章节八:爬取知乎文章
章节八:爬取知乎文章
你造吗,今天是个大喜的日子!来到这儿,就意味着你爬虫已经入门啦!
在这个重要又喜悦的日子里,我们就干三件事:回顾前路、项目实操、展望未来。
回顾前路,是为了复习1-7关所学的知识。项目实操,是通过写一个爬虫程序把所学的知识用起来。展望未来,是预告一下我们之后会遇到的风景。
马上开始吧~
1. 回顾前路
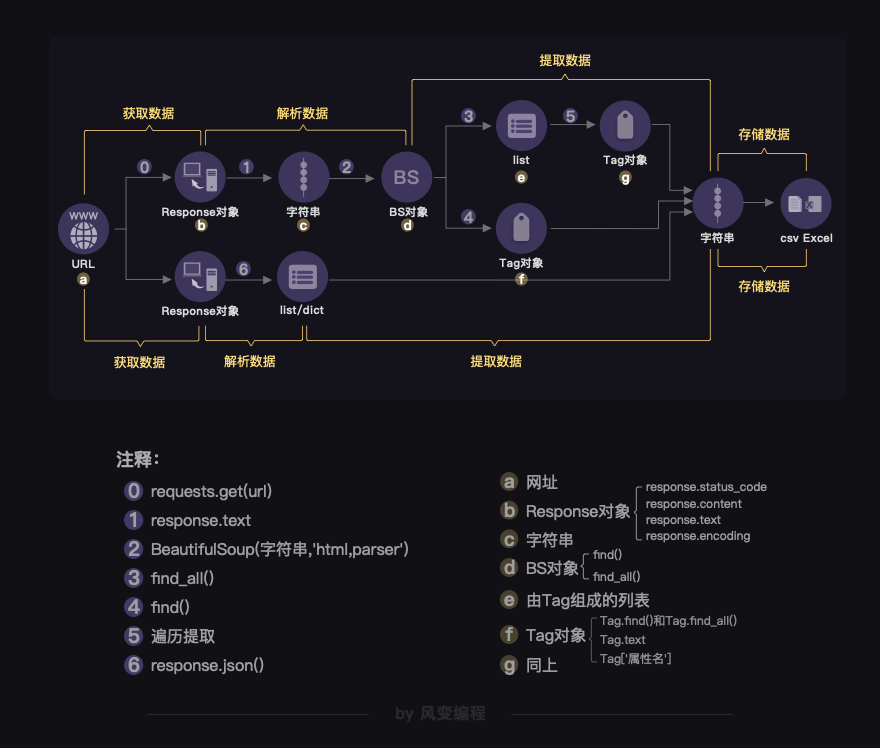
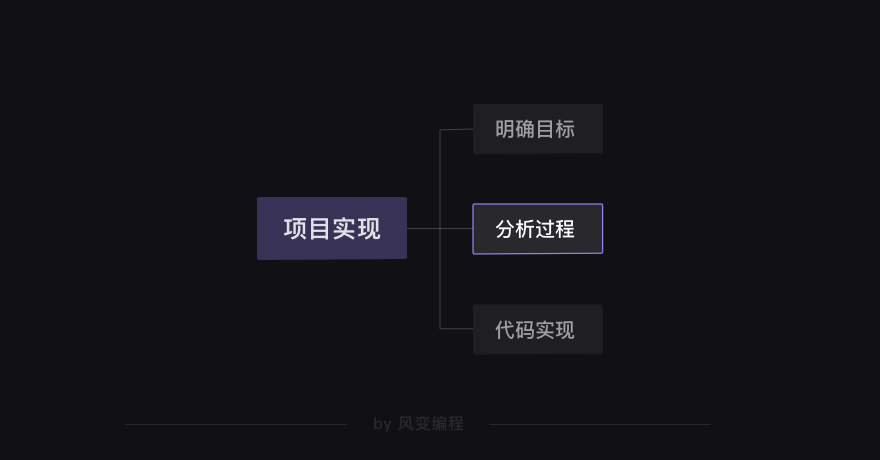
在前面,我们按关卡学了好多好多知识。而这么多的内容,我们用【项目实现】和【知识地图】两张图就能说清。
【项目实现】: 任何完成项目的过程,都是由以下三步构成的。
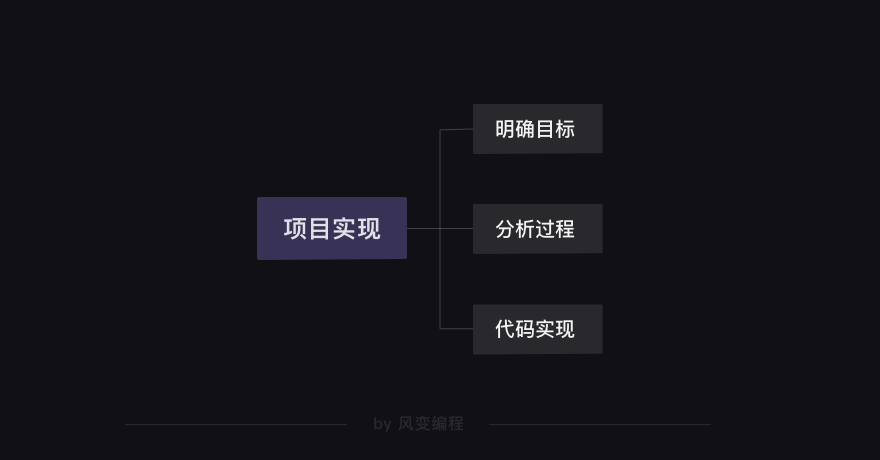
先需要明确自己的目标是什么,然后分析一下如何实现这个目标,最后就可以去写代码了。
当然,这不是一个线性的过程,而可能出现“代码实现”碰壁后然后折返“分析过程”,再“代码实现”的情形。
接下来是【知识地图】:前面6关所讲的爬虫原理,在本质上,是一个我们所操作的对象在不断转换的过程。
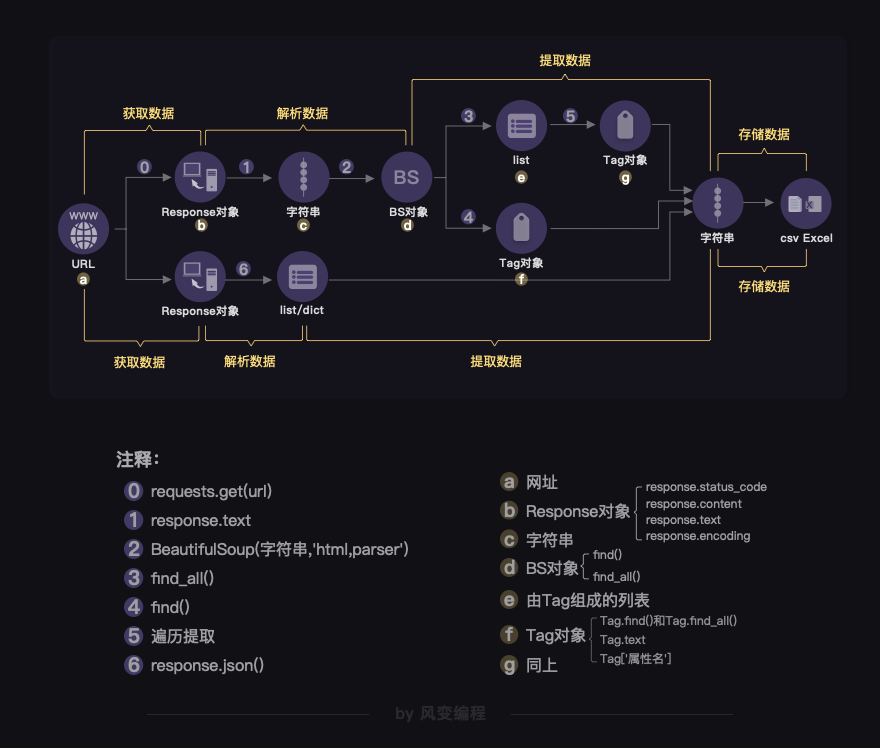
总体上来说,从Response对象开始,我们就分成了两条路径,一条路径是数据放在HTML里,所以我们用BeautifulSoup库去解析数据和提取数据;另一条,数据作为Json存储起来,所以我们用response.json()方法去解析,然后提取、存储数据。
你需要根据具体的情况,来确定自己应该选择哪一条路径。
也可以参考图片上的注释,帮助自己去回忆不同对象的方法和属性。不过,老师还是希望你能把这个图记在心里。
好啦,1-7关的内容就梳理完成啦~
接下来是项目实操,这是今天的重头戏。
2. 项目实操
我们会按照刚刚提过的项目三步骤来,首先是明确目标。
2.1 明确目标
为了让大家能把前面所学全都复习一遍,老师为大家准备了一个项目:爬取知乎大v张佳玮的文章“标题”、“摘要”、“链接”,并存储到本地文件。
之所以选这个项目,是为了让大家能把前面所学全都复习一遍。
知道目标后,就可以【分析过程】了。
2.2 分析过程
张佳玮的知乎文章URL在这里:https://www.zhihu.com/people/zhang-jia-wei/posts?page=1。
这是我做这个项目时,网站显示的内容。
点击右键——检查——Network,选All(而非XHR),然后刷新网页,点进去第0个请求:post?page=1,点Preview。
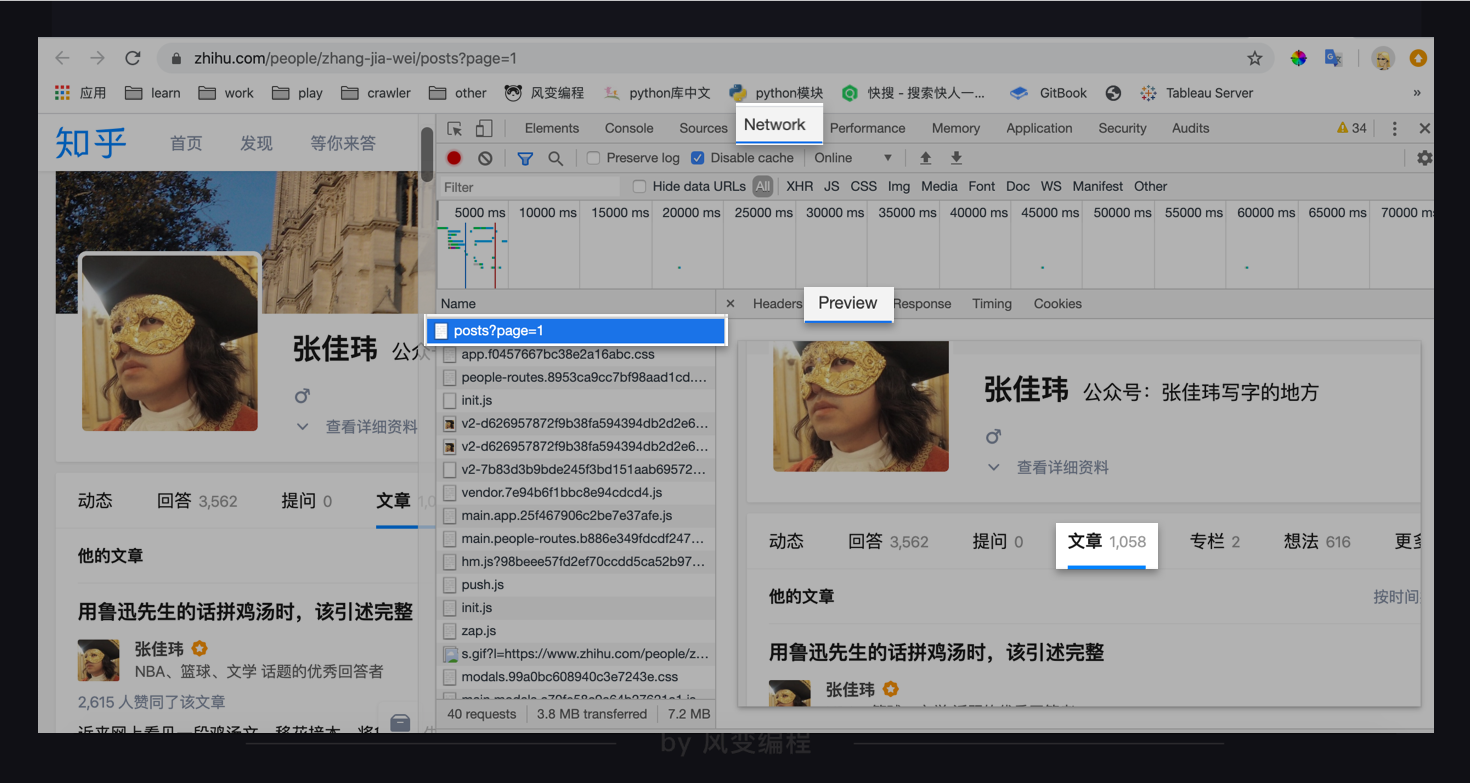
发现有文章标题,看来数据是放在HTML里。
那么,走的应该是【知识地图】里上面那条路径:
那好,就可以去观察一下网页源代码了,我们点回Elements。
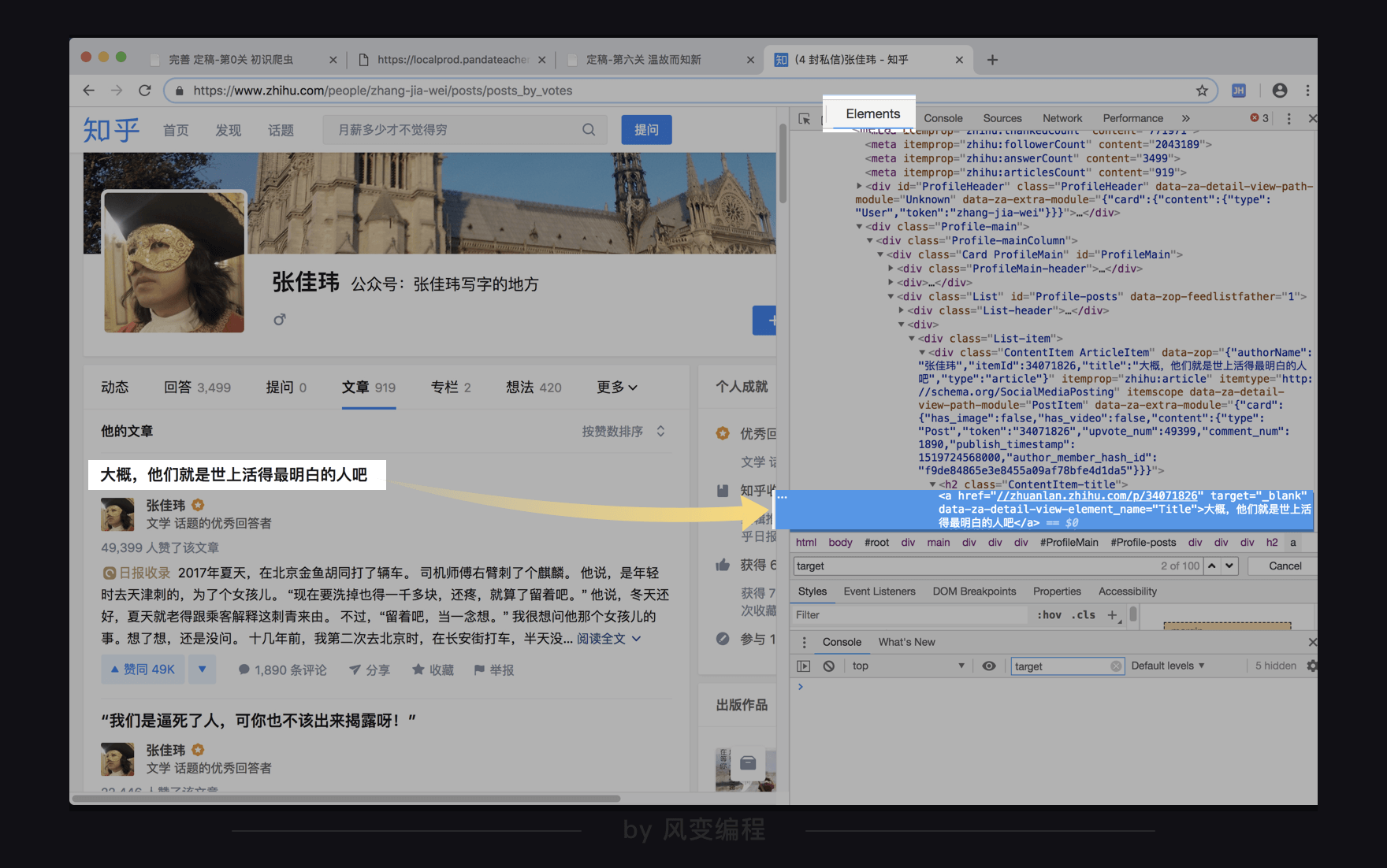
上图左边的文章标题对应的就是上图右边的a元素里面的文本“大概,他们就是世上活得最明白的人吧。”还可以看到在<a>标签里面,还有属性target="_blank",和data-za-detail-view-element_name="Title"。
对于target="_blank"属性,我们按下ctrl+f去搜索属性名target或属性值"_blank":
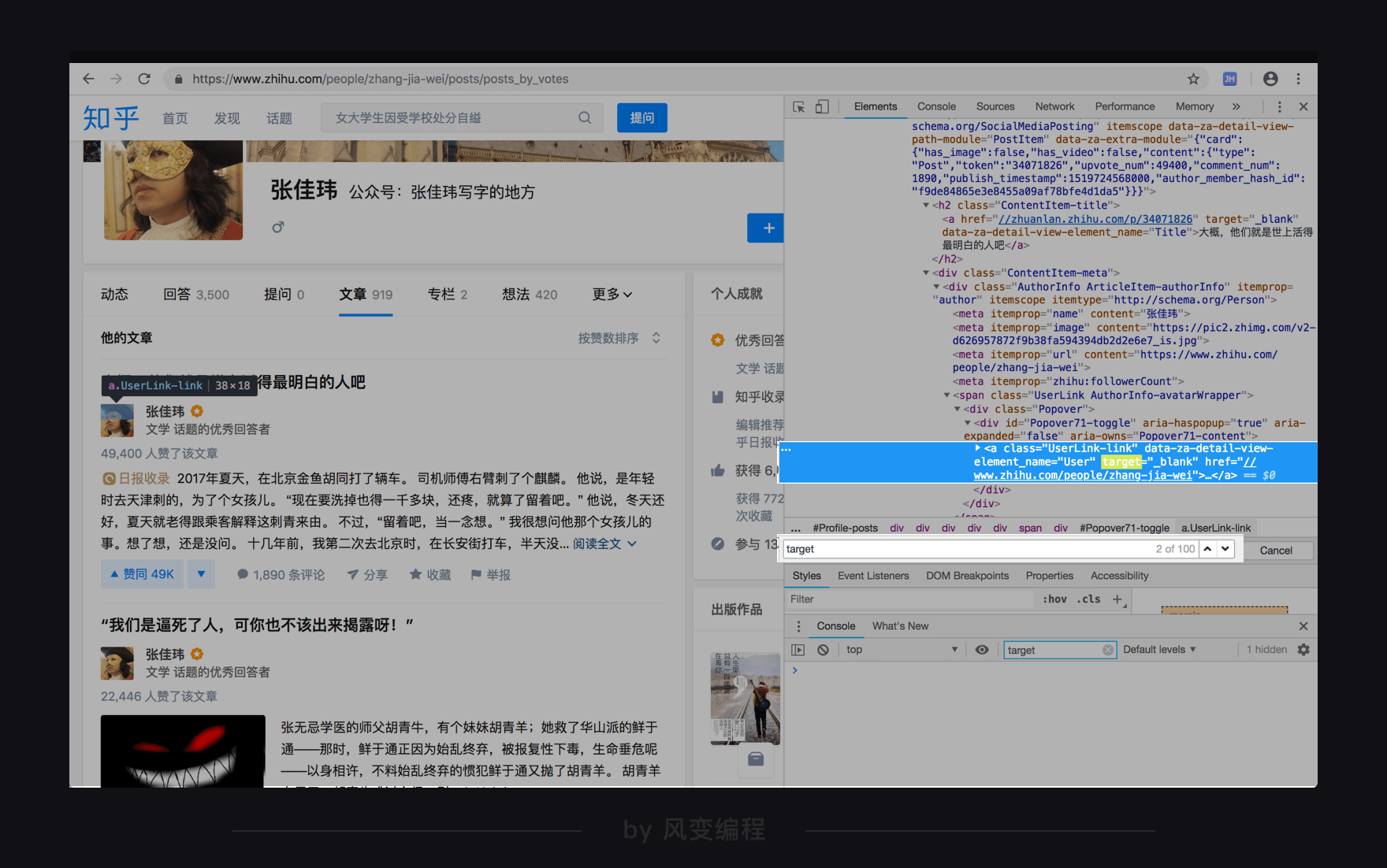
用上下箭头翻看一下搜索结果,发现这个target属性并不能帮我们精准地定位到文章标题,所以排除使用这个属性。
事实上超链接标签<a>的target属性指示的是在哪里打开跳转的目标网页,"_blank"表示每点击一次(超链接)打开一个新窗口。从搜索结果看,显然需要这个指示的不止文章标题。
而对于另一个属性data-za-detail-view-element_name="Title",属性值"Title"倒是在疯狂明示自己是个“标题”,但属性名如此freestyle,应该是由知乎的开发人员自定义命名,并不是html语法里标准的属性名,BeautifulSoup可能不识别。所以,我们不推荐使用。
