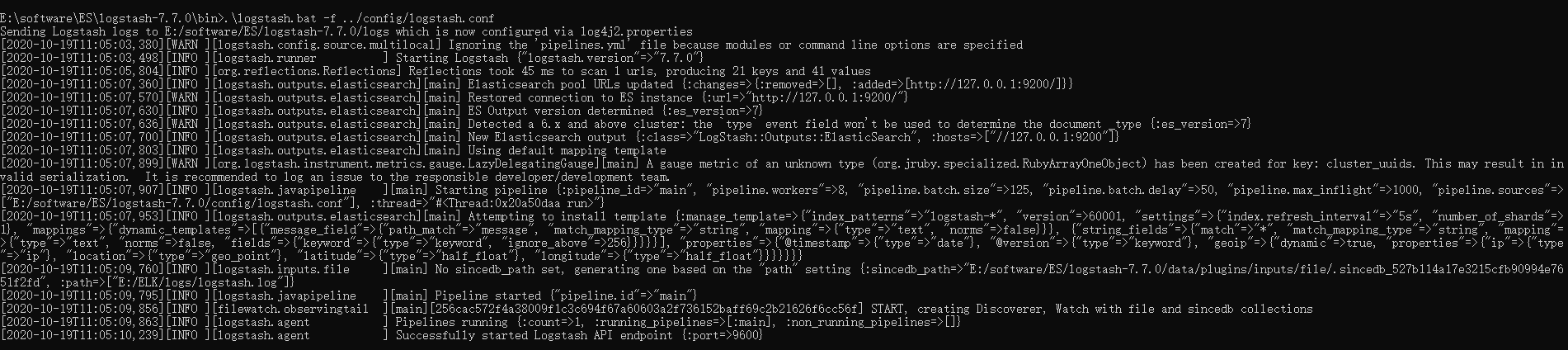
9:logback_spring.xml
<?xml version="1.0" encoding="UTF-8"?>
<!--scan: 为true时,配置文档如果发生改变,将会被重新加载,默认值true
scanPeriod: 设置监测配置文档是否有修改的时间间隔,如果没有给出单位,默认毫秒。 为true时生效,默认时间间隔1分钟
debug: 为true时,将打印出logback内部日志信息,实时查看logback运行状态。默认值false -->
<configuration scan="true" scanPeriod="10 seconds" debug="false">
<contextName>logback</contextName>
<!-- 属性值会被插入到上下文中,在下面配置中可以使“${}”来使用 -->
<!-- 格式化输出:%d表示日期,%thread表示线程名,%-5level:级别从左显示5个字符宽度 %msg:日志消息,%n是换行符 -->
<!-- <property name="LOG.PATTERN" value="[%d{yyyy-MM-dd HH:mm:ss.SSS}] [%-5level] [%15.15thread] [%45.45file{15}\(%-4line\\) - %-45.45logger{15}] : %msg%n" /> -->
<property name="LOG.PATTERN" value="[%d{yyyy-MM-dd HH:mm:ss.SSS}] [%-5level] %15.15thread -- %-45.45logger{15} : %msg%n"/>
<!-- 日志文件 -->
<property name="LOG.PATH" value="E:/ELK/logs/logstash.log"/>
<property name="LOG.FILE.DEBUG" value="${LOG.PATH}/debug.log"/>
<property name="LOG.FILE.INFO" value="${LOG.PATH}/info.log"/>
<property name="LOG.FILE.WARN" value="${LOG.PATH}/warn.log"/>
<property name="LOG.FILE.ERROR" value="${LOG.PATH}/error.log"/>
<property name="LOG.FILE.NAME" value="springboot.%d{yyyy-MM-dd}.%i.log"/>
<!-- 输出日志到控制台 -->
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<Pattern>${LOG.PATTERN}</Pattern>
<charset>UTF-8</charset>
</encoder>
<filter class="ch.qos.logback.classic.filter.ThresholdFilter">
<level>INFO</level>
</filter>
</appender>
<!-- 输出日志到文件:DEBUG -->
<appender name="FILE-DEBUG" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${LOG.FILE.DEBUG}</file>
<append>true</append>
<encoder>
<Pattern>${LOG.PATTERN}</Pattern>
<charset>UTF-8</charset>
</encoder>
<!-- 日志记录级别 -->
<filter class="ch.qos.logback.classic.filter.LevelFilter">
<level>DEBUG</level>
<onMatch>ACCEPT</onMatch>
<onMismatch>DENY</onMismatch>
</filter>
<!-- 时间滚动策略 -->
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<timeBasedFileNamingAndTriggeringPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedFNATP">
<maxFileSize>100MB</maxFileSize>
</timeBasedFileNamingAndTriggeringPolicy>
<!-- 保留天数 -->
<maxHistory>7</maxHistory>
<fileNamePattern>${LOG.FILE.DEBUG}/${LOG.FILE.NAME}</fileNamePattern>
</rollingPolicy>
</appender>
<!-- 输出日志到文件:INFO -->
<appender name="FILE-INFO" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${LOG.FILE.INFO}</file>
<append>true</append>
<encoder>
<Pattern>${LOG.PATTERN}</Pattern>
<charset>UTF-8</charset>
</encoder>
<!-- 日志记录级别 -->
<filter class="ch.qos.logback.classic.filter.LevelFilter">
<level>INFO</level>
<onMatch>ACCEPT</onMatch>
<onMismatch>DENY</onMismatch>
</filter>
<!-- 时间滚动策略 -->