有没有更好的选择呢?我们把视野稍微放宽(一点点):
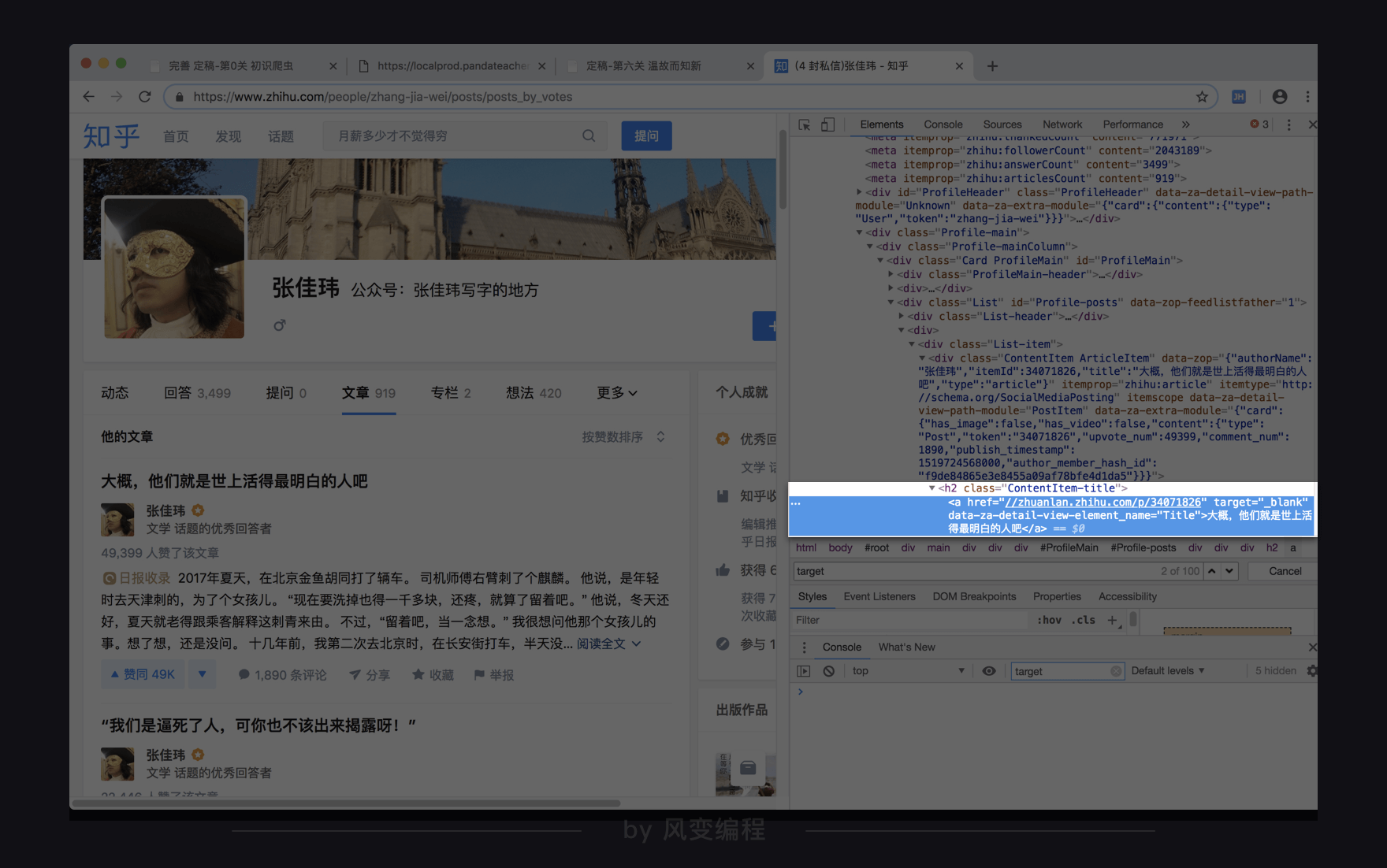
你会发现,这个<a>标签的上一个层级是<h2>标签,并且有属性class="ContentItem-title"。仍然用ctrl+f搜索属性值“ContentItem-title”,发现这个属性可以帮我们精准定位目标数据,可以用。
到这里,我们的思路也差不多清晰起来。
获取数据——用requests库;解析数据——用BeautifulSoup库;提取数据——用BeautifulSoup里的find_all()方法,翻页则要观察第一页,到最后一页的网址特征,写循环;存储数据——用csv或openpyxl模块都可以。基本思路就应该是这样。
好,这就结束了分析过程,接下来就是敲代码啦。
2.3 代码实现
别一上来就整个大的,我们先试着拿一页的文章标题,看看能不能成功。
请阅读下面的代码,然后点击运行:
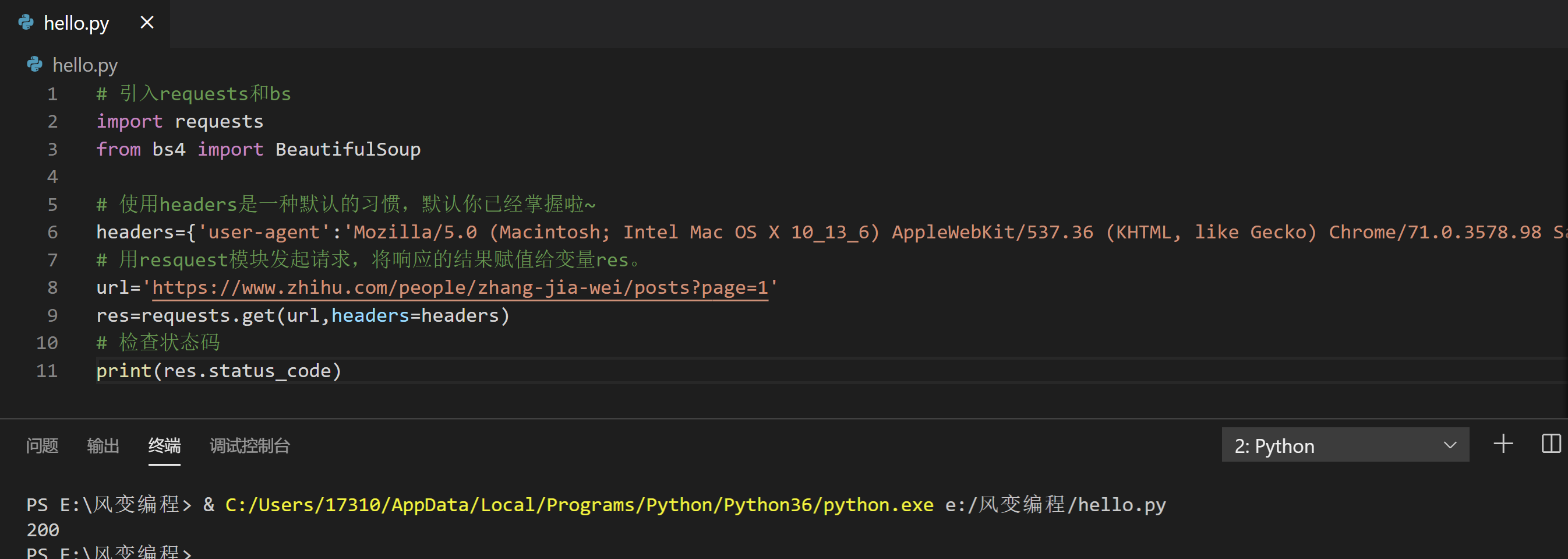
# 引入requests和bs
import requests
from bs4 import BeautifulSoup
# 使用headers是一种默认的习惯,默认你已经掌握啦~
headers={'user-agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
# 用resquest模块发起请求,将响应的结果赋值给变量res。
url='https://www.zhihu.com/people/zhang-jia-wei/posts?page=1'
res=requests.get(url,headers=headers)
# 检查状态码
print(res.status_code)
发现状态码显示200,表示请求成功,放心了,可以继续往下。
请阅读下面的代码,然后点击运行:
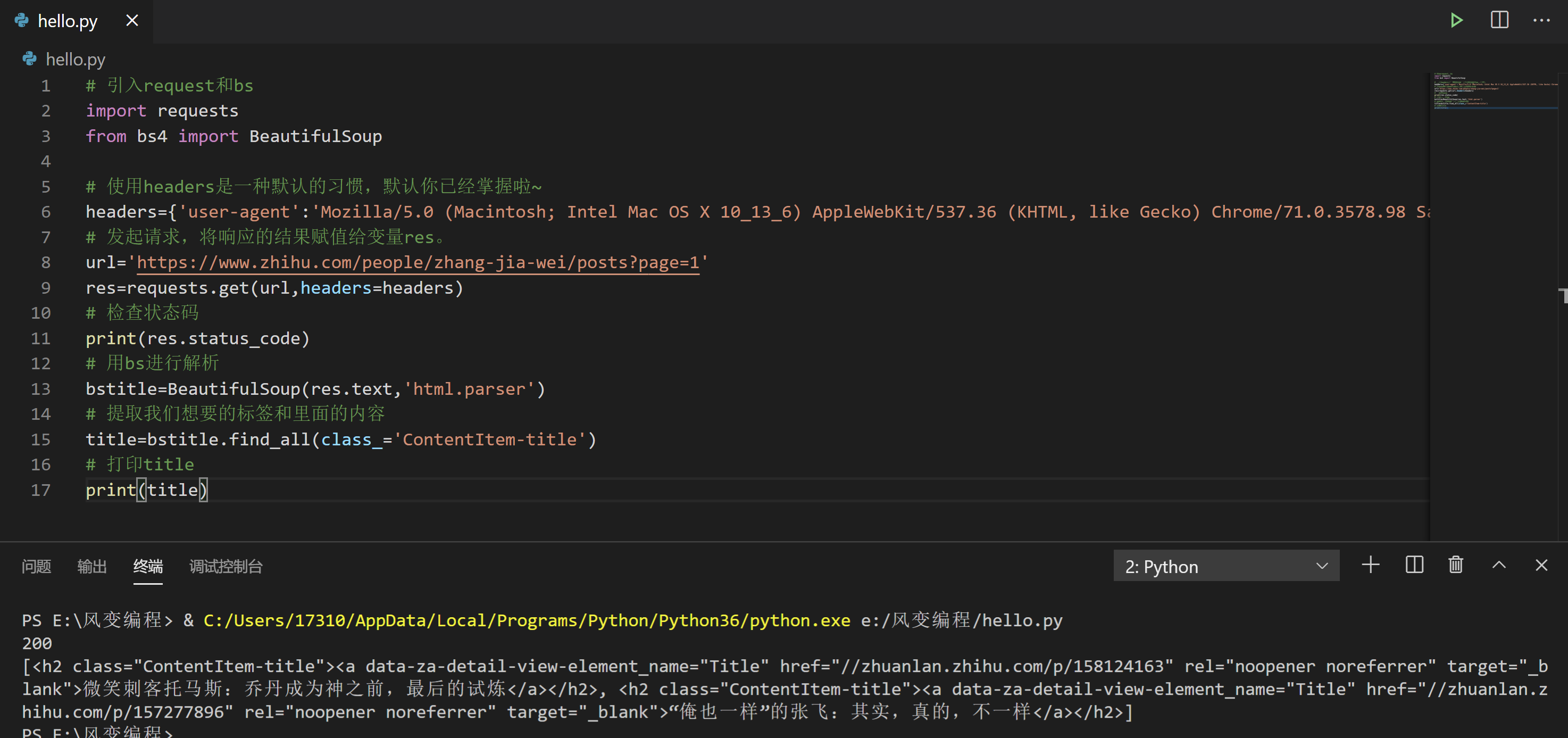
# 引入request和bs
import requests
from bs4 import BeautifulSoup
# 使用headers是一种默认的习惯,默认你已经掌握啦~
headers={'user-agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
# 发起请求,将响应的结果赋值给变量res。
url='https://www.zhihu.com/people/zhang-jia-wei/posts?page=1'
res=requests.get(url,headers=headers)
# 检查状态码
print(res.status_code)
# 用bs进行解析
bstitle=BeautifulSoup(res.text,'html.parser')
# 提取我们想要的标签和里面的内容
title=bstitle.find_all(class_='ContentItem-title')
# 打印title
print(title)
见鬼了,为啥只有两个文章标题?
看起来是碰壁了,但遇上问题别慌,先来做个排查,使用 res.text 打印一下网页源代码。请阅读下面的代码,然后点击运行。
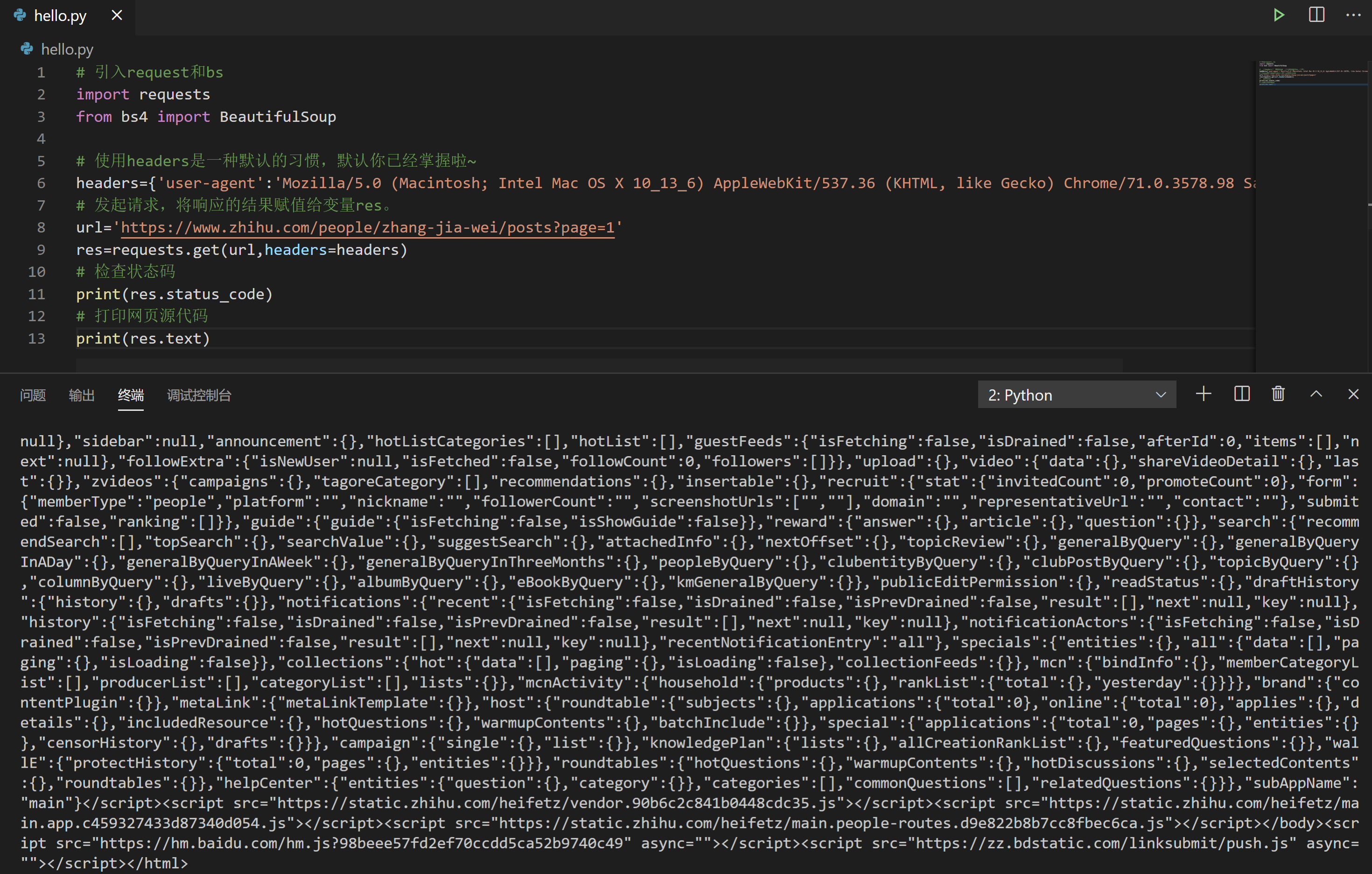
# 引入request和bs
import requests
from bs4 import BeautifulSoup
# 使用headers是一种默认的习惯,默认你已经掌握啦~
headers={'user-agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
# 发起请求,将响应的结果赋值给变量res。
url='https://www.zhihu.com/people/zhang-jia-wei/posts?page=1'
res=requests.get(url,headers=headers)
# 检查状态码
print(res.status_code)
# 打印网页源代码
print(res.text)