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<timeBasedFileNamingAndTriggeringPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedFNATP">
<maxFileSize>100MB</maxFileSize>
</timeBasedFileNamingAndTriggeringPolicy>
<!-- 保留天数 -->
<maxHistory>7</maxHistory>
<fileNamePattern>${LOG.FILE.INFO}/${LOG.FILE.NAME}</fileNamePattern>
</rollingPolicy>
</appender>
<!-- 输出日志到文件:ERROR -->
<appender name="FILE-ERROR" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${LOG.FILE.ERROR}</file>
<append>true</append>
<encoder>
<Pattern>${LOG.PATTERN}</Pattern>
<charset>UTF-8</charset>
</encoder>
<!-- 日志记录级别 -->
<filter class="ch.qos.logback.classic.filter.LevelFilter">
<level>ERROR</level>
<onMatch>ACCEPT</onMatch>
<onMismatch>DENY</onMismatch>
</filter>
<!-- 时间滚动策略 -->
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<timeBasedFileNamingAndTriggeringPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedFNATP">
<maxFileSize>100MB</maxFileSize>
</timeBasedFileNamingAndTriggeringPolicy>
<!-- 保留天数 -->
<maxHistory>7</maxHistory>
<fileNamePattern>${LOG.FILE.ERROR}/${LOG.FILE.NAME}</fileNamePattern>
</rollingPolicy>
</appender>
<!-- 输出日志到文件:WARN -->
<appender name="FILE-WARN" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${LOG.FILE.WARN}</file>
<append>true</append>
<encoder>
<Pattern>${LOG.PATTERN}</Pattern>
<charset>UTF-8</charset>
</encoder>
<!-- 日志记录级别 -->
<filter class="ch.qos.logback.classic.filter.LevelFilter">
<level>WARN</level>
<onMatch>ACCEPT</onMatch>
<onMismatch>DENY</onMismatch>
</filter>
<!-- 时间滚动策略 -->
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<timeBasedFileNamingAndTriggeringPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedFNATP">
<maxFileSize>100MB</maxFileSize>
</timeBasedFileNamingAndTriggeringPolicy>
<!-- 保留天数 -->
<maxHistory>7</maxHistory>
<fileNamePattern>${LOG.FILE.WARN}/${LOG.FILE.NAME}</fileNamePattern>
</rollingPolicy>
</appender>
<!-- 下面配置一些第三方包的日志过滤级别,用于避免刷屏-->
<Logger name="org.springframework" level="INFO"/>
<Logger name="org.springframework.beans.factory.aspectj" level="WARN"/>
<Logger name="org.springframework.transaction.interceptor" level="WARN"/>
<Logger name="org.springframework.beans.factory.support" level="WARN"/>
<Logger name="org.springframework.web.servlet" level="DEBUG"/>
<Logger name="org.springframework.transaction" level="WARN"/>
<Logger name="org.springframework.jdbc.datasource.DataSourceTransactionManager" level="WARN"/>
<Logger name="org.springframework.transaction.support.AbstractPlatformTransactionManager" level="WARN"/>
<Logger name="org.springframework.security" level="WARN"/>
<Logger name="org.apache.commons" level="WARN"/>
<Logger name="org.apache.kafka" level="WARN"/>