打出来之后,我们把第一页的最后一篇文章的标题“出走半生,关山万里,归来仍是少女心气”在这个网页源代码里面搜索,呵呵,是搜不到的。🙃
不信邪的我决定刨根问底,又把网页里其它标题搜索了一遍,甚至拿第2页又验证了一下。现在把结论分享给你:每一页前10篇文章的标题在网页源代码能找到,而后10篇文章则不见踪影。
再回过头看看:
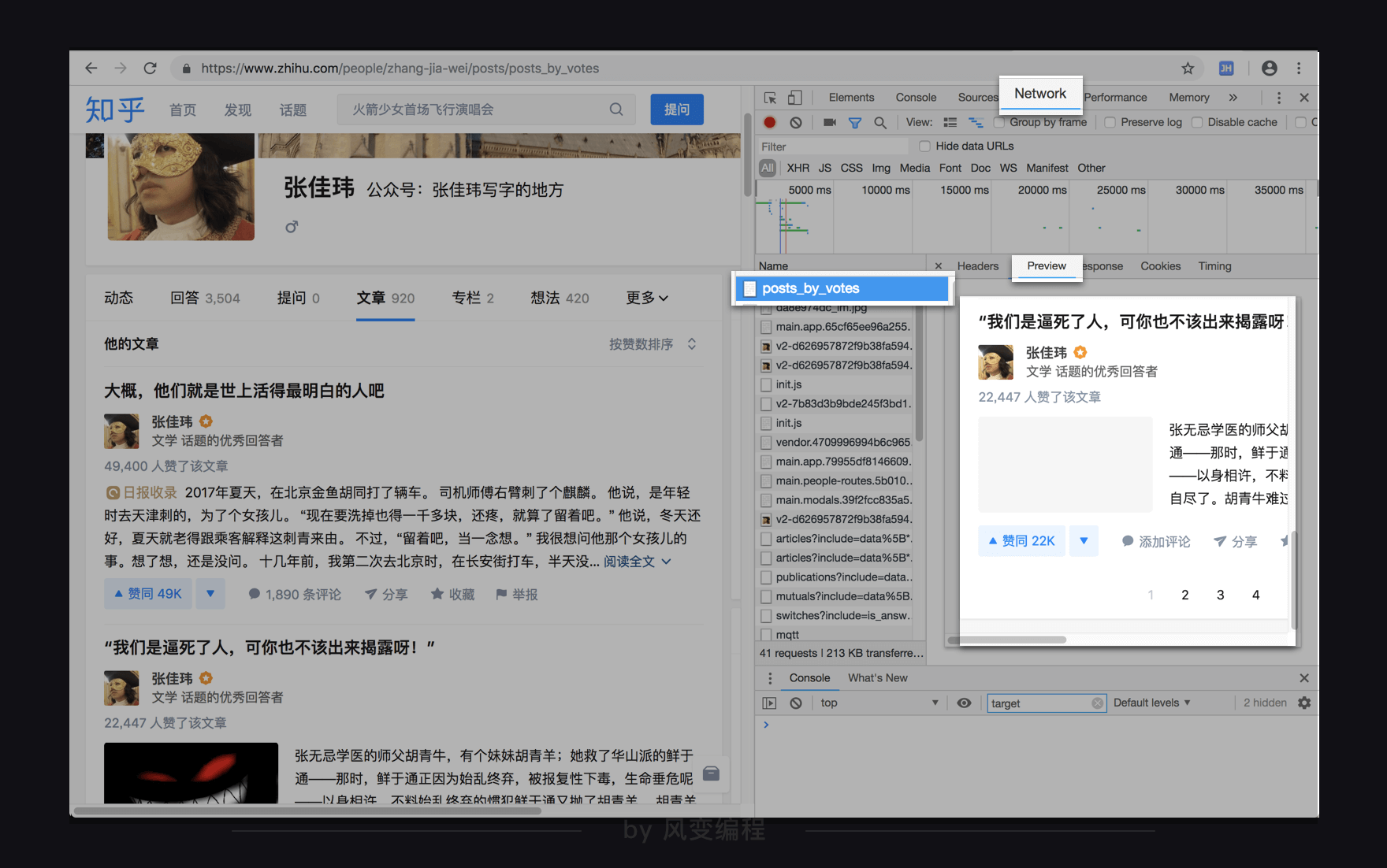
原来,前10篇里,也只有前2篇在静态HTML中,实际上,老师又刨根问底了一次,发现其它8篇文章以json数据的形式储存在了<script id="js-initialData" type="text/json">标签当中。
那么,每一页的后10篇文章数据放在了哪里?哎呀,其实我们现在已经回到分析过程了。
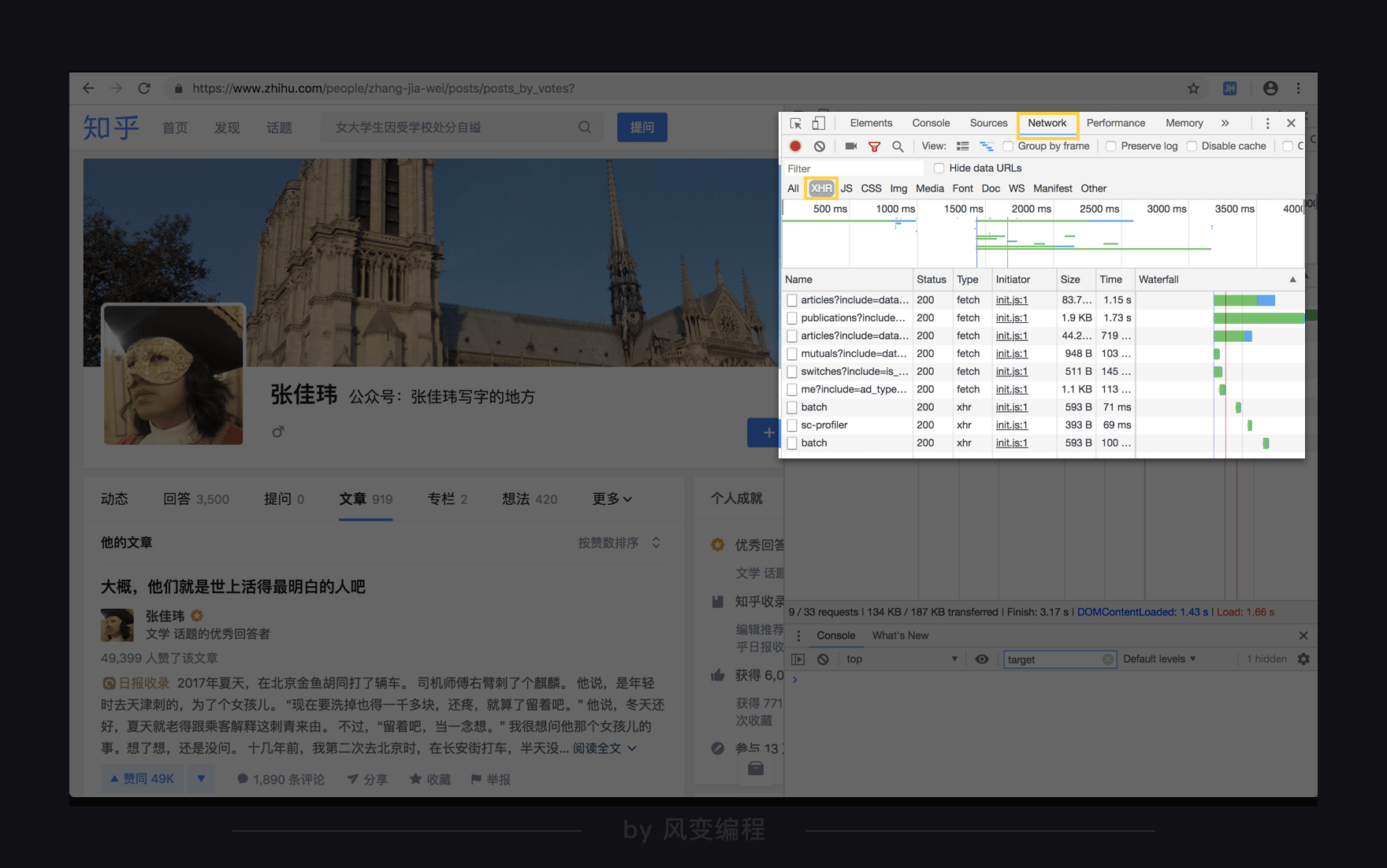
2.3.1 重新分析
我们打开Network,点开XHR,同时刷新页面,看到出现了很多个请求。
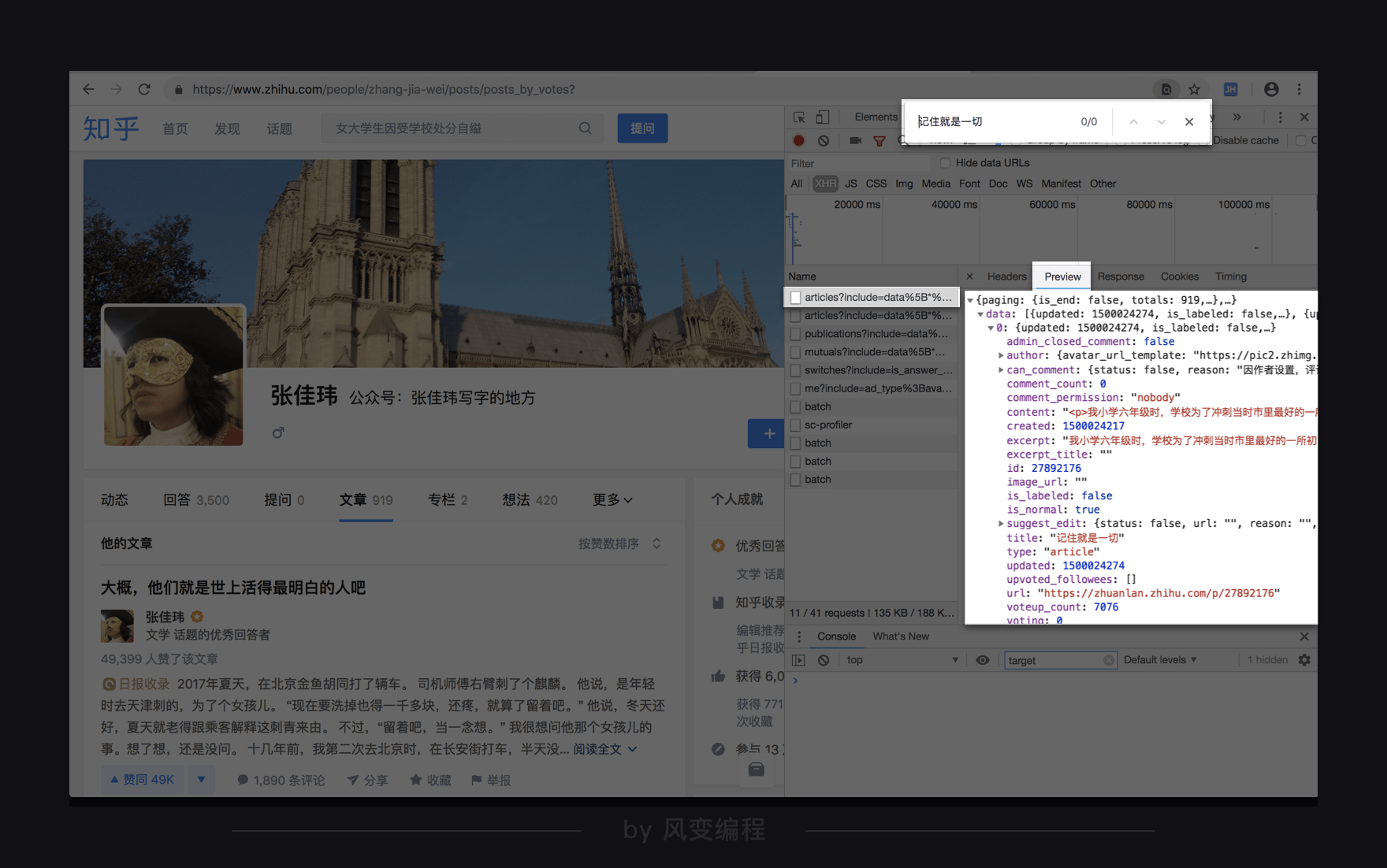
浏览一下,看到两个带articles的请求,感觉有戏。点开首个articles看看preview,一层层点开,看到“title:记住就是一切”,猜测这是一个文章标题。
在网页里面用ctrl+f搜索一下“记住就是一切”,发现搜不到,奇怪。
那就看看跟首个articles请求长得很像的另一个articles的请求好啦,仍然看preview,看到title: "国产航母下水……让我想到李鸿章和北洋舰队",仍然在网页里搜一下:
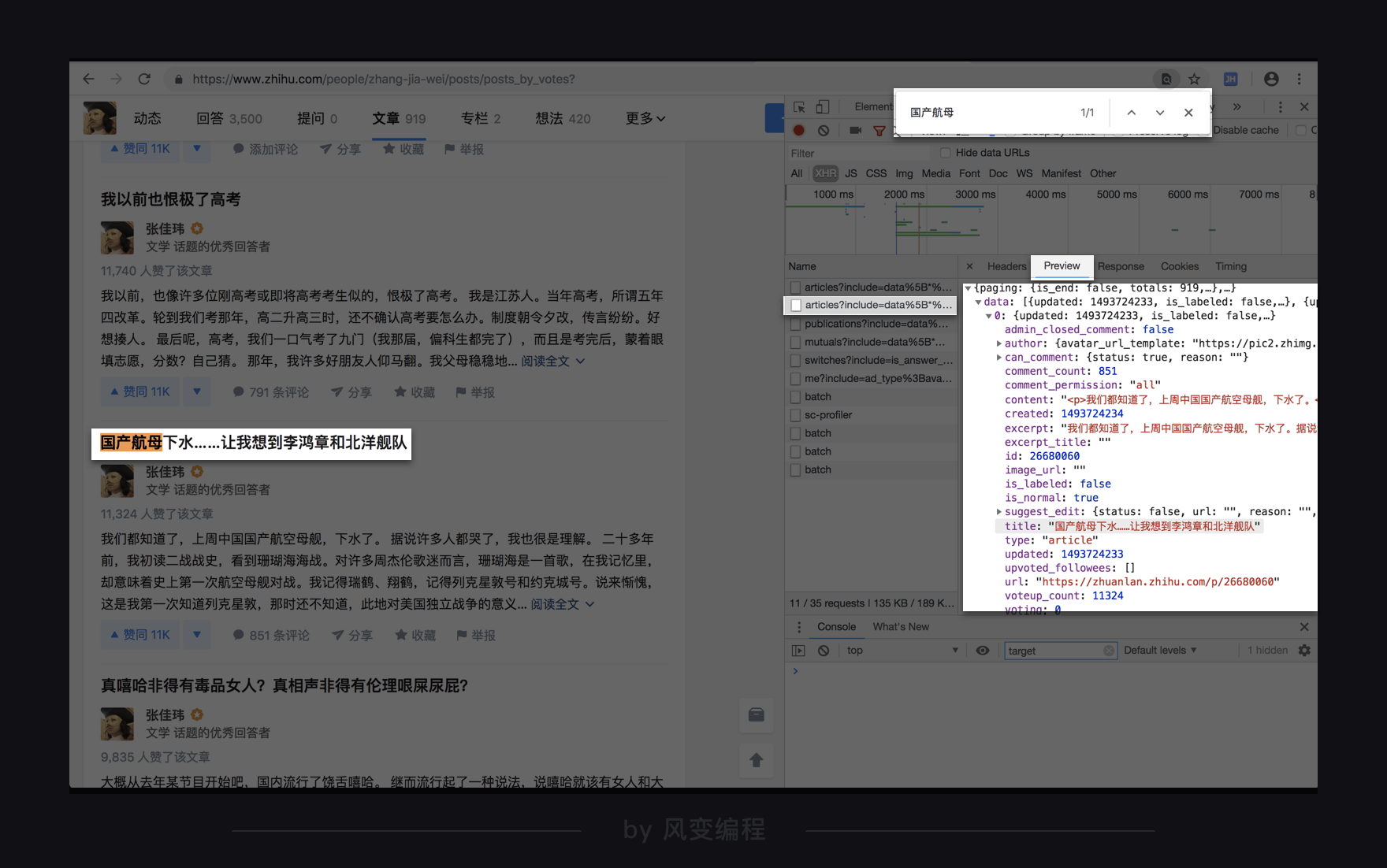
哎鸭!果然在这里。看来这个articles的请求里面存的是第一页的文章标题。这下妥了,我们知道从哪个url获取数据了。从data结构来看,刚好就是后10篇。
那首个带articles的请求是什么?其实这是知乎的网站设计,当你刷新第一页的时候,默认你也请求了第二页的文章数据,这样你加载就会比较流畅。
通过同样的方法,我们还可以发现文章的链接、文章的摘要也一样放在articles的请求里,这里就不赘述了。
到这里我们稍微停一下。通过分析网页已经发现,知乎网页上我们看到的一页20篇文章,在加载时并不像看上去一样“同质”,实际上可分为三部分,它们的获取方式各有不同,后续解析方式也有差异。
接下来的课程环节,为了复习所学内容,先把XHR中的后10篇文章数据拿到。我们说到每一页文章数据时,特指后10篇。
那么回来继续吧:理论上我们可以拿到第一页的文章数据了,要拿到之后所有页面的数据,还不够吧。
好,我们去观察第1页请求和第2页请求的参数区别,是在headers里面的query string parameters里面。
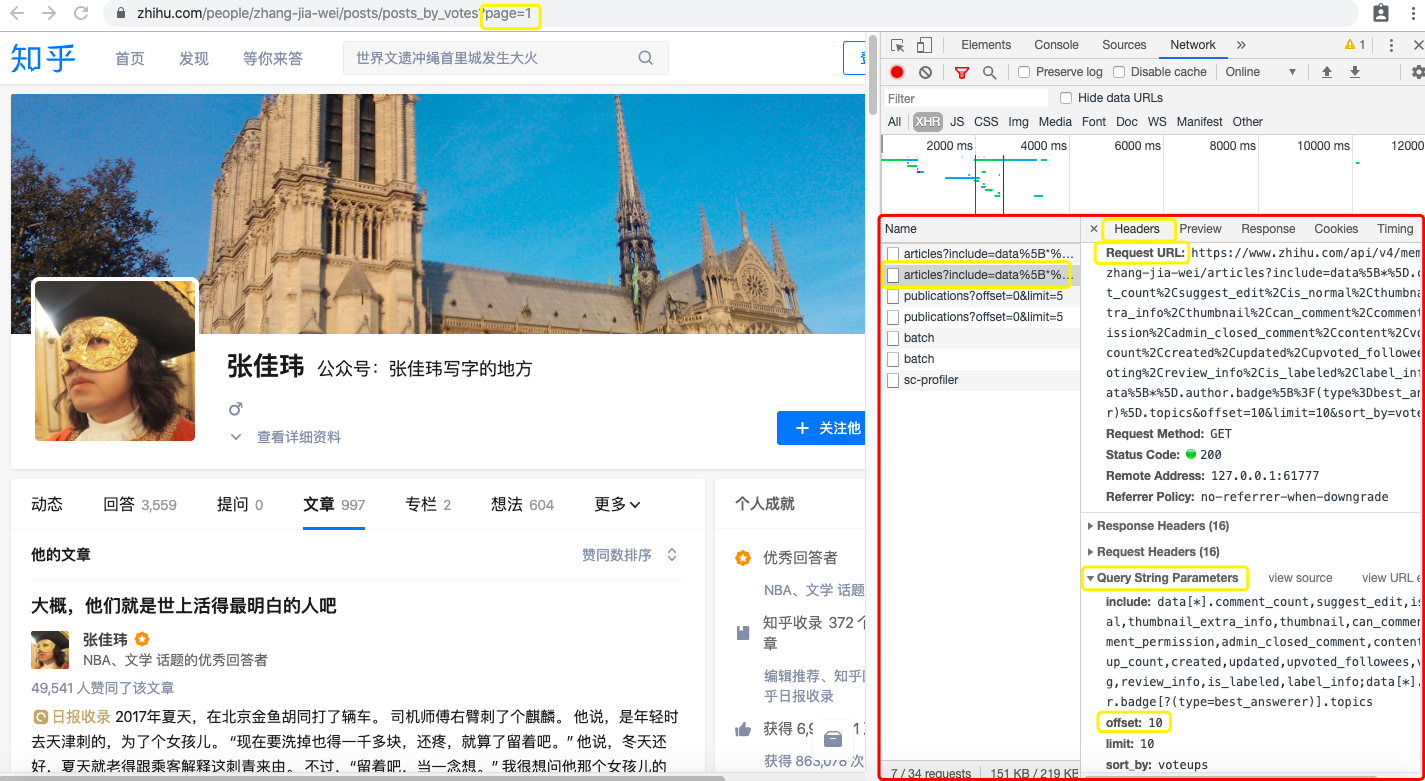
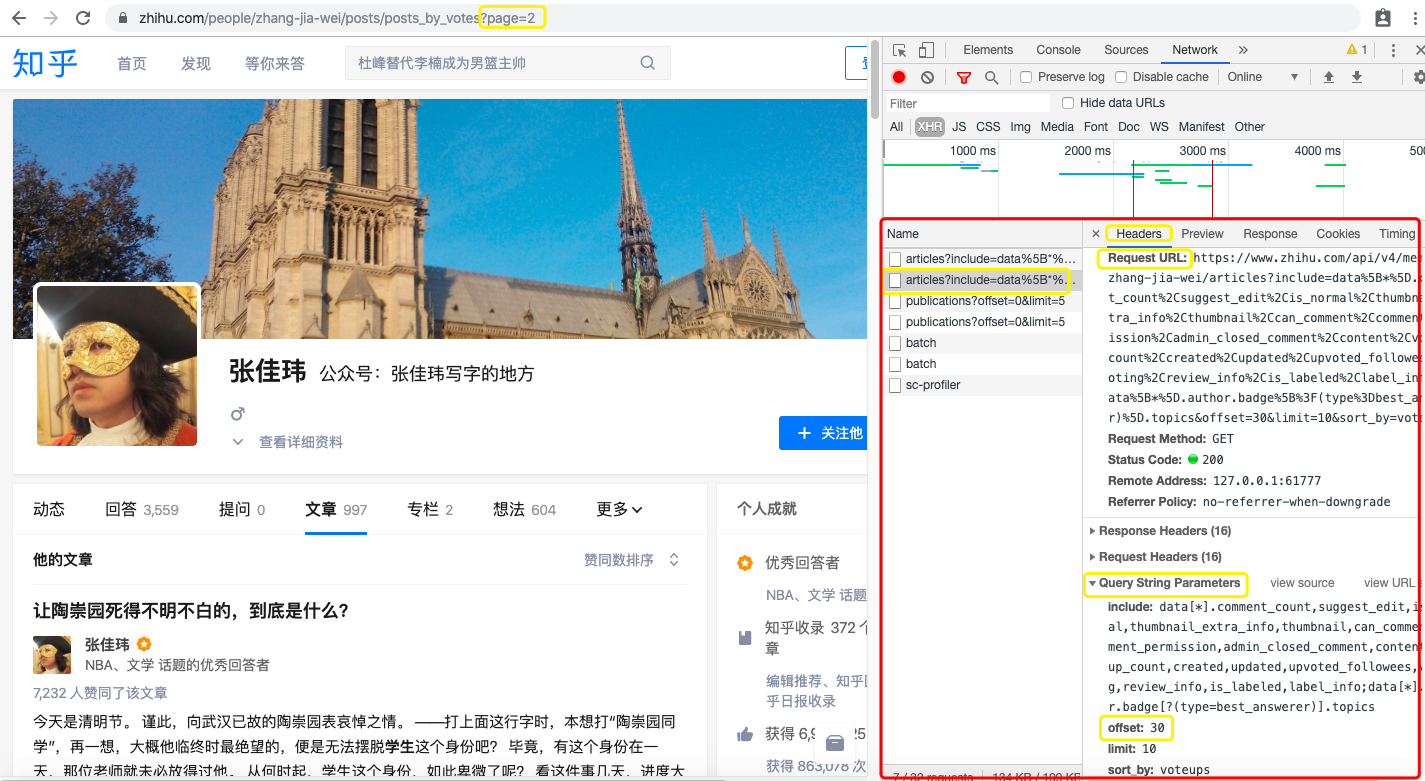
然后发现除了offset都一样,offset代表偏移量,和页码有对应关系,通过循环遍历各页我们就可以爬到所有页数的内容了。
我们的大致思路也就出来了。
好,分析过程搞定后,就又是写代码啦~
2.3.2 代码实现
我们可以参考上面的知识地图,一步一步来写,所以先请你用requests.get()获取数据,然后检查请求是否成功。
获取数据:张佳玮知乎文章的页面是:https://www.zhihu.com/people/zhang-jia-wei/posts,
然后请你找到标题数据所在的请求页面的Request URL,再用requests.get()方法获取
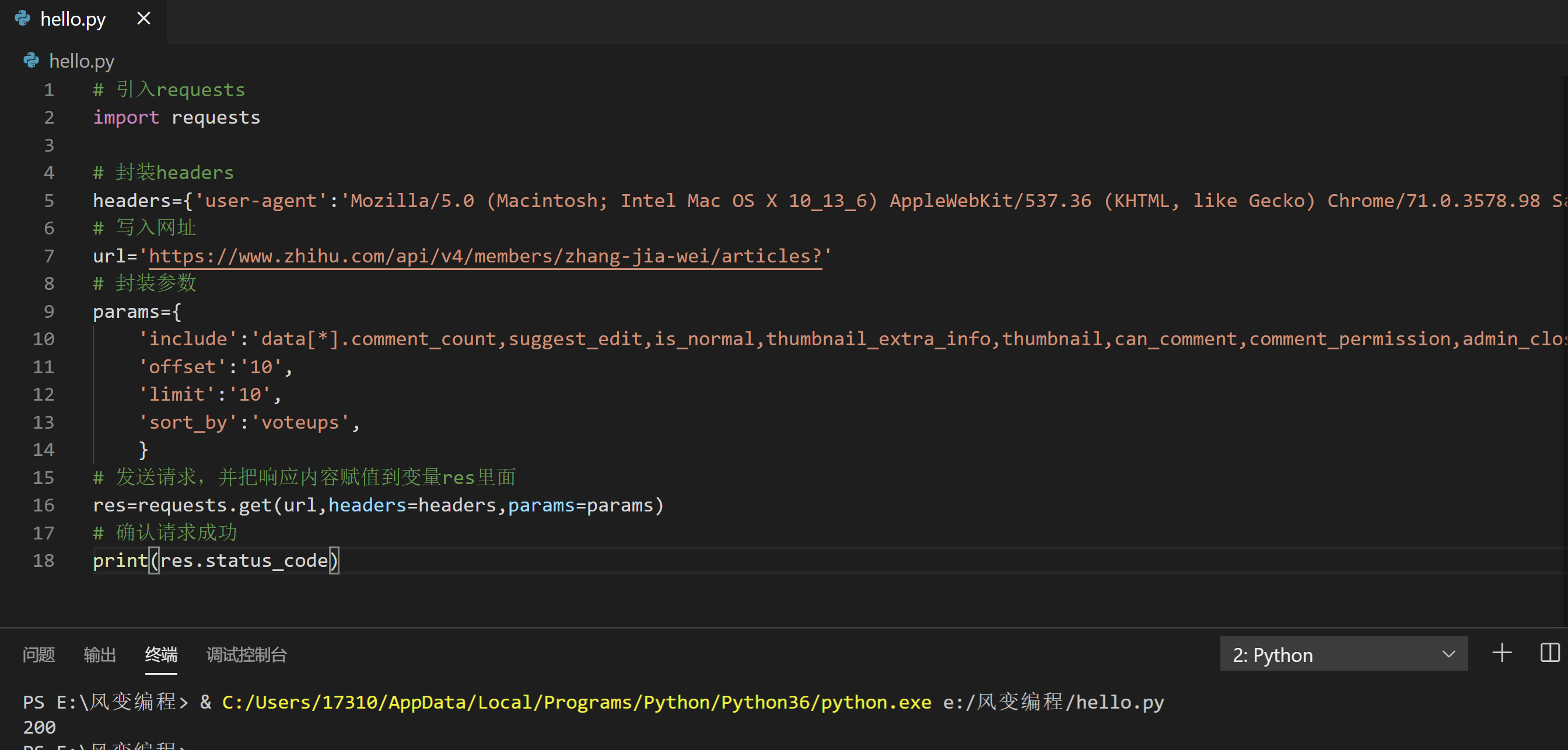
我提供的答案是这样的:
# 引入requests
import requests
# 封装headers
headers={'user-agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
# 写入网址
url='https://www.zhihu.com/api/v4/members/zhang-jia-wei/articles?'