<Logger name="org.apache.http" level="ERROR"/>
<Logger name="org.logicalcobwebs" level="WARN"/>
<Logger name="httpclient" level="ERROR"/>
<Logger name="net.sf.ehcache" level="WARN"/>
<Logger name="org.apache.zookeeper" level="WARN"/>
<Logger name="org.I0Itec" level="WARN"/>
<Logger name="com.meetup.memcached" level="WARN"/>
<Logger name="org.mongodb.driver" level="INFO"/>
<Logger name="org.quartz.core" level="INFO"/>
<Logger name="io.netty" level="INFO"/>
<Logger name="net.rubyeye.xmemcached" level="WARN"/>
<Logger name="com.google" level="WARN"/>
<logger name="com.ibatis" level="DEBUG"/>
<logger name="com.ibatis.common.jdbc.SimpleDataSource" level="DEBUG"/>
<logger name="com.ibatis.common.jdbc.ScriptRunner" level="DEBUG"/>
<logger name="com.ibatis.sqlmap.engine.impl.SqlMapClientDelegate" level="DEBUG"/>
<logger name="java.sql.Connection" level="DEBUG"/>
<logger name="java.sql.Statement" level="DEBUG"/>
<logger name="java.sql.PreparedStatement" level="DEBUG"/>
<logger name="com.es.elsaticsearch" level="DEBUG"/>
<!-- 生产环境下,将此级别配置为适合的级别,以免日志文件太多或影响程序性能
level取值:TRACE < DEBUG < INFO < WARN < ERROR < FATAL 和 OFF -->
<root level="INFO">
<appender-ref ref="FILE-DEBUG"/>
<appender-ref ref="FILE-INFO"/>
<appender-ref ref="FILE-ERROR"/>
<appender-ref ref="FILE-WARN"/>
<!-- 生产环境将请console去掉 -->
<appender-ref ref="CONSOLE"/>
</root>
</configuration>
ES核心概念
索引
字段类型(mapping)
文档(document)
elasticsearch是面向文档,一切数据都是json,与关系型数据库对比
| DB | ElasticSearch |
| 数据库(database) | 索引 |
| 表(table) | types |
| 行(rows) | documents |
| 字段(columns) | fields |
三:springboot整合ElasticSearch7.7.0
1.添加maven依赖
<properties>
<java.version>1.8</java.version>
<elasticsearch.version>7.7.0</elasticsearch.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
</dependencies>
2.编写配置类(ES可以作为一个独立的单个搜索服务器。不过,为了处理大型数据集,实现容错和高可用性,ES可以运行在许多互相合作的服务器上【集群】),本案例是单个服务器
/**
* @author : ywb
* @createdDate : 2020/5/31
* @updatedDate
*/
@Configuration
public class ElasticSearchConfig {
@Bean
public RestHighLevelClient restHighLevelClient() {
RestHighLevelClient restHighLevelClient = new RestHighLevelClient(
RestClient.builder(
new HttpHost("localhost", 9200, "http")
)
);
return restHighLevelClient;
}
}
3:ES对索引、文档进行增删改查(java对ES操作的基本API)
@RunWith(SpringRunner.class)
@SpringBootTest
public class ElasticsearchApplicationTests {
@Autowired
private RestHighLevelClient restHighLevelClient;
//创建索引
@Test
public void testCreateIndex() throws IOException {
CreateIndexRequest createIndexRequest = new CreateIndexRequest("ywb");
CreateIndexResponse response = restHighLevelClient.indices().create(createIndexRequest, RequestOptions.DEFAULT);
System.out.println(response);
}
/**
* 测试索引是否存在