# 封装参数
params={
'include':'data[*].comment_count,suggest_edit,is_normal,thumbnail_extra_info,thumbnail,can_comment,comment_permission,admin_closed_comment,content,voteup_count,created,updated,upvoted_followees,voting,review_info,is_labeled,label_info;data[*].author.badge[?(type=best_answerer)].topics',
'offset':'10',
'limit':'10',
'sort_by':'voteups',
}
# 发送请求,并把响应内容赋值到变量res里面
res=requests.get(url,headers=headers,params=params)
# 确认请求成功
print(res.status_code)
终端显示200,请求成功,妥了。下一步是解析json数据。
请你思考一下,然后点击阅读代码,再点击运行。
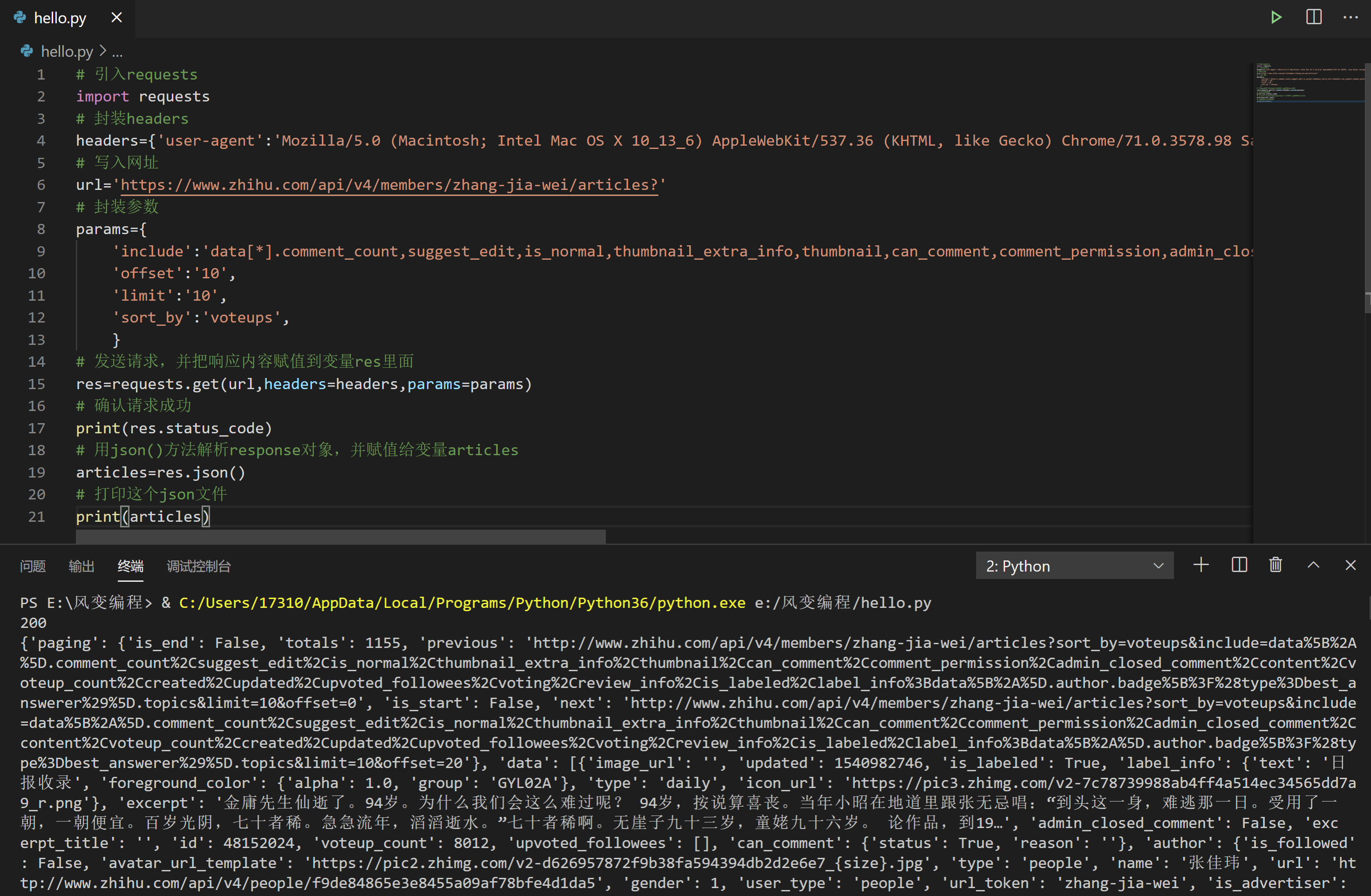
# 引入requests
import requests
# 封装headers
headers={'user-agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
# 写入网址
url='https://www.zhihu.com/api/v4/members/zhang-jia-wei/articles?'
# 封装参数
params={
'include':'data[*].comment_count,suggest_edit,is_normal,thumbnail_extra_info,thumbnail,can_comment,comment_permission,admin_closed_comment,content,voteup_count,created,updated,upvoted_followees,voting,review_info,is_labeled,label_info;data[*].author.badge[?(type=best_answerer)].topics',
'offset':'10',
'limit':'10',
'sort_by':'voteups',
}
# 发送请求,并把响应内容赋值到变量res里面
res=requests.get(url,headers=headers,params=params)
# 确认请求成功
print(res.status_code)
# 用json()方法解析response对象,并赋值给变量articles
articles=res.json()
# 打印这个json文件
print(articles)
发现没问题,接下来就是要根据json数据结构来提取我们想要的文章标题数据了。
我们在preview里面一层层看看这个json文件,到底是怎么一个结构。下面三张图依次是从外到内的数据展示。
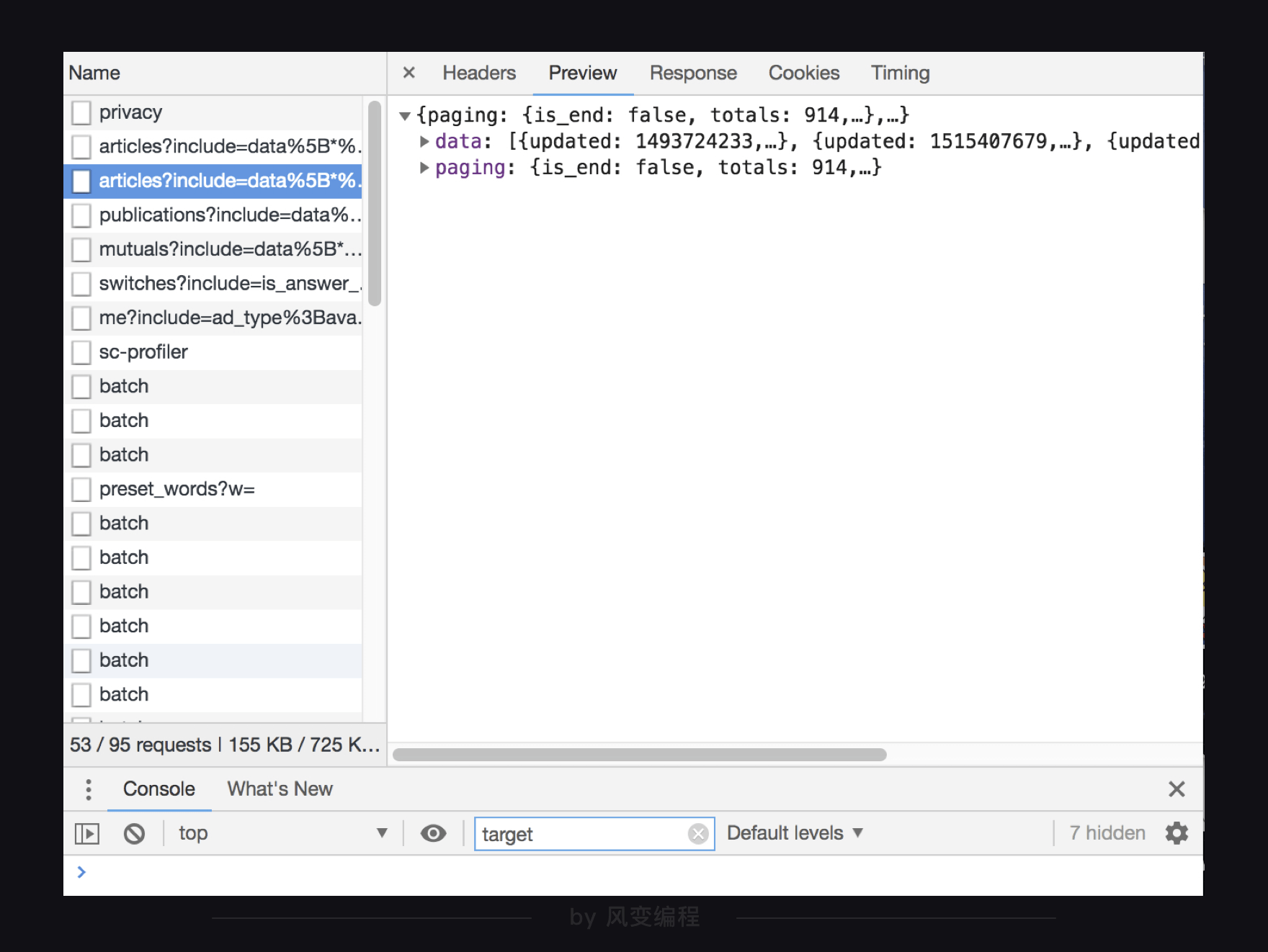
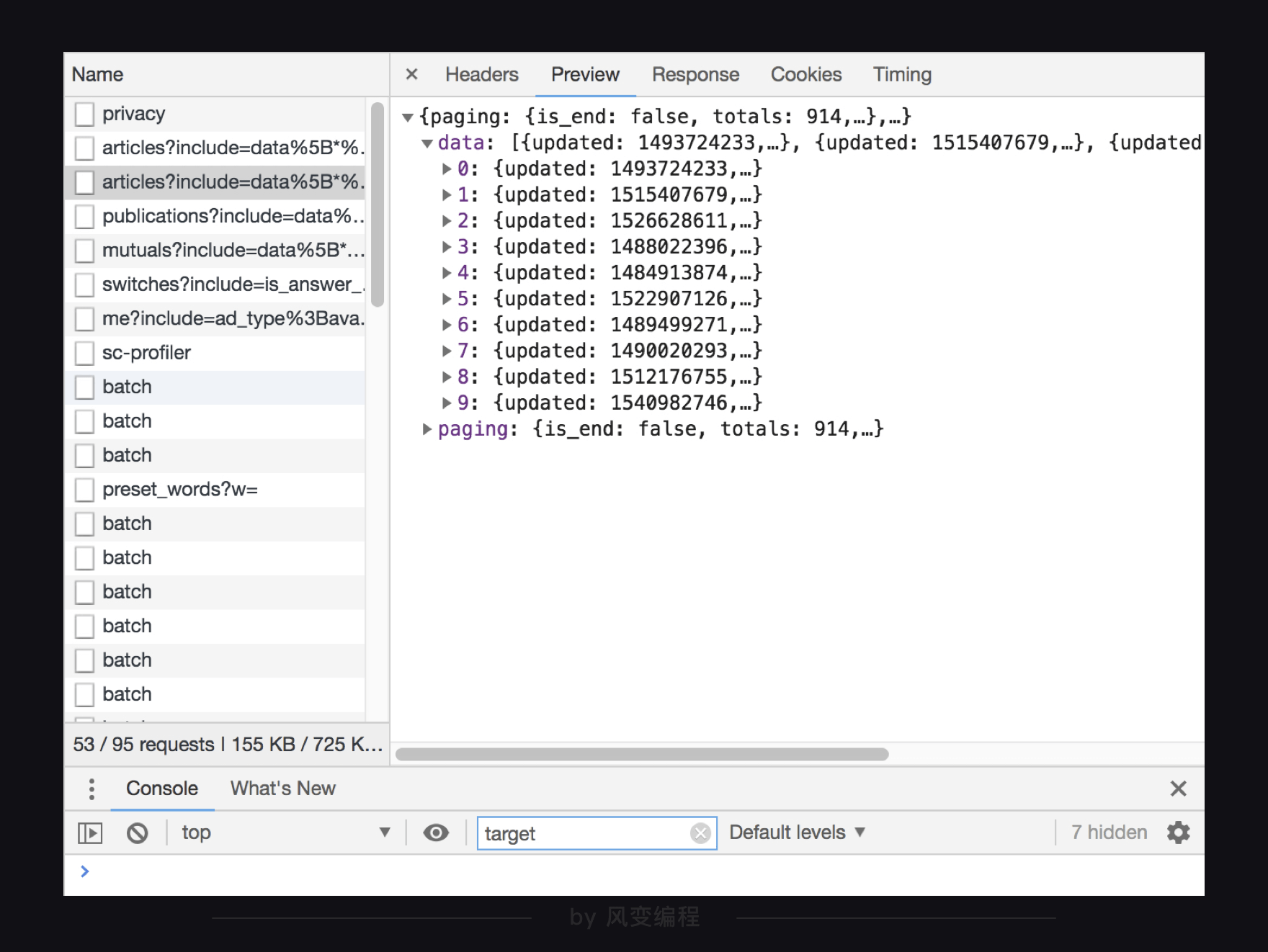
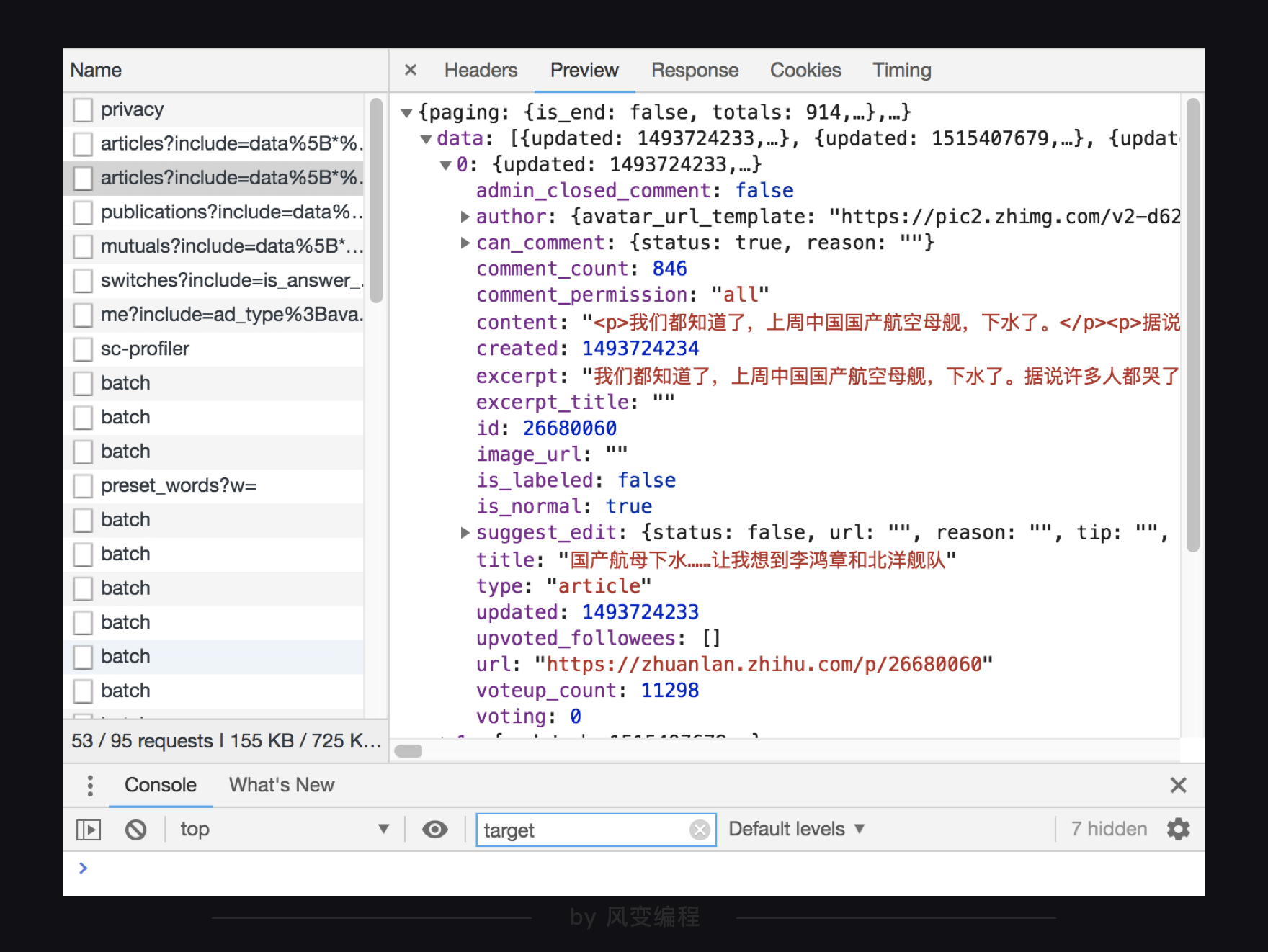
最外层是一个很大的字典,里面有两大元素,data:和paging:,这两大元素又是键值对应的字典形式,data这个键所对应的值是一个列表,里面有10元素,每个元素又是字典形式。
这样看其实还不够直观,为了更清晰地定位到目标数据,我们来梳理一下结构:
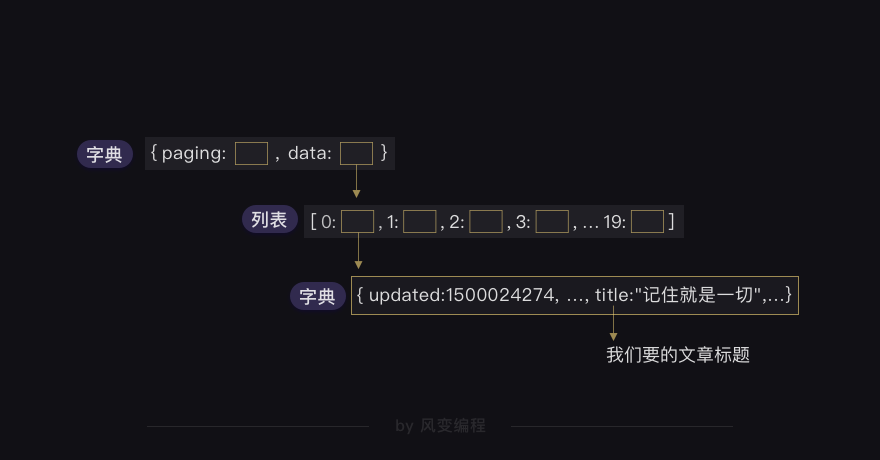
最外层是个字典,在键为data的值里面,又有一个列表,而列表的每个元素又是一个字典,在第0个元素的值里面,又有一个字典,这里面终于有了我们要拿的title: "国产航母下水……让我想到李鸿章和北洋舰队"。
那就可以像剥洋葱一样一层层地取数据了,我们又要接着来写代码了,(≧▽≦)/,这一步,我们只要先拿第一页的所有文章的标题即可。
我们的目标:续写代码,打印出第一页的所有文章的标题。
以下,是我的参考答案:
# 引入requests
import requests
# 封装headers
headers={'user-agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
# 写入网址
url='https://www.zhihu.com/api/v4/members/zhang-jia-wei/articles?'
# 封装参数
params={
'include':'data[*].comment_count,suggest_edit,is_normal,thumbnail_extra_info,thumbnail,can_comment,comment_permission,admin_closed_comment,content,voteup_count,created,updated,upvoted_followees,voting,review_info,is_labeled,label_info;data[*].author.badge[?(type=best_answerer)].topics',
'offset':'10',
'limit':'10',
'sort_by':'voteups',
}
# 发送请求,并把响应内容赋值到变量res里面
res=requests.get(url,headers=headers,params=params)
# 确认请求成功,即这个response对象状态正确
print(res.status_code)
# 用json()方法解析response对象,并赋值到变量articles上面
articles=res.json()
# 打印这个json文件
print(articles)
# 取出键为data的值
data=articles['data']
# 遍历列表,拿到的是列表里的每一个元素,这些元素都是字典,再通过键把值取出来
for i in data:
print(i['title'])
通过同样的方法,我们也可以定位到文章链接和文章摘要的数据。
# 引入requests
import requests
# 封装headers
headers={'user-agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
# 写入网址
url='https://www.zhihu.com/api/v4/members/zhang-jia-wei/articles?'
# 封装参数
params={
'include':'data[*].comment_count,suggest_edit,is_normal,thumbnail_extra_info,thumbnail,can_comment,comment_permission,admin_closed_comment,content,voteup_count,created,updated,upvoted_followees,voting,review_info,is_labeled,label_info;data[*].author.badge[?(type=best_answerer)].topics',
'offset':'10',
'limit':'10',
'sort_by':'voteups',
}
# 发送请求,并把响应内容赋值到变量res里面
res=requests.get(url,headers=headers,params=params)
# 确认请求成功,即这个response对象状态正确
print(res.status_code)
# 用json()方法解析response对象,并赋值到变量articles上面
articles=res.json()
# 打印这个json文件
print(articles)
# 取出键为data的值
data=articles['data']
# 遍历列表,拿到的是列表里的每一个元素,这些元素都是字典,再通过键把值取出来
for i in data:
print(i['title'])
print(i['url'])
print(i['excerpt'])
至此,第一页的数据我们就拿到了,接下来要去拿所有页面的数据。
我们在上一步已经分析过了,第一页和第二页的请求的参数区别在于offset,再看一下第三页、第四页,找一下规律,由此可以写一个循环。
那么如何结束这个循环呢?