*
* @throws IOException
*/
@Test
public void testExistIndex() throws IOException {
GetIndexRequest request = new GetIndexRequest("ywb");
boolean exists = restHighLevelClient.indices().exists(request, RequestOptions.DEFAULT);
System.out.println(exists);
}
/**
* 删除索引
*/
@Test
public void deleteIndex() throws IOException {
DeleteIndexRequest deleteIndexRequest = new DeleteIndexRequest("ywb");
AcknowledgedResponse delete = restHighLevelClient.indices().delete(deleteIndexRequest, RequestOptions.DEFAULT);
System.out.println(delete.isAcknowledged());
}
/**
* 测试添加文档
*
* @throws IOException
*/
@Test
public void createDocument() throws IOException {
User user = new User("ywb", 18);
IndexRequest request = new IndexRequest("ywb");
request.id("1");
request.timeout(TimeValue.timeValueSeconds(1));
request.timeout("1s");
//将我们的数据放入请求,json
request.source(JSON.toJSONString(user), XContentType.JSON);
//客服端发送请求
IndexResponse index = restHighLevelClient.index(request, RequestOptions.DEFAULT);
System.out.println(index.toString());
//对应我们的命令返回状态
System.out.println(index.status());
}
//判断是否存在文档
@Test
public void testIsExist() throws IOException {
GetRequest getRequest = new GetRequest("ywb", "1");
//不获取返回的source的上下文
getRequest.fetchSourceContext(new FetchSourceContext(false));
getRequest.storedFields("_none_");
boolean exists = restHighLevelClient.exists(getRequest, RequestOptions.DEFAULT);
System.out.println(exists);
}
//获取文档信息
@Test
public void testGetDocument() throws IOException {
GetRequest getRequest = new GetRequest("ywb", "1");
GetResponse response = restHighLevelClient.get(getRequest, RequestOptions.DEFAULT);
//打印文档信息
System.out.println(response.getSourceAsString());
System.out.println(response);
}
//更新文档信息
@Test
public void testUpdateDocument() throws IOException {
UpdateRequest request = new UpdateRequest("ywb", "1");
request.timeout("1s");
User user = new User("ywb java", 19);
request.doc(JSON.toJSONString(user), XContentType.JSON);
UpdateResponse update = restHighLevelClient.update(request, RequestOptions.DEFAULT);
System.out.println(update);
System.out.println(update.status());
}
//删除文档
@Test
public void testDeleteDocument() throws IOException {
DeleteRequest request = new DeleteRequest("ywb", "1");
request.timeout("10s");
User user = new User("ywb java", 19);
DeleteResponse update = restHighLevelClient.delete(request, RequestOptions.DEFAULT);
System.out.println(update.status());
}
//批量插入数据
@Test
public void testBulkRequest() throws IOException {
BulkRequest bulkRequest = new BulkRequest();
bulkRequest.timeout("10s");
ArrayList<User> users = new ArrayList<>();
users.add(new User("zhangsan", 1));
users.add(new User("lishi", 12));
users.add(new User("wangwu", 13));
users.add(new User("zhaoliu", 14));
users.add(new User("tianqi", 15));
for (int i = 0; i < users.size(); i++) {
bulkRequest.add(
new IndexRequest("ywb")
.id("" + i + 1)
.source(JSON.toJSONString(users.get(i)), XContentType.JSON)
);
}
BulkResponse bulk = restHighLevelClient.bulk(bulkRequest, RequestOptions.DEFAULT);
System.out.println(bulk);
}
}
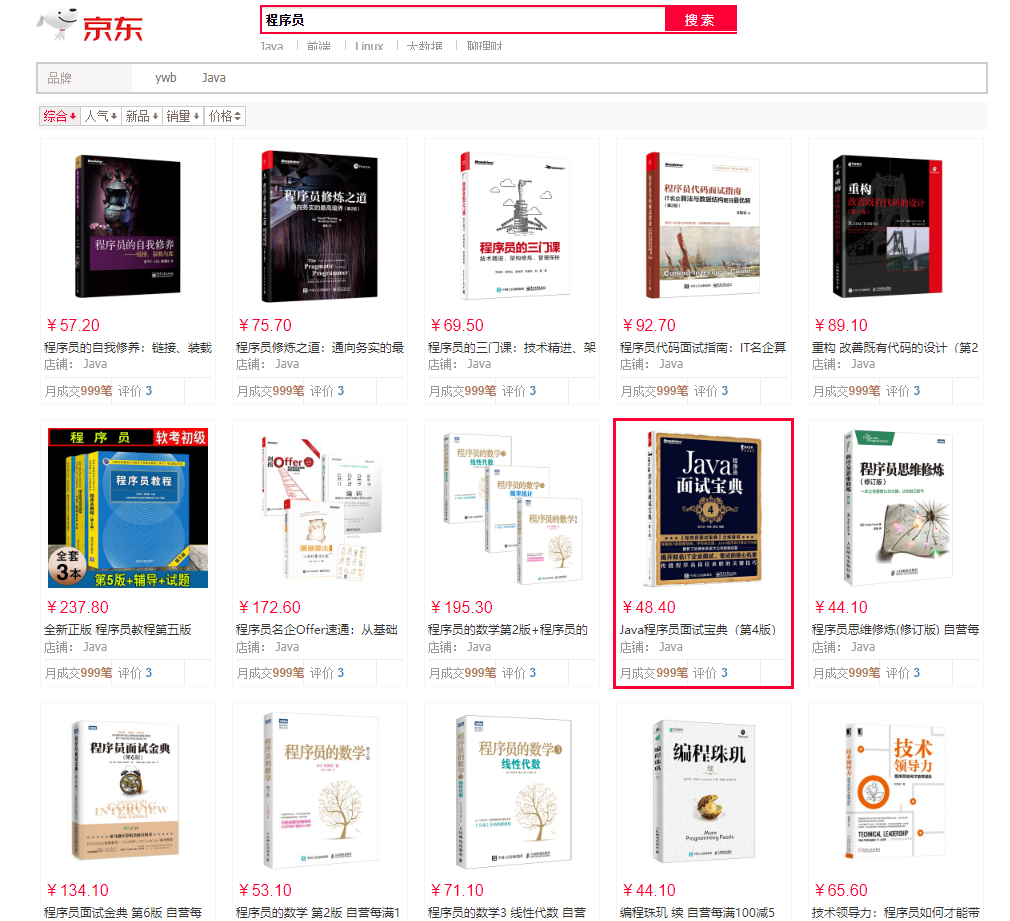
四:1实战(爬取京东网页数据,添加至ElasticSearch)
<!-- 解析网页-->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.10.2</version>
</dependency>
2:工具类
/**
* @author : ywb
* @createdDate : 2020/5/31
* @updatedDate
*/
@Component
public class HtmlParseUtils {
/**
* 爬取京东商城搜索数据
* @param keyWork
* @return
* @throws IOException
*/
public List<Content> listGoods(String keyWork) throws IOException {
String url = "https://search.jd.com/Search?keyword="+keyWork;
Document document = Jsoup.parse(new URL(url),30000);
Element element = document.getElementById("J_goodsList");
Elements li = element.getElementsByTag("li");
List<Content> list = new ArrayList<>();
for (Element elements : li) {
String img = elements.getElementsByTag("img").eq(0).attr("src");
String price = elements.getElementsByClass("p-price").eq(0).text();
String title = elements.getElementsByClass("p-name").eq(0).text();
Content content = new Content();
content.setImg(img);
content.setPrices(price);
content.setTitle(title);
list.add(content);
}
return list;
}
}
3:service(查询京东数据,存储到ES,并显示页面)
/**
* @author : ywb
* @createdDate : 2020/5/31
* @updatedDate
*/
@Service
public class ContentService {
@Autowired
private HtmlParseUtils htmlParseUtils;
@Autowired
@Qualifier("restHighLevelClient")
private RestHighLevelClient client;
/**
* 插叙数据
* @param keyWords
* @return
* @throws IOException
*/
public Boolean parseContent(String keyWords) throws IOException {
List<Content> contents = htmlParseUtils.listGoods("java");
BulkRequest bulkRequest = new BulkRequest();
bulkRequest.timeout("2m");
for (int i = 0; i < contents.size(); i++) {
bulkRequest.add(
new IndexRequest("jd")
.source(JSON.toJSONString(contents.get(i)), XContentType.JSON));
}
BulkResponse bulk = client.bulk(bulkRequest, RequestOptions.DEFAULT);
return !bulk.hasFailures();
}
/**
* 分页查询ElasticSearch数据,并高亮显示
* @param keyWords
* @param pageNum
* @param pageSize
* @return
* @throws IOException
*/
public List<Map<String,Object>> searchPage(String keyWords,Integer pageNum,Integer pageSize) throws IOException {
if(pageNum<=1){
pageNum=1;
}
SearchRequest searchRequest = new SearchRequest("jd");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
//分页
sourceBuilder.from(pageNum);