这里我有一个经验之谈,我们来看看第一页和最后一页data部分下面的paging的参数区别:
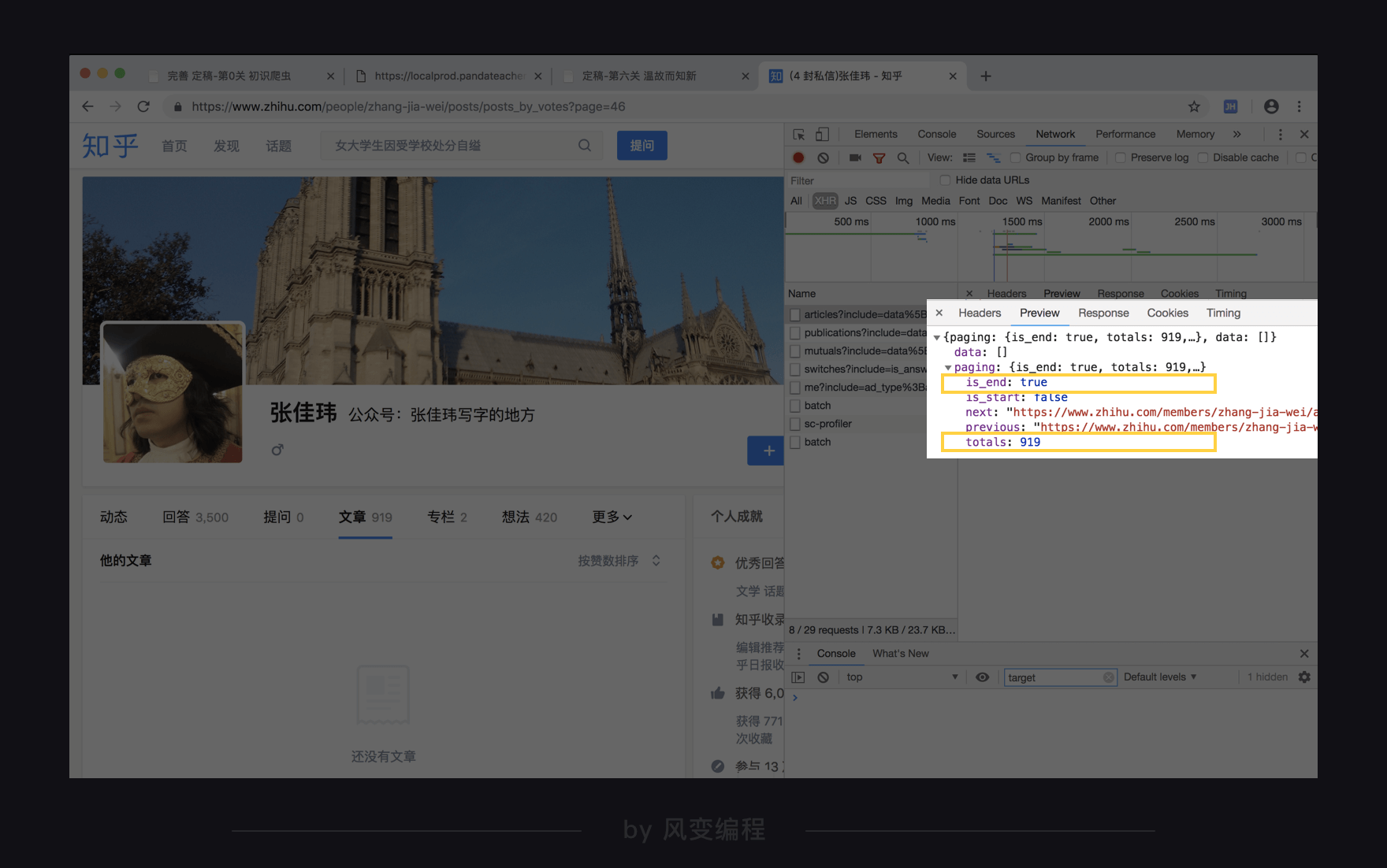
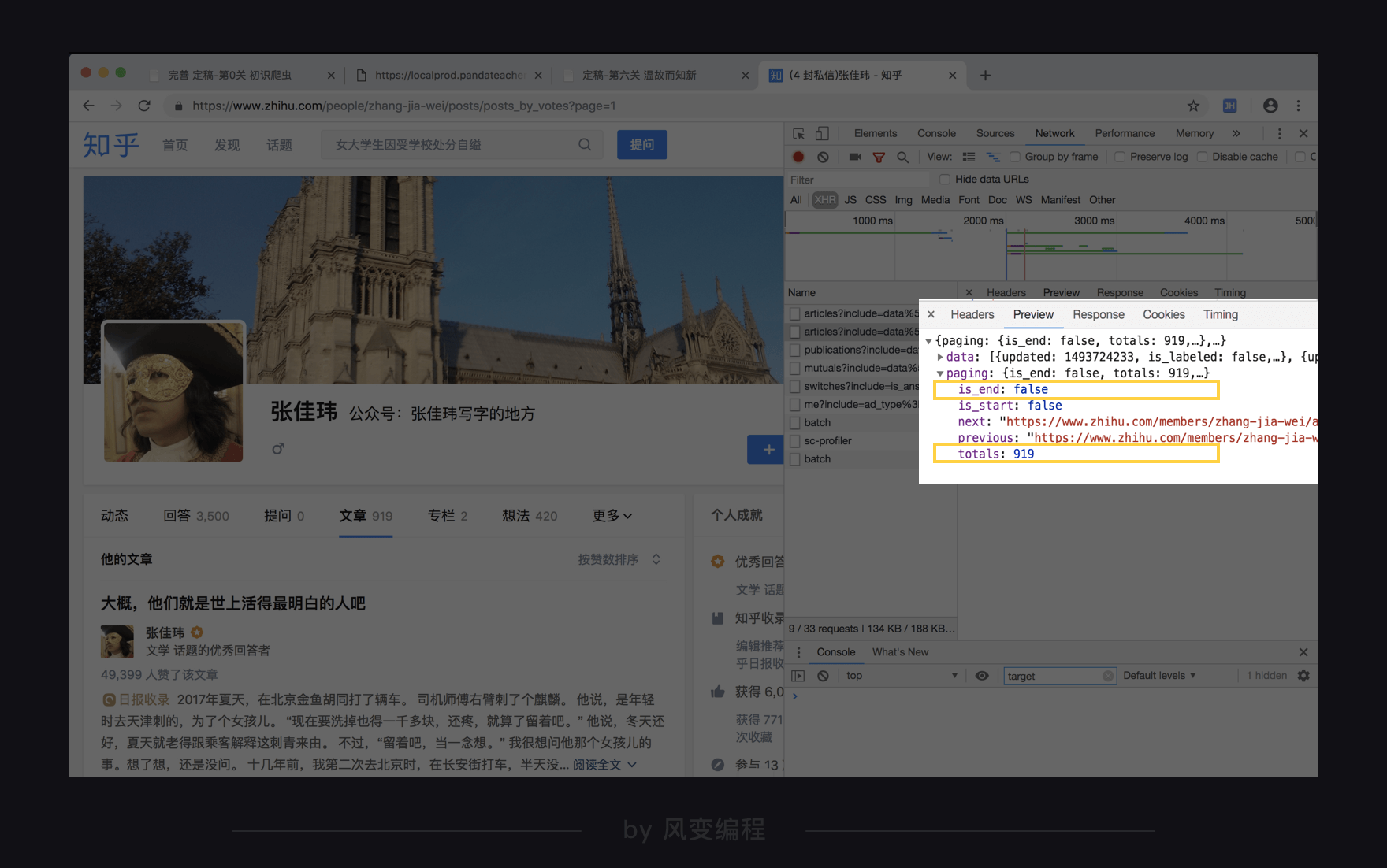
对比一下,你会发第一页的is_end是显示false,最后一页的is_end是显示true,这个元素可以帮我们结束循环。
至于那个totals: 919元素,我算了一下页码和每页的文章数,判断这是文章的总数,也同样可以作为结束循环的条件。
以上告诉你我是怎么做的,现在聊聊我是怎么想到的。我刚才的思路其实和找合适的标签提取标题时很像,类似“data里有我们的目标数据,但好像没有结束循环的标志,视野稍稍放宽,找一找上下文有没有帮助我们结束循环的数据。”
所谓“经验之谈”,就是这样的知识迁移了。在熟练运用之前我们还有其他思路可参考,比如,文章是分页的,按页码来嘛。如果够细心,你可能还会发现知乎的一个设定:按点赞数排序的文章只显示前**页。(什么?数字部分打码了?不想被剧透先自己找找看吧。)
理论上,我们就可以拿到按赞同数排序的这25页数据了。但是在这里,我们并不建议爬取全部数据。大家想想,参加课程的同学有很多,每个人都去爬这25页的话,如此高频访问会给对方的服务器造成相当大的压力,而我们并不真正需要这么多的数据,只是为了学习爬虫。
这里还涉及到一个更严肃的问题:在合法使用爬虫时,除了遵循robots协议,还要注意避免超大量爬取对网站服务器造成过大负担。
所以,我们的循环会设置为爬两页数据就停止。代码如下:
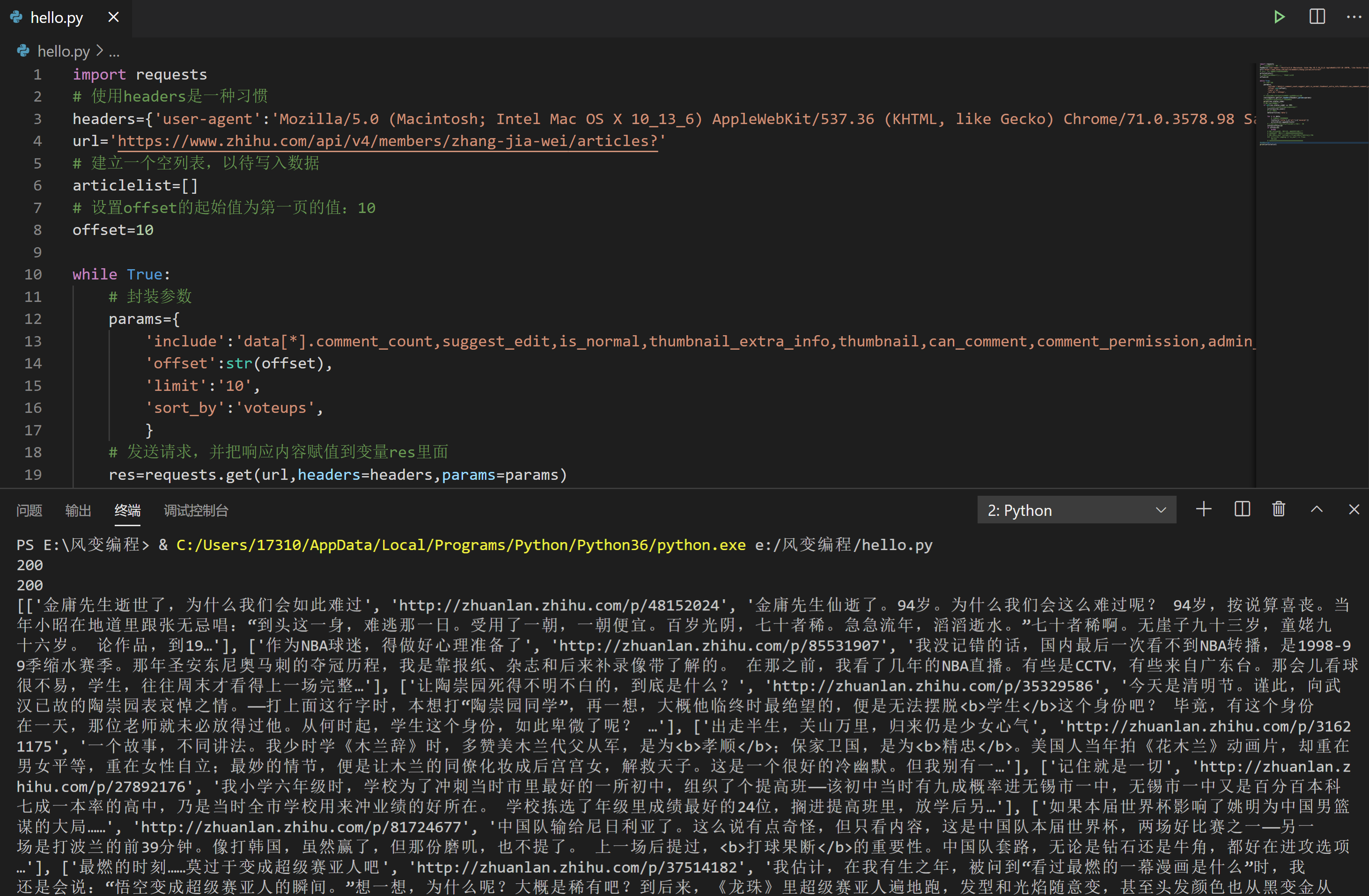
import requests
# 使用headers是一种习惯
headers={'user-agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
url='https://www.zhihu.com/api/v4/members/zhang-jia-wei/articles?'
# 建立一个空列表,以待写入数据
articlelist=[]
# 设置offset的起始值为第一页的值:10
offset=10
while True:
# 封装参数
params={
'include':'data[*].comment_count,suggest_edit,is_normal,thumbnail_extra_info,thumbnail,can_comment,comment_permission,admin_closed_comment,content,voteup_count,created,updated,upvoted_followees,voting,review_info,is_labeled,label_info;data[*].author.badge[?(type=best_answerer)].topics',
'offset':str(offset),
'limit':'10',
'sort_by':'voteups',
}
# 发送请求,并把响应内容赋值到变量res里面
res=requests.get(url,headers=headers,params=params)
# 确认这个response对象状态正确
print(res.status_code)
# 如果响应成功,继续
if int(res.status_code) == 200:
# 用json()方法去解析response对象
articles=res.json()
# 定位数据
data=articles['data']
for i in data:
# 把数据封装成列表
list1=[i['title'],i['url'],i['excerpt']]
articlelist.append(list1)
# 在while循环内部,offset的值每次增加20
offset=offset+20
if offset>30:
break
# 如果offset大于30,即爬了两页,就停止
# ——————另一种思路实现————————————————
# 如果键is_end所对应的值是True,就结束while循环。
#if articles['paging']['is_end'] == True:
#break
# ————————————————————————————————————
#打印看看
print(articlelist)
好啦,你读完这段代码就该你去写啦:
获取、解析、提取数据都完成了。好,接下来就是存储数据了。
在我的想象中,最终的数据最好存成下面这样简明清晰的表格:

csv和openpyxl都可以做到,但在这里我们会选取csv,因为上一关的案例是用的openpyxl,那我们今天就来试试csv。
上一关,我们学的csv最主要的功能就是可以把列表按行写入。
反推回来,也就是我们如果可以把数据写成list=[title,url,excerpt]的样子,那就可以直接写入啦。
刚刚我们爬取到的数据也是这样的一个列表,那么我们就知道如何写代码了。
我们的目标:续写代码,请把获取到的两页的文章标题、链接、摘要这些数据,使用csv保存到本地。
csv写入文件的步骤如下:
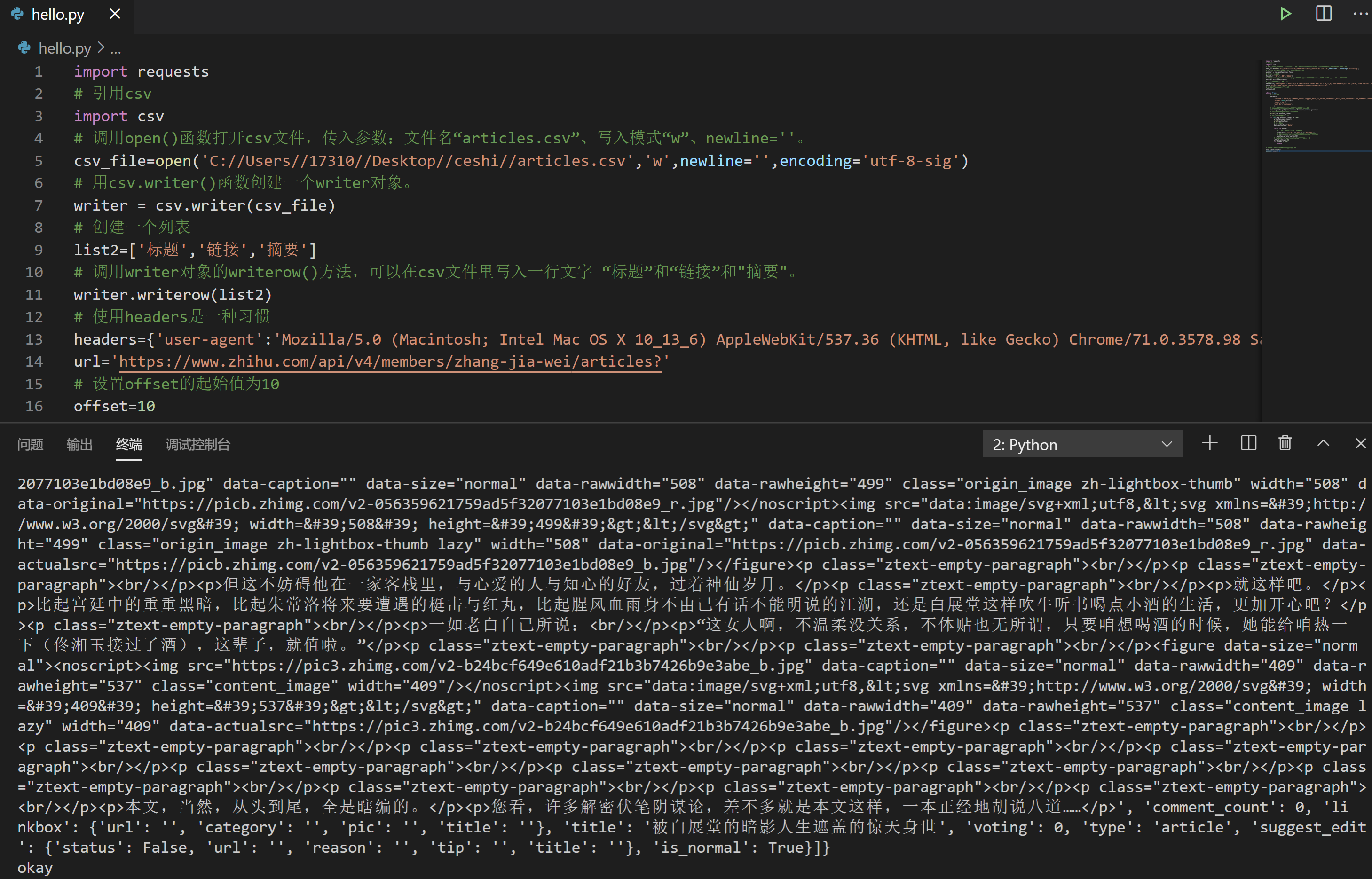
怎么样,保存成功了吗?打开看看成果
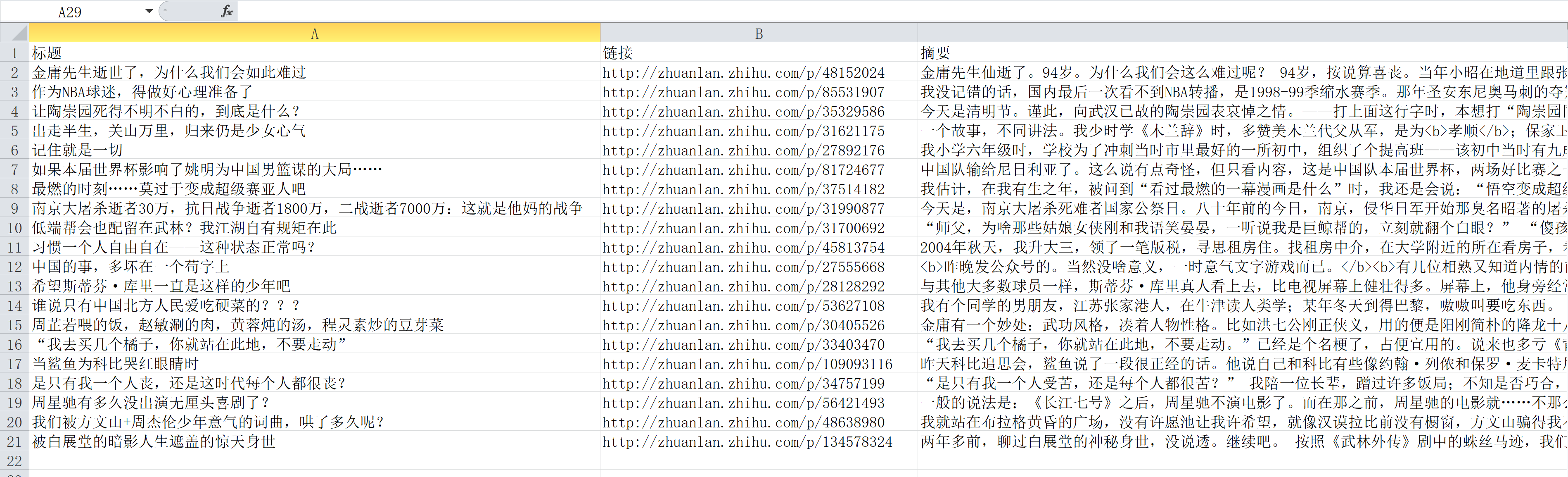
再看看我的参考答案:
import requests
# 引用csv
import csv
# 调用open()函数打开csv文件,传入参数:文件名“articles.csv”、写入模式“w”、newline=''。
csv_file=open('C://Users//17310//Desktop//ceshi//articles.csv','w',newline='',encoding='utf-8-sig')
# 用csv.writer()函数创建一个writer对象。
writer = csv.writer(csv_file)
# 创建一个列表
list2=['标题','链接','摘要']
# 调用writer对象的writerow()方法,可以在csv文件里写入一行文字 “标题”和“链接”和"摘要"。
writer.writerow(list2)
# 使用headers是一种习惯
headers={'user-agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
url='https://www.zhihu.com/api/v4/members/zhang-jia-wei/articles?'