sourceBuilder.size(pageSize);
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("title",keyWords);
sourceBuilder.query(termQueryBuilder);
sourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
//高亮
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder.field("title");
//多个高亮显示设置为true
highlightBuilder.requireFieldMatch(false);
highlightBuilder.preTags("<span style = 'color:red'>");
highlightBuilder.postTags("</span>");
sourceBuilder.highlighter(highlightBuilder);
//执行搜索
searchRequest.source(sourceBuilder);
SearchResponse search = client.search(searchRequest, RequestOptions.DEFAULT);
//解析结果
List<Map<String, Object>> maps = new ArrayList<>();
for (SearchHit hit : search.getHits().getHits()) {
Map<String, HighlightField> highlightFields = hit.getHighlightFields();
HighlightField title = highlightFields.get("title");
//原来的结果
Map<String, Object> sourceAsMap = hit.getSourceAsMap();
//解析高亮字段 ,将原来的字段换成高亮字段显示
if(title!=null){
Text[] fragments = title.fragments();
String newTitle = "";
for (Text fragment : fragments) {
newTitle+=fragment;
}
//高亮字段替换原来内容
sourceAsMap.put("title",newTitle);
}
maps.add(hit.getSourceAsMap());
}
return maps;
}
}
结果:

五、为了部署简单使用docker-compose启动程序
5.1:编写docker-compose.yaml
version: '3'
services:
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch:7.12.1
container_name: elasticsearch_server
restart: always
environment:
- discovery.type=single-node
- discovery.zen.minimum_master_nodes=1
- ES_JAVA_OPTS=-Xms3g -Xmx3g
volumes:
- ./elasticsearch/data:/usr/share/elasticsearch/data
ports:
- 9200:9200
networks:
elk_net: # 指定使用的网络
aliases:
- elasticsearch # 该容器的别名,在 elk_net 网络中的其他容器可以通过别名 elasticsearch 来访问到该容器
kibana:
image: docker.elastic.co/kibana/kibana:7.12.1
container_name: kibana_server
ports:
- "5601:5601"
restart: always
networks:
elk_net:
aliases:
- kibana
environment:
- ELASTICSEARCH_URL=http://elasticsearch:9200
- SERVER_NAME=kibana
# 如需具体配置,可以创建./config/kibana.yml,并映射
# # volumes:
# # - ./config/kibana.yml:/usr/share/kibana/config/kibana.yml
depends_on:
- elasticsearch
logstash:
image: docker.elastic.co/logstash/logstash:7.12.1
container_name: logstash_server
restart: always
environment:
- LS_JAVA_OPTS=-Xmx256m -Xms256m
volumes:
- ./config/logstash.conf:/etc/logstash/conf.d/logstash.conf
networks:
elk_net:
aliases:
- logstash
depends_on:
- elasticsearch
entrypoint:
- logstash
- -f
- /etc/logstash/conf.d/logstash.conf
logging:
driver: "json-file"
options:
max-size: "200m"
max-file: "3"
networks:
elk_net:
external:
name: elk_net
5.2:docker-compose up -d

5.3:docker ps


<<圆规为什么可以画圆?因为脚在走,心不变。你为什么不能圆梦?因为心不定,脚不动!坚定信念和坚持选择比什么都重要>>

 浙公网安备 33010602011771号
浙公网安备 33010602011771号