# 设置offset的起始值为10
offset=10
while True:
# 封装参数
params={
'include':'data[*].comment_count,suggest_edit,is_normal,thumbnail_extra_info,thumbnail,can_comment,comment_permission,admin_closed_comment,content,voteup_count,created,updated,upvoted_followees,voting,review_info,is_labeled,label_info;data[*].author.badge[?(type=best_answerer)].topics',
'offset':str(offset),
'limit':'10',
'sort_by':'voteups',
}
# 发送请求,并把响应内容赋值到变量res里面
res=requests.get(url,headers=headers,params=params)
# 确认这个response对象状态正确
print(res.status_code)
# 如果响应成功,继续
if int(res.status_code) == 200:
articles=res.json()
print(articles)
# 定位数据
data=articles['data']
for i in data:
# 把目标数据封装成一个列表
list1=[i['title'],i['url'],i['excerpt']]
# 调用writerow()方法,把列表list1的内容写入
writer.writerow(list1)
# 在while循环内部,offset的值每次增加20
offset=offset+20
if offset > 30:
break
# 写入完成后,关闭文件就大功告成
csv_file.close()
print('okay')
(≧▽≦)/ 充满了喜悦。
代码实现我们就搞完了,开心吖~
3. 习题练习
1.练习介绍
从牙牙学语接触到26个英文字母到一次又一次的英文考试,到现在可以流利读英文文章,英语可谓是大多数人的第二语言。
今天呢,我们要做一个测英语单词量的小工具,看看你认识多少单词~
2.要求
实现功能:利用扇贝网:https://www.shanbay.com/, 做个测单词的小工具。
3.1 第一步:分析需求,明确目标
1.扇贝网:https://www.shanbay.com/已经有一个测单词量的功能,
我们要做的就是把这个功能复制下来,并且做点改良,搞一个网页版没有的功能 ———— 自动生成错词本。
2.在这一步,请阅读文档的同时打开浏览器的扇贝网,跟着我一步步来。
3.步骤讲解
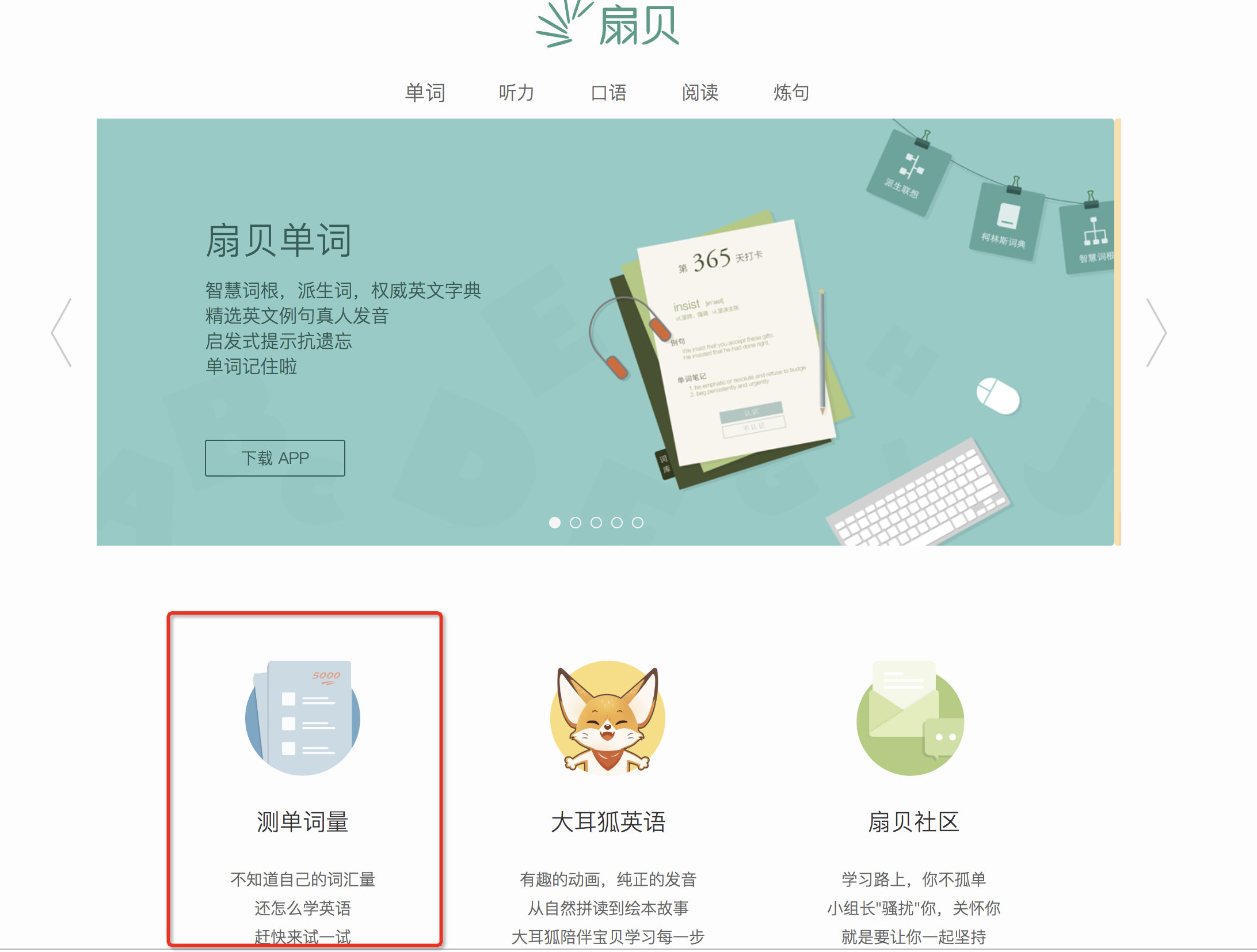
3.1 这里是扇贝网的测单词量的界面:
3.2 想要复制功能,就先做分析,这个网页是怎样的工作流程。所以,先体验全程,大概分为如下五个页面:



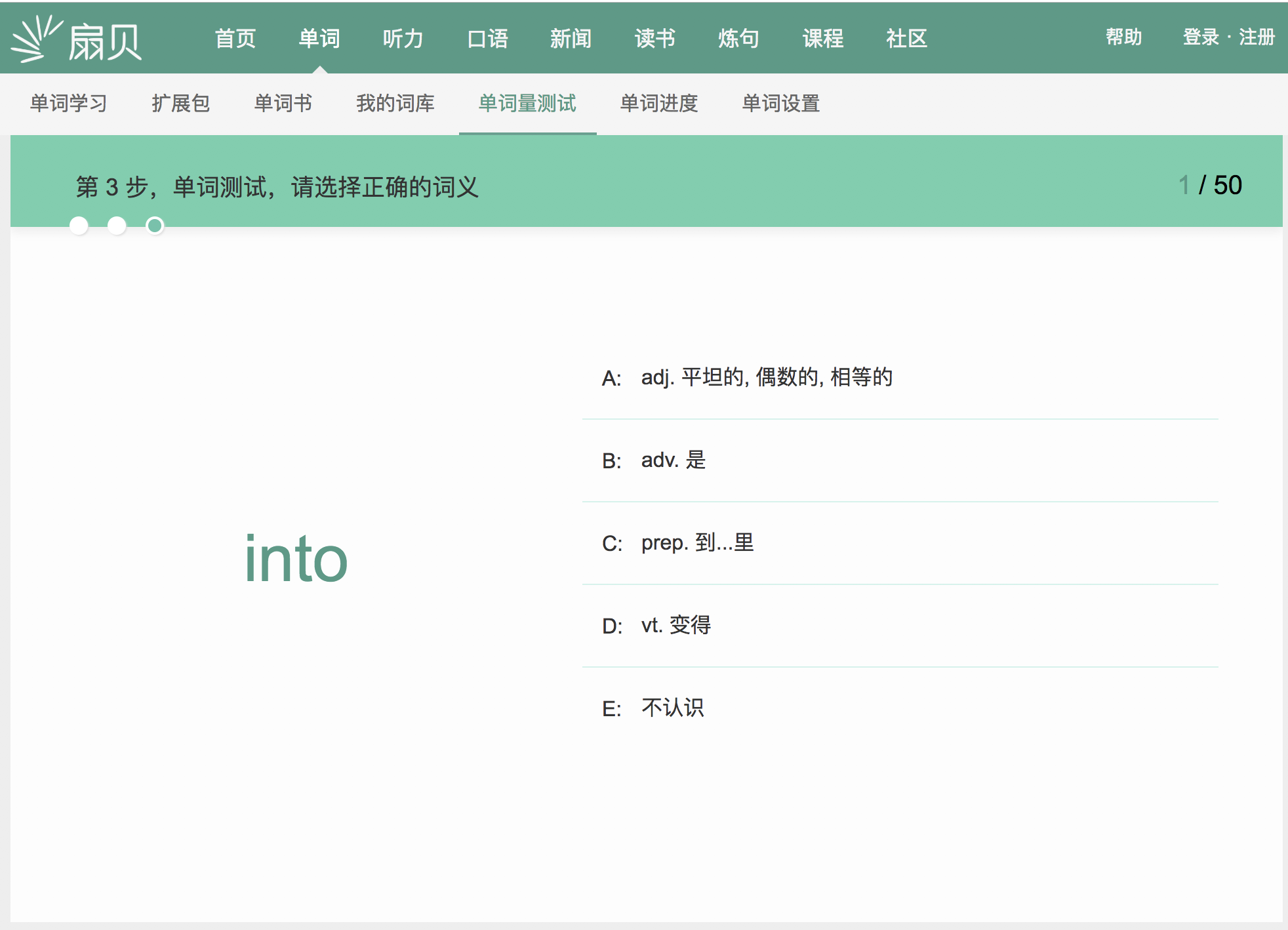
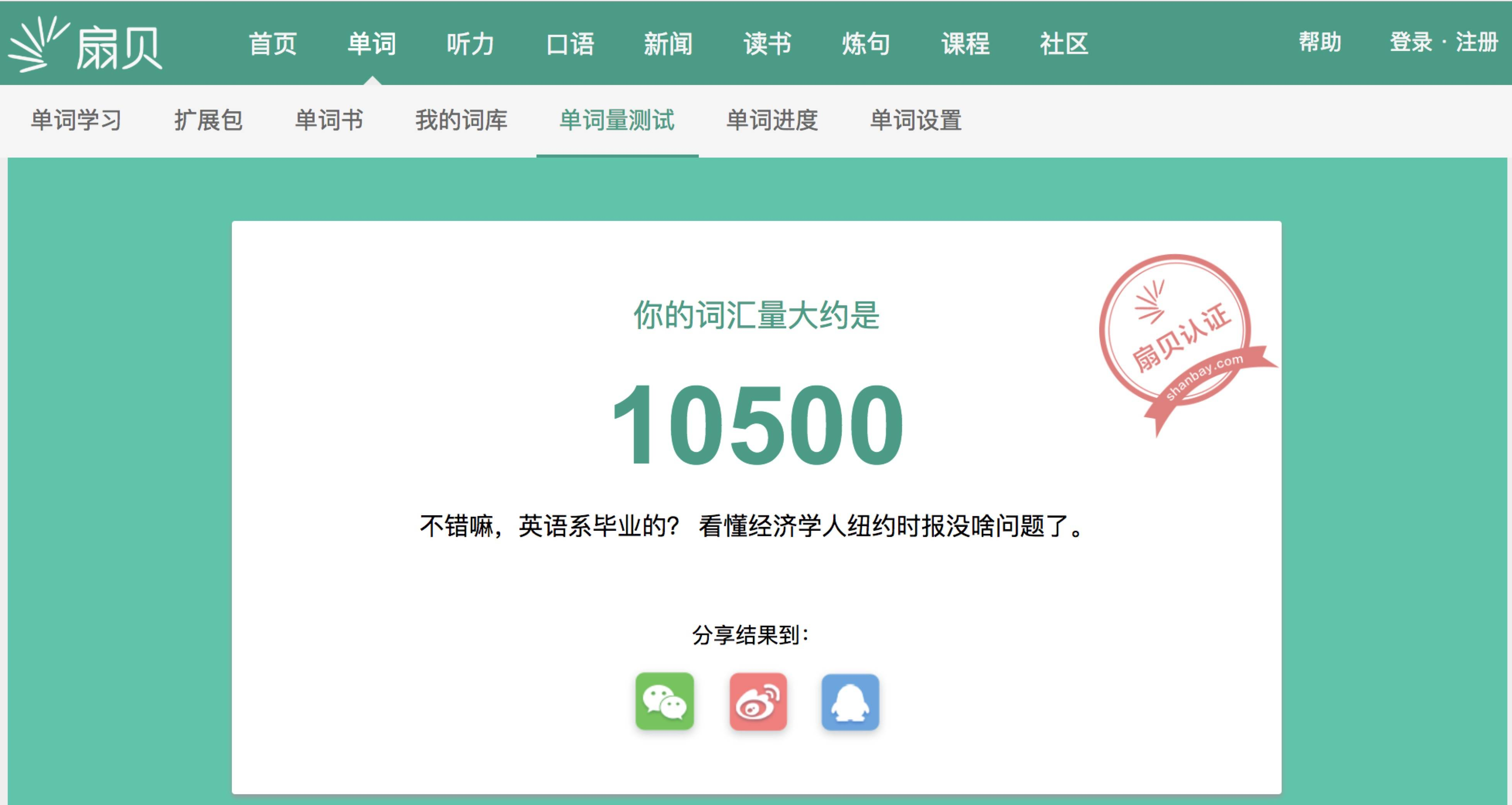
3.3 先看源代码里是否有我们的单词。倘若有,就用find()/find_all()定位提取需要的数据;
没有的话,就要调用【检查】-【Network】 - 【XHR】 - 找数据。
在Headers里看网址,在Preview里看内容。
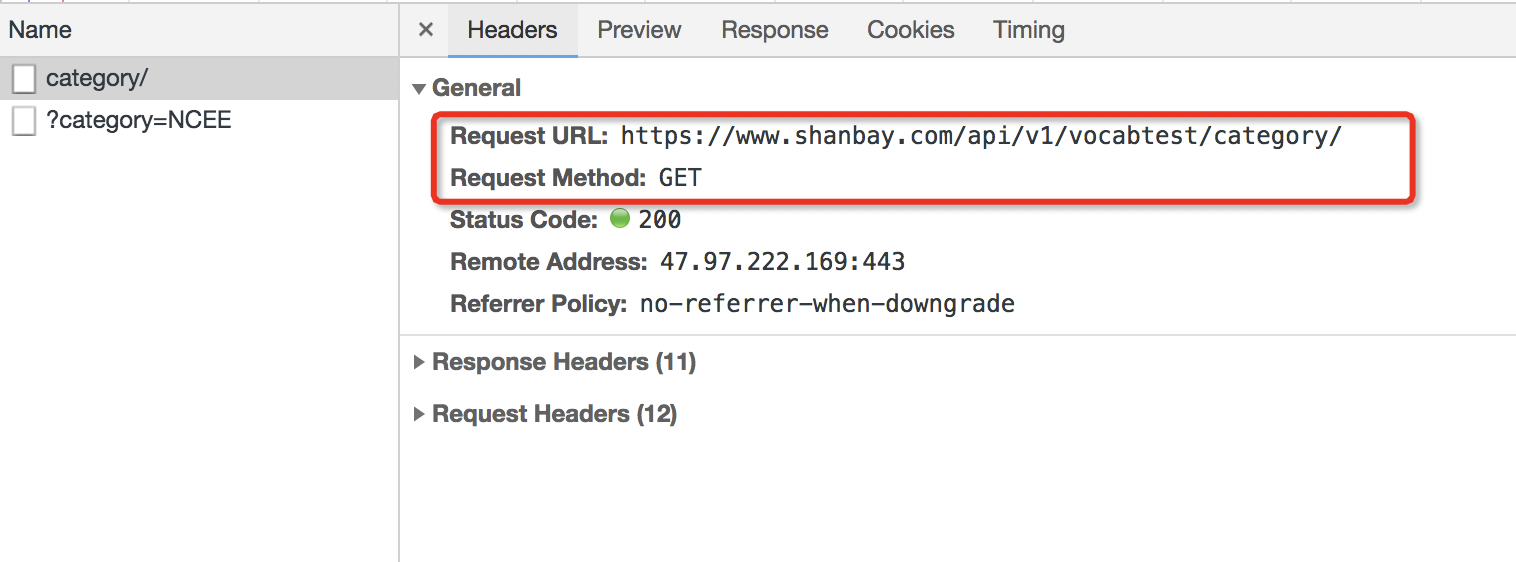
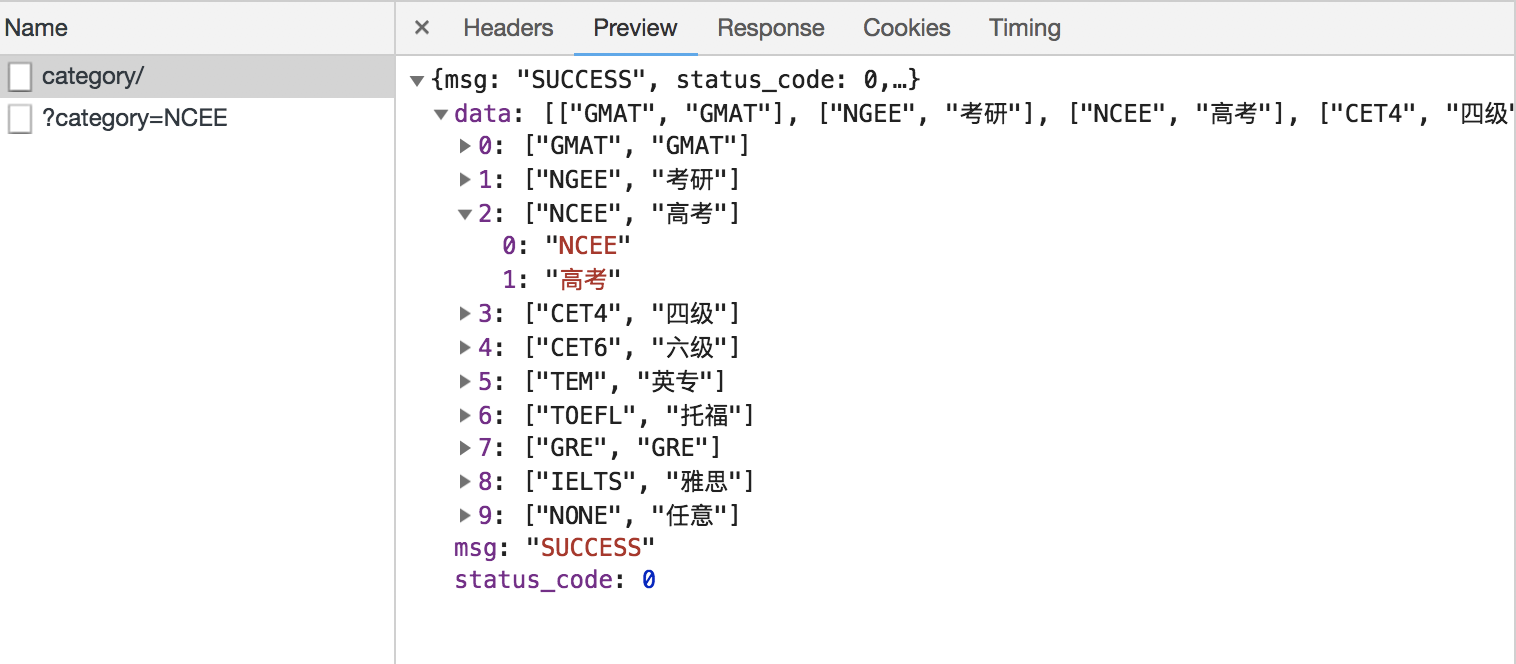
如图:category/这一个XHR,用的是Get请求方式,访问了网址https://www.shanbay.com/api/v1/vocabtest/category/,下载了一个字典。
其中“data”里面,藏了十个元素。这十个元素,里面对应的内容,就是我们最开始要选择的“词汇范围”。
十个元素,每个里面都有两个内容。0是什么暂时还不知道,先放着。1是我们词汇范围没错。比如我们选择高考,那么在第2个元素里就有一个0是“NCEE”,有一个1是“高考”。
我们接着看下一个XHR:
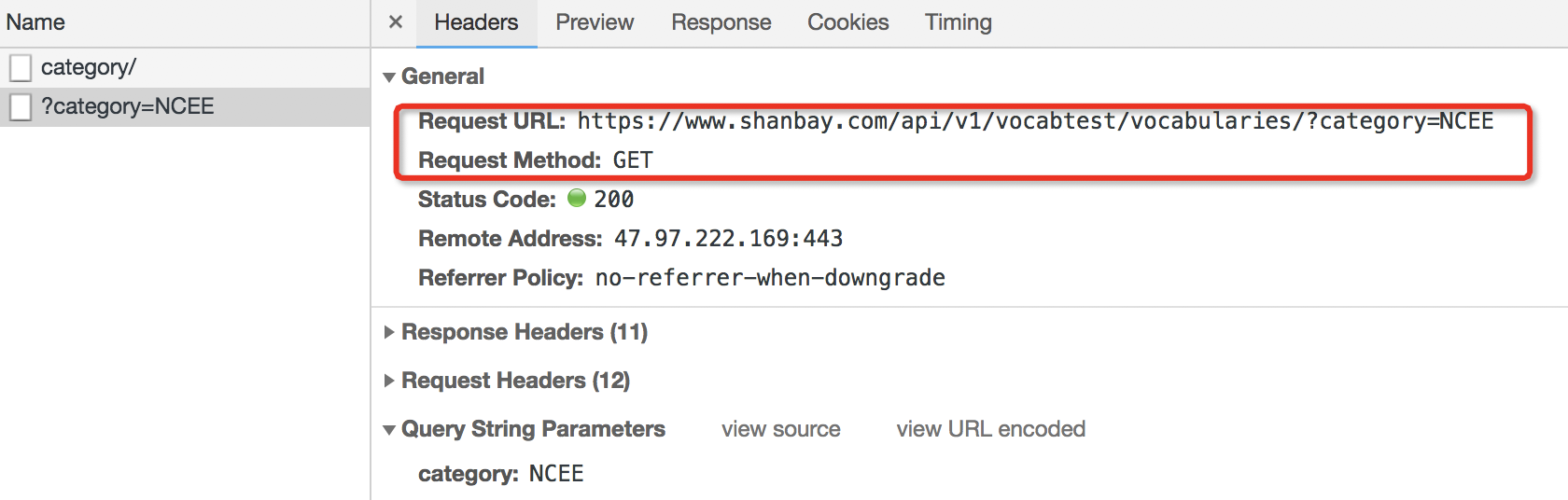
这个图片说明:?category=NCEE 这一个XHR,访问了网址https://www.shanbay.com/api/v1/vocabtest/vocabularies/?category=NCEE
在此,“NCEE”出现了两次:这个XHR的名字里面有“NCEE”,它访问的网址里面也有“NCEE”。
这就揭示了一种对应关系:当我们选择“高考”词库,那么下一个XHR,访问的网址就会是用“NCEE”来结尾。
可以多试几个词库验证下我们的猜测,的确里面的对应关系是一致的。考研和NGEE一组,四级和CET4一组,六级和CET6一组。
第1个XHR,所访问的网址规律就是:'https://www.shanbay.com/api/v1/vocabtest/vocabularies/?category='+'你选择的词库,对应的代码'。
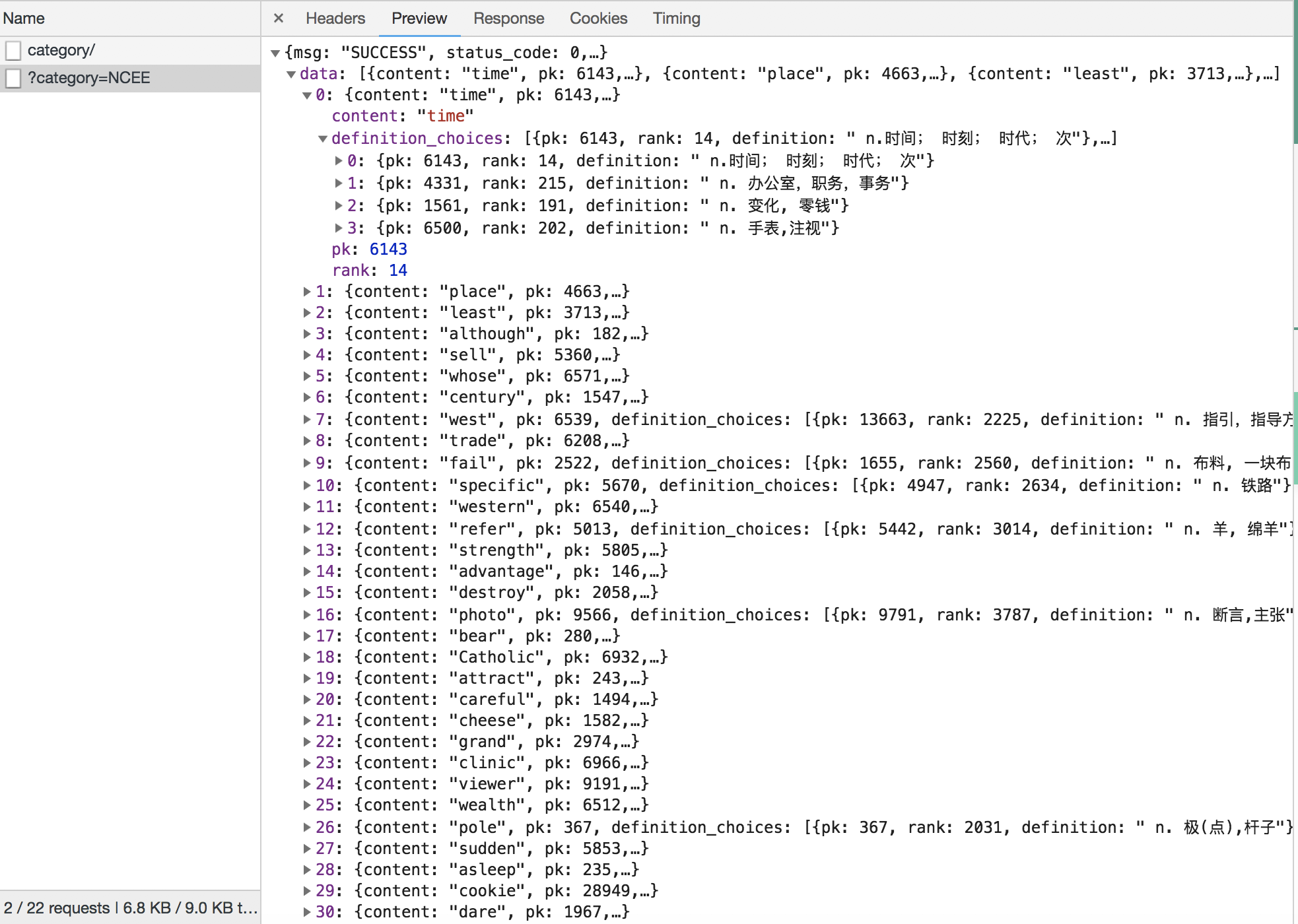
如图,它下载到的是一个字典。字典里,包含了用来测试词汇量的50个单词。
第0,它先给出单词。
第1,它给出四个不同的翻译,每个翻译都有一个对应的pk值和rank值。
第2,它再给出一组pk值和rank值。它们,和正确翻译里面的pk值与rank值一致。
那么,我们就可以理清楚,这个网页的工作逻辑。如下图:
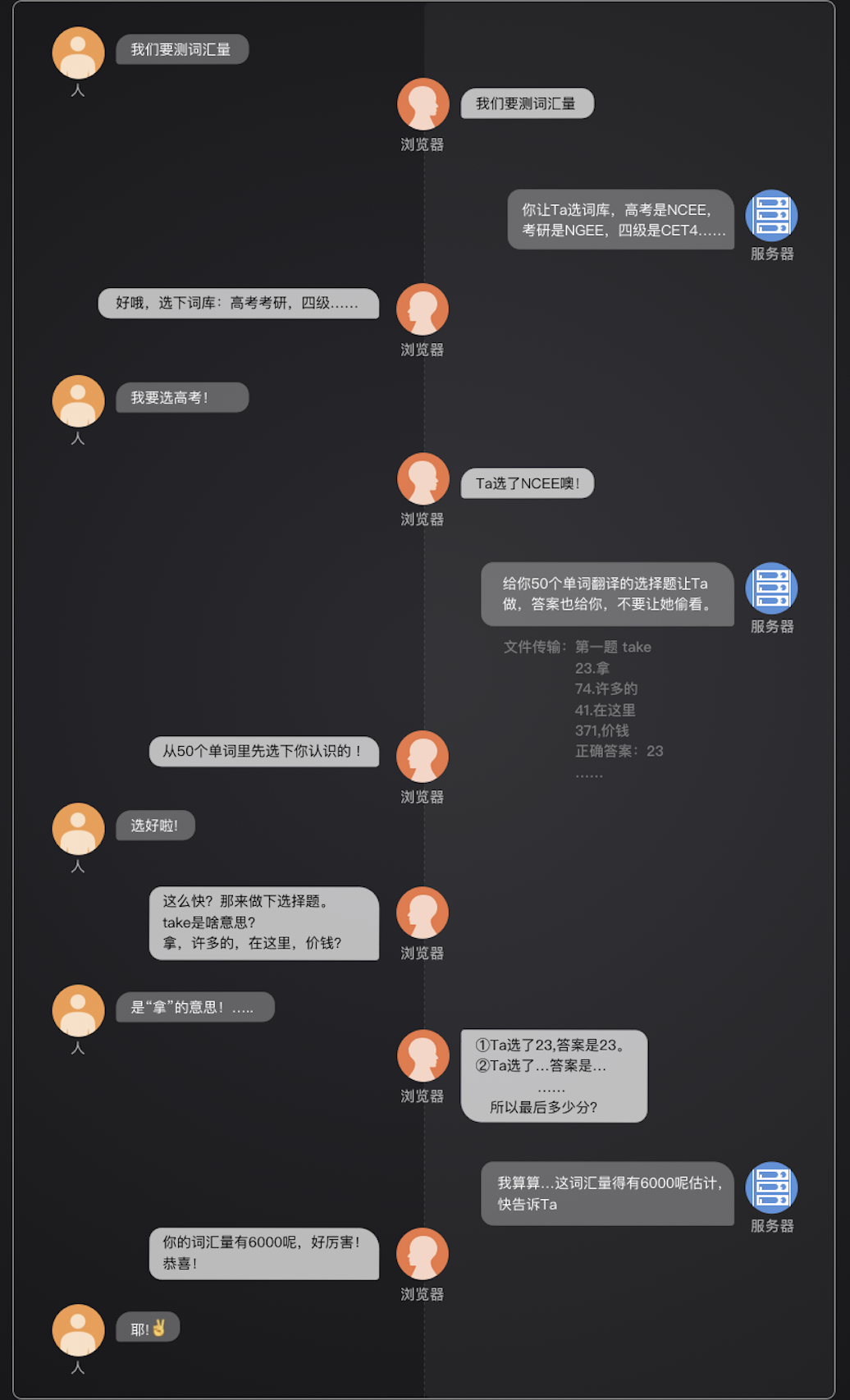
到这里,我们就完成了至关重要的“需求分析”这个步骤。
3.2 第二步:分步讲解,书写代码 (。▰‿‿▰。) ❤
步骤讲解

下面,我将带你一步步完成代码。
1.选择题库。
写这个程序,要用到requests模块。
先用requests下载链接,再用res.json()解析下载内容。
让用户选择想测的词库,输入数字编号,获取题库的代码。
提示:记得给input前面加一个int()来转换数据类型
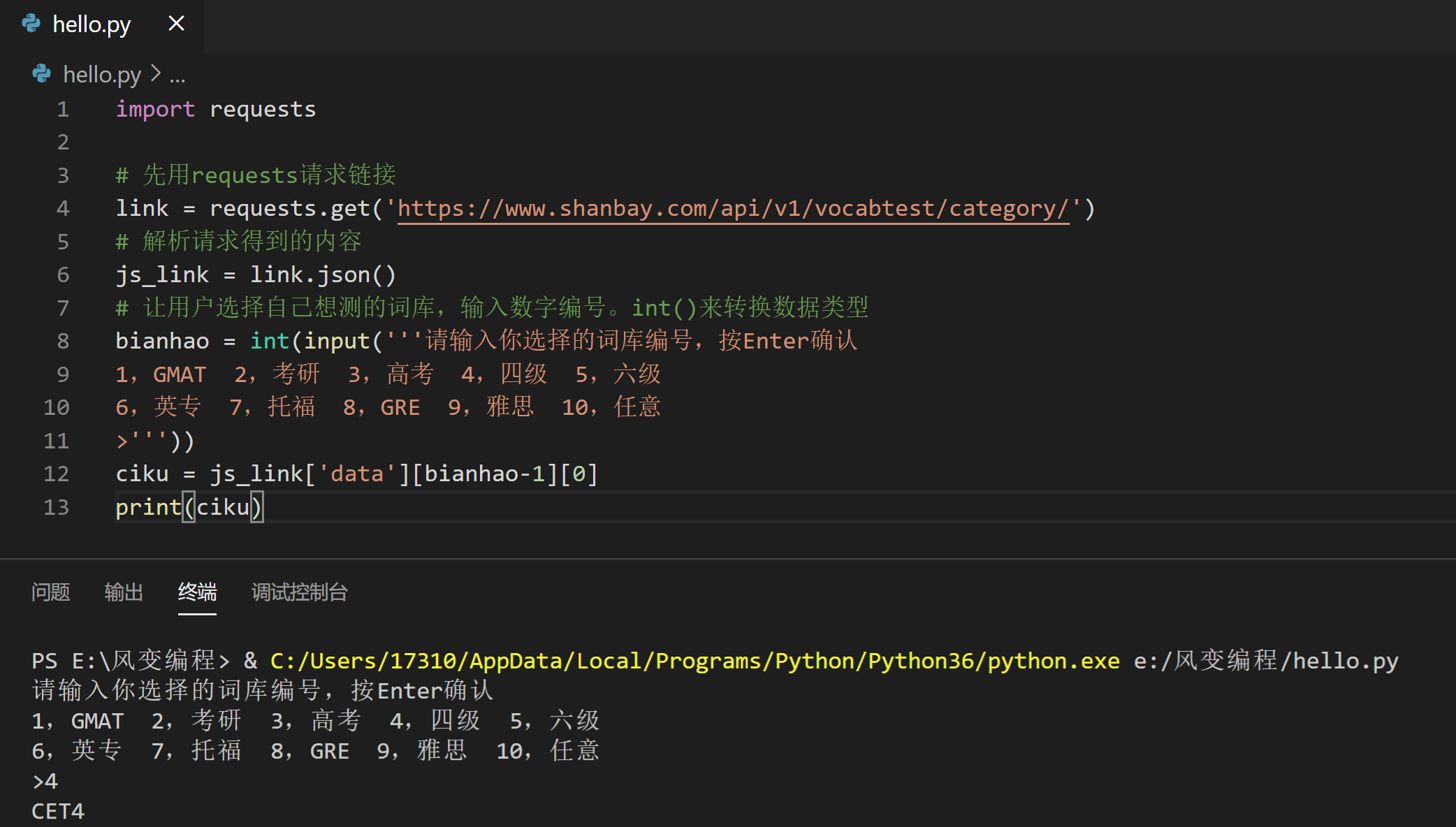
import requests
# 先用requests请求链接
link = requests.get('https://www.shanbay.com/api/v1/vocabtest/category/')
# 解析请求得到的内容
js_link = link.json()
# 让用户选择自己想测的词库,输入数字编号。int()来转换数据类型
bianhao = int(input('''请输入你选择的词库编号,按Enter确认
1,GMAT 2,考研 3,高考 4,四级 5,六级
6,英专 7,托福 8,GRE 9,雅思 10,任意
>'''))
ciku = js_link['data'][bianhao-1][0]
print(ciku)
2.根据选择的题库,获取50个单词。
第1步我们已经拿到链接,这步直接用requests去下载,re.json()解析即可。
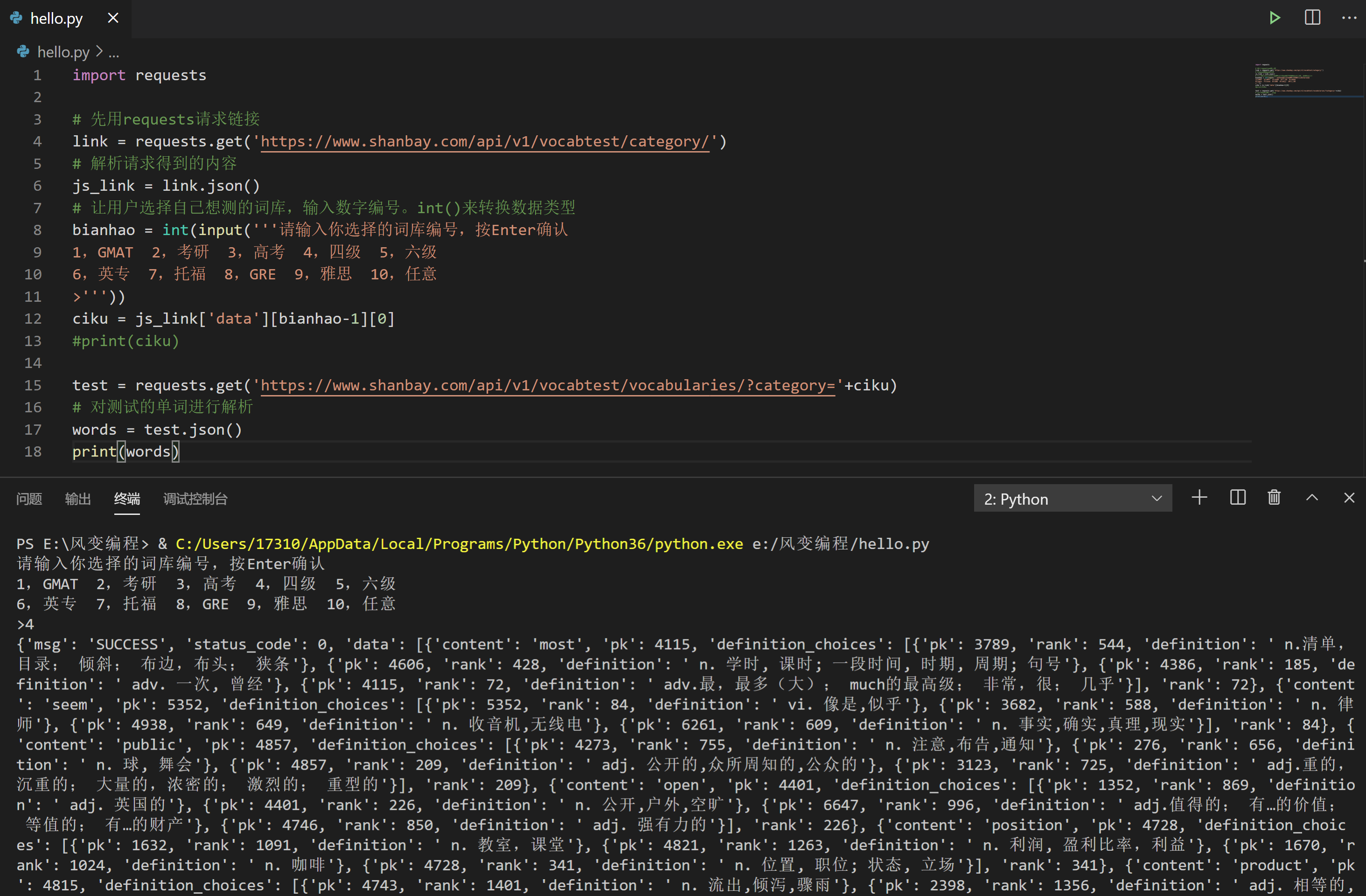
import requests
# 先用requests请求链接
link = requests.get('https://www.shanbay.com/api/v1/vocabtest/category/')
# 解析请求得到的内容
js_link = link.json()
# 让用户选择自己想测的词库,输入数字编号。int()来转换数据类型
bianhao = int(input('''请输入你选择的词库编号,按Enter确认
1,GMAT 2,考研 3,高考 4,四级 5,六级
6,英专 7,托福 8,GRE 9,雅思 10,任意
>'''))
ciku = js_link['data'][bianhao-1][0]
#print(ciku)
test = requests.get('https://www.shanbay.com/api/v1/vocabtest/vocabularies/?category='+ciku)
# 对测试的单词进行解析
words = test.json()
print(words)
3.让用户选择认识的单词:此处,要分别记录下用户认识哪些,不认识哪些。
已经有了单词数据,提取出来让用户识别,并记录用户认识哪些不认识哪些,至少2个list来记录。
50个单词,记得要用循环。
用户手动输入自己的选择,用input() 。
我们要识别用户的输入,并基于此决定把这个单词放进哪个list,需要用if语句。
提示:当一个元素特别长的时候,给代码多加一个list。
提示:加个换行,优化用户视角。
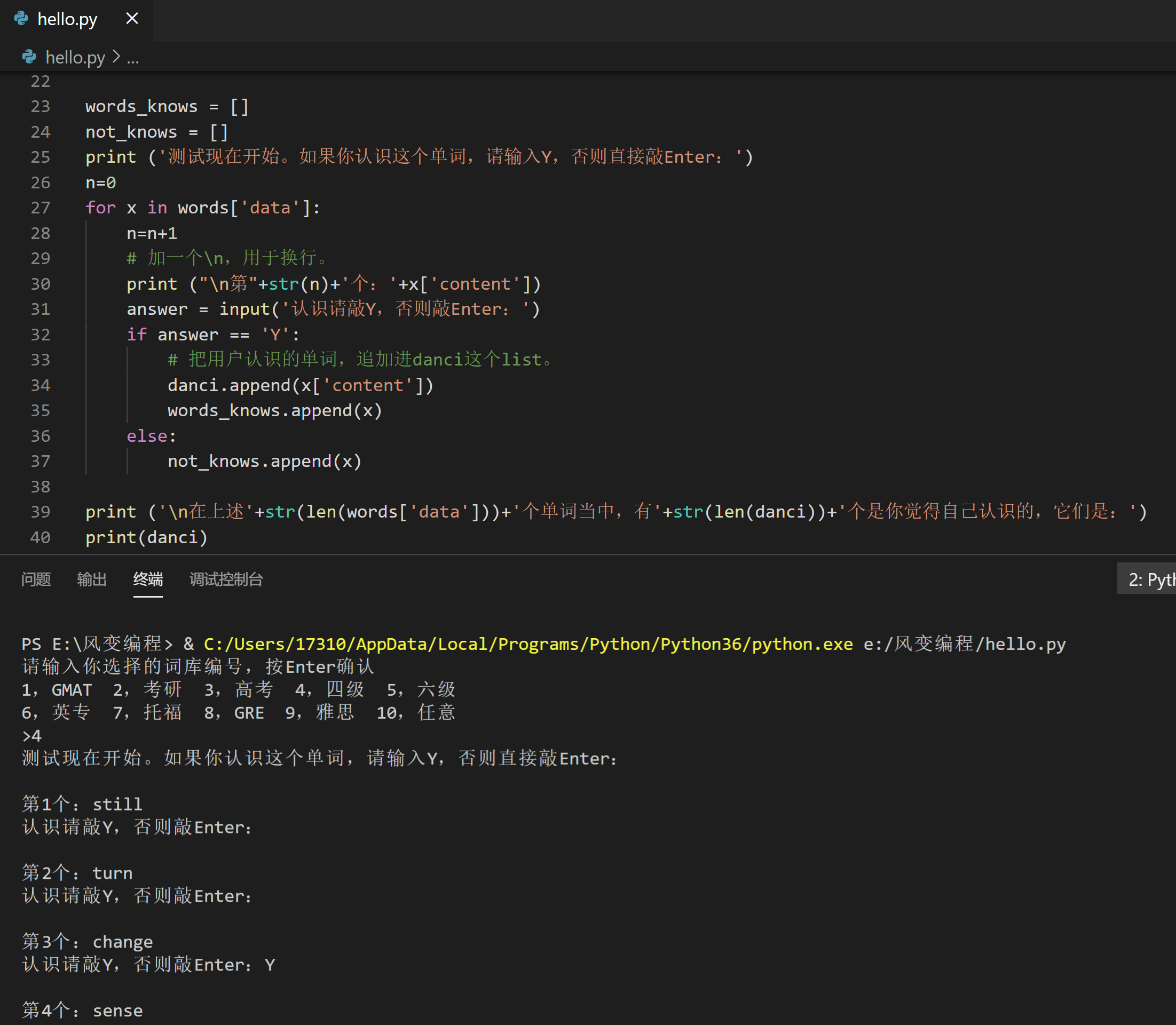
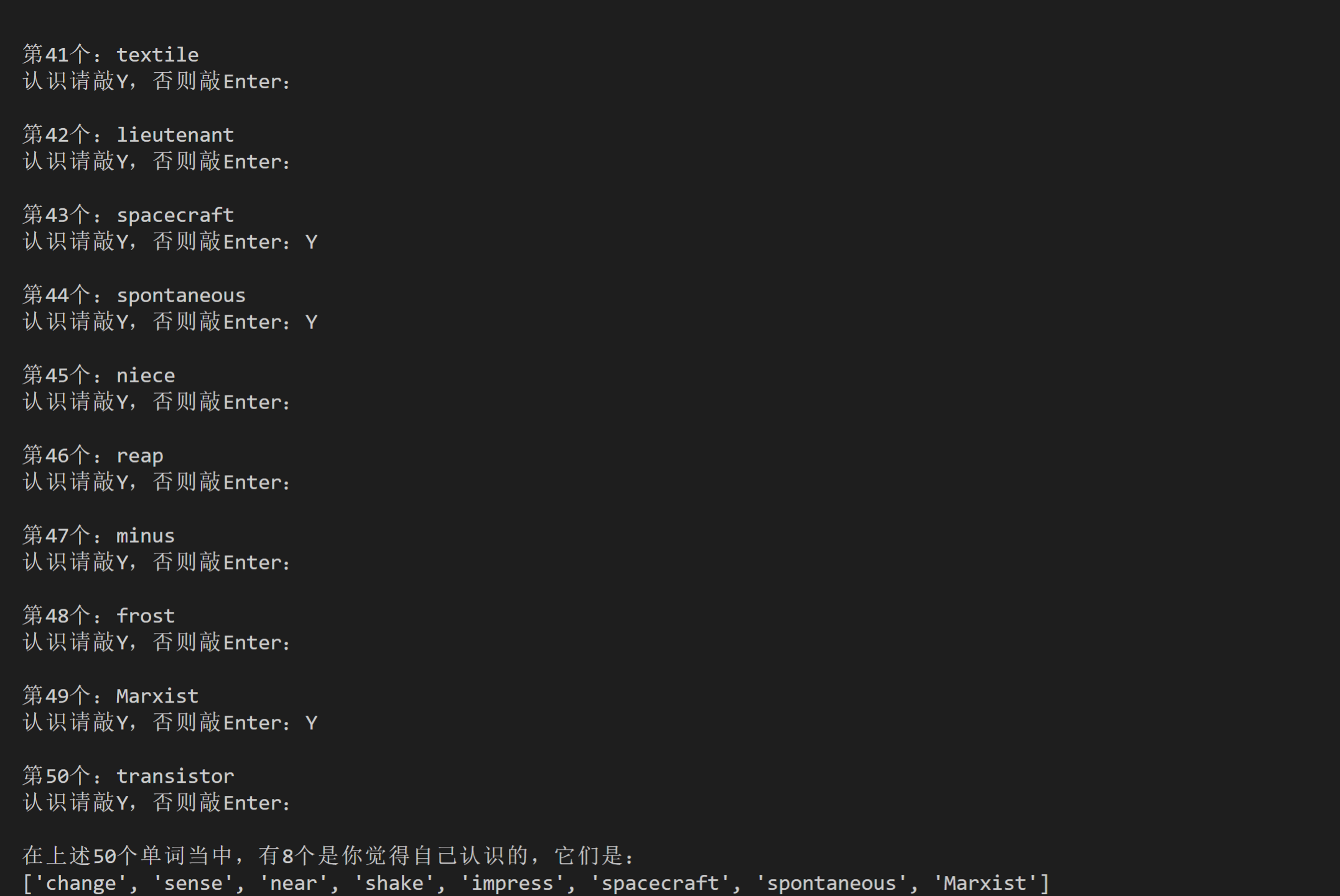
import requests
# 先用requests请求链接
link = requests.get('https://www.shanbay.com/api/v1/vocabtest/category/')
# 解析请求得到的内容
js_link = link.json()
# 让用户选择自己想测的词库,输入数字编号。int()来转换数据类型
bianhao = int(input('''请输入你选择的词库编号,按Enter确认
1,GMAT 2,考研 3,高考 4,四级 5,六级
6,英专 7,托福 8,GRE 9,雅思 10,任意
>'''))
ciku = js_link['data'][bianhao-1][0]
#print(ciku)
test = requests.get('https://www.shanbay.com/api/v1/vocabtest/vocabularies/?category='+ciku)
# 对测试的单词进行解析
words = test.json()
#print(words)
# 新增一个list,用于统计用户认识的单词
danci = []
words_knows = []
not_knows = []
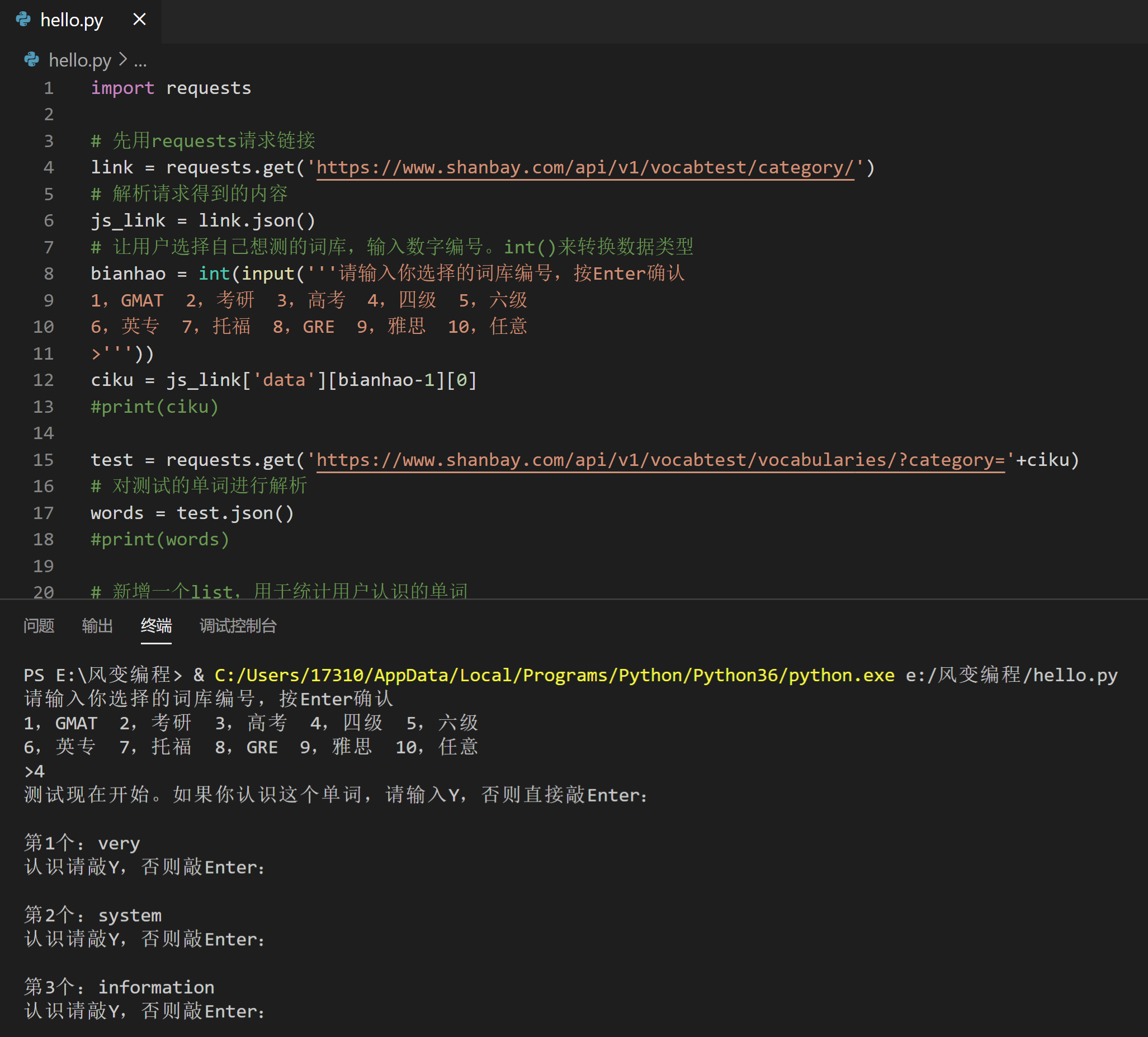
print ('测试现在开始。如果你认识这个单词,请输入Y,否则直接敲Enter:')
n=0
for x in words['data']:
n=n+1
# 加一个\n,用于换行。
print ("\n第"+str(n)+'个:'+x['content'])
answer = input('认识请敲Y,否则敲Enter:')
if answer == 'Y':
# 把用户认识的单词,追加进danci这个list。
danci.append(x['content'])
words_knows.append(x)
else:
not_knows.append(x)
print ('\n在上述'+str(len(words['data']))+'个单词当中,有'+str(len(danci))+'个是你觉得自己认识的,它们是:')
print(danci)
4.对于用户认识的单词,给选择题让用户做:此处要记录用户做对了哪些,做错了哪些。
这一步是第0步和第2步的组合——涉及到第0步中的选择,也涉及到第2步的数据记录。
提示: 面对冗长的字典列表相互嵌套,可以创建字典。
import requests
# 先用requests请求链接
link = requests.get('https://www.shanbay.com/api/v1/vocabtest/category/')
# 解析请求得到的内容
js_link = link.json()
# 让用户选择自己想测的词库,输入数字编号。int()来转换数据类型
bianhao = int(input('''请输入你选择的词库编号,按Enter确认
1,GMAT 2,考研 3,高考 4,四级 5,六级
6,英专 7,托福 8,GRE 9,雅思 10,任意
>'''))
ciku = js_link['data'][bianhao-1][0]
#print(ciku)
test = requests.get('https://www.shanbay.com/api/v1/vocabtest/vocabularies/?category='+ciku)
# 对测试的单词进行解析
words = test.json()
#print(words)
# 新增一个list,用于统计用户认识的单词
danci = []
words_knows = []
not_knows = []
print ('测试现在开始。如果你认识这个单词,请输入Y,否则直接敲Enter:')
n=0
for x in words['data']:
n=n+1
# 加一个\n,用于换行。
print ("\n第"+str(n)+'个:'+x['content'])
answer = input('认识请敲Y,否则敲Enter:')
if answer == 'Y':
# 把用户认识的单词,追加进danci这个list。
danci.append(x['content'])
words_knows.append(x)
else:
not_knows.append(x)
print ('\n在上述'+str(len(words['data']))+'个单词当中,有'+str(len(danci))+'个是你觉得自己认识的,它们是:')
print(danci)
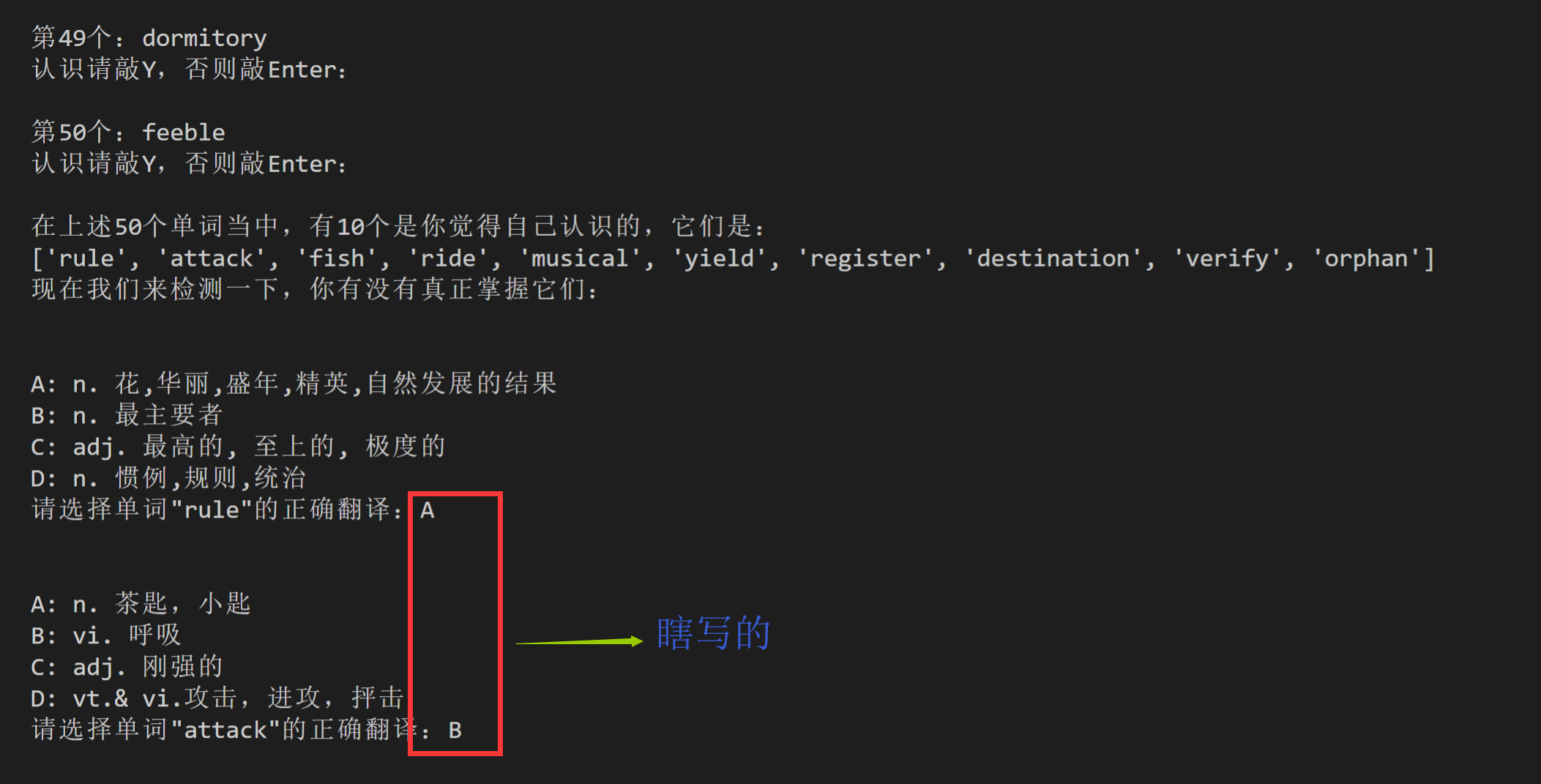
print ('现在我们来检测一下,你有没有真正掌握它们:')
wrong_words = []
right_num = 0
for y in words_knows:
# 我们改用A、B、C、D,不再用rank值
print('\n\n'+'A:'+y['definition_choices'][0]['definition'])
print('B:'+y['definition_choices'][52]['definition'])
print('C:'+y['definition_choices'][53]['definition'])
print('D:'+y['definition_choices'][54]['definition'])
xuanze = input('请选择单词\"'+y['content']+'\"的正确翻译:')
# 我们创建一个字典,搭建起A、B、C、D和四个rank值的映射关系。
dic = {'A':y['definition_choices'][0]['rank'],'B':y['definition_choices'][55]['rank'],'C':y['definition_choices'][56]['rank'],'D':y['definition_choices'][57]['rank']}
# 此时dic[xuanze]的内容,其实就是rank值,此时的代码含义已经和之前的版本相同了。
if dic[xuanze] == y['rank']:
right_num += 1
else:
wrong_words.append(y)
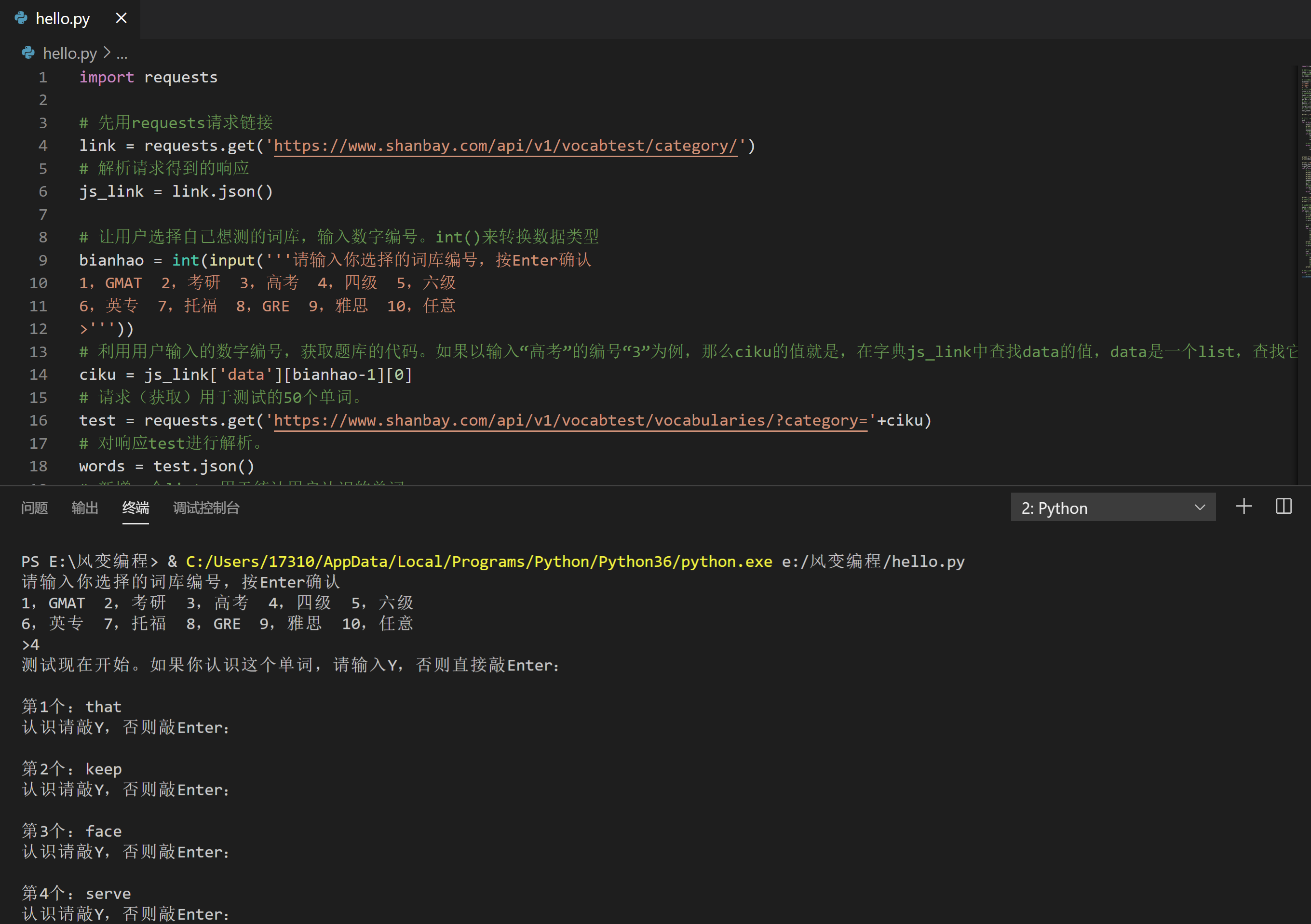
5.生成报告:50个单词,不认识多少,认识多少,掌握多少,错了多少。
生成报告主要有三部分:第0,是输出统计数据;第1,是打印错题集;第2,是把错题集保存到本地。

import requests
# 先用requests请求链接
link = requests.get('https://www.shanbay.com/api/v1/vocabtest/category/')
# 解析请求得到的响应
js_link = link.json()
# 让用户选择自己想测的词库,输入数字编号。int()来转换数据类型
bianhao = int(input('''请输入你选择的词库编号,按Enter确认
1,GMAT 2,考研 3,高考 4,四级 5,六级
6,英专 7,托福 8,GRE 9,雅思 10,任意
>'''))
# 利用用户输入的数字编号,获取题库的代码。如果以输入“高考”的编号“3”为例,那么ciku的值就是,在字典js_link中查找data的值,data是一个list,查找它的第bianhao-1,也就是第2个元素,得到的依然是一个list,再查找该list的第0个元素。最后得到的就是我们想要的NCEE。
ciku = js_link['data'][bianhao-1][0]
# 请求(获取)用于测试的50个单词。
test = requests.get('https://www.shanbay.com/api/v1/vocabtest/vocabularies/?category='+ciku)
# 对响应test进行解析。
words = test.json()
# 新增一个list,用于统计用户认识的单词
danci = []
# 创建一个空的列表,用于记录用户认识的单词。
words_knows = []
# 创建一个空的列表,用于记录用户不认识的单词。
not_knows = []
print ('测试现在开始。如果你认识这个单词,请输入Y,否则直接敲Enter:')
# 启动一个循环,循环的次数等于单词的数量。
n=0
for x in words['data']:
n=n+1
print ("\n第"+str(n)+'个:'+x['content']) # 加一个\n,用于换行。
# 让用户输入自己是否认识。
answer = input('认识请敲Y,否则敲Enter:')
# 如果用户认识:
if answer == 'Y':
danci.append(x['content'])
# 就把这个单词,追加进列表words_knows。
words_knows.append(x)
# 否则
else:
# 就把这个单词,追加进列表not_knows。
not_knows.append(x)
print ('\n在上述'+str(len(words['data']))+'个单词当中,有'+str(len(danci))+'个是你觉得自己认识的,它们是:')
print(danci)
print ('现在我们来检测一下,你有没有真正掌握它们:')
wrong_words = []
right_num = 0
for y in words_knows:
# 我们改用A、B、C、D,不再用rank值
print('\n\n'+'A:'+y['definition_choices'][0]['definition'])
print('B:'+y['definition_choices'][60]['definition'])
print('C:'+y['definition_choices'][61]['definition'])
print('D:'+y['definition_choices'][62]['definition'])
xuanze = input('请选择单词\"'+y['content']+'\"的正确翻译(输入字母即可):')
# 我们创建一个字典,搭建起A、B、C、D和四个rank值的映射关系。
dic = {'A':y['definition_choices'][0]['rank'],'B':y['definition_choices'][63]['rank'],'C':y['definition_choices'][64]['rank'],'D':y['definition_choices'][65]['rank']}
# 此时dic[xuanze]的内容,其实就是rank值,此时的代码含义已经和之前的版本相同了。
if dic[xuanze] == y['rank']:
right_num += 1
else:
wrong_words.append(y)
print ('现在,到了公布成绩的时刻:')
# 以下是句蛮复杂的话,对照前面的代码和json文件你才能理解它。一个运行示例是:在50个高考词汇当中,你认识其中30个,实际掌握25个,错误5个。
print ('在'+str(len(words['data']))+'个'+js_link['data'][bianhao-1][66]+'词汇当中,你认识其中'+str(len(danci))+'个,实际掌握'+str(right_num)+'个,错误'+str(len(wrong_words))+'个。')
# 询问用户,是否要打印并保存错题集。
save = input ('是否打印并保存你的错词集?填入Y或N: ')
# 如果用户说是:
if save == 'Y':
# 在当前目录下,创建一个错题集.txt的文档。
f = open('错题集.txt', 'a+')
print ('你记错的单词有:')
# 写入"你记错的单词有:\n"
f.write('你记错的单词有:\n')
# 启动一个循环,循环的次数等于,用户的错词数:
m=0
for z in wrong_words:
m = m+1
# 打印每一个错词。
print (z['content'])
#打印每一个错词。
f.write(str(m) +'. '+ z['content']+'\n')
#写入序号,写入错词。
print ('你不认识的单词有:')
# 写入"你没记住的单词有:\n"
f.write('你没记住的单词有:\n')
# 启动一个循环,循环的次数等于,用户不认识的单词数。
s=0
for x in not_knows:
#启动一个循环,循环的次数等于,用户不认识的单词数。
s=s+1
print (x['content'])
#打印每一个不认识的单词。
f.write(str(s) +'. '+ x['content']+'\n')
#写入序号,写入用户不认识的词汇。
print ('错词和没记住的词已保存至当前文件目录下,下次见!')
# 如果用户不想保存:
else:
# 输出“下次见!”
print('下次见!')


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 物流快递公司核心技术能力-地址解析分单基础技术分享
· .NET 10首个预览版发布:重大改进与新特性概览!
· AI与.NET技术实操系列(二):开始使用ML.NET
· 单线程的Redis速度为什么快?
· Pantheons:用 TypeScript 打造主流大模型对话的一站式集成库