某个应用的CPU使用率居然达到100%,我该怎么做?(三)
某个应用的CPU使用率居然达到100%,我该怎么做?(三)
1. 引
你们好,可爱的小伙伴们_!
咱们最常用什么指标来描述系统的CPU性能呢?我想你的答案,可能不是平均负载,也不是CPU上下文切换,而是另一个更直观的指标----> CPU使用率。
CPU使用率是单位时间内CPU使用情况的统计,以百分比的方式展示。那么,作为最常用也是最熟悉的CPU指标,你能说出CPU使用率到底是怎么算出来的吗?再有,诸如top,ps之类的性能工具展示的%user,%nice,%system,%iowait,%steal等等,你又能弄清楚他们之间的不同吗?
2. 什么是CPU使用率?
Linux作为一个多任务操作系统,将每个CPU的时间划分为很短的时间片,再通过调度器轮流分配给各个任务使用,因此造成多任务同时运行的错觉。
为了维护CPU时间,Linux通过事先定义的节拍率(内核中表示为HZ),触发时间中断,并使用全局变量Jiffies记录了开机以来的节拍数。每发生一次时间中断,Jiffies的值就加1。
节拍率HZ是内核的可配选项,可以设置为100,250,1000等。不同的系统可能设置不同数值,你可以通过查询/boot/config内核选项来查看它的配置值。比如在我的系统中,节拍率设置成了1000,也就是每秒钟触发1000次时间中断。
[root@localhost ~]# cat /etc/redhat-release
CentOS Linux release 7.6.1810 (Core)
[root@localhost ~]# uname -r
3.10.0-957.21.3.el7.x86_64
[root@localhost ~]# grep 'CONFIG_HZ=' /boot/config-$(uname -r)
CONFIG_HZ=1000
同时,正因为节拍率HZ是内核选项,所以用户空间程序并不能直接访问。为了方便用户空间程序,内核还提供了一个用户空间节拍率USER_HZ,他总是固定为100,也就是1/100秒。这样,用户空间程序并不需要关心内核中HZ被设置成了多少,因为它看到的总是固定值USER_HZ。
Linux通过/proc虚拟文件系统,向用户空间提供了系统内部状态的信息,而/proc/stat提供的就是系统的CPU和任务统计信息。比方说,如果你只关注CPU的话,可以执行下面的命令:
# 只保留各个CPU的数据
[root@localhost ~]# cat /proc/stat | grep ^cpu
cpu 37794 3 228983 1342053 54 0 36 0 0 0
cpu0 18587 2 114774 671151 38 0 7 0 0 0
cpu1 19207 1 114209 670901 16 0 29 0 0 0
这里的输出结果是一个表格。其中,第一列表示的是CPU编号,如cpu0,cpu1,而第一行没有编号的cpu,表示的是所有CPU的累加。其他列则表示不同场景下CPU的累加节拍数,它的单位是USER_HZ,也就是10ms(1/100秒),所以这其实就是不同场景下的CPU时间。
当然,这里每一列的顺序并不需要你背下来。但是需要尽量清楚每一列的涵义,他们都是CPU使用率相关的重要指标,我们以后会在很多其他的性能工具中看到他们。
- user(通常缩写为us): 代表用户态CPU时间。(注意:它并不包括下面的nice时间,但是包括了guest时间)
- nice(通常缩写为ni): 代表低优先级用户态CPU时间,也就是进程的nice值被调整为1-19之间时的CPU时间(注意:nice可取值范围是-20到19,数值越大,优先级反而越低)
- system(通常缩写为sys): 代表内核态CPU时间
- idle(通常缩写为id): 代表空闲时间。(注意:它不包括等待I/O的时间--> iowait)
- iowait(通常缩写为wa): 代表等待I/O的CPU时间
- irq(通常缩写为hi): 代表处理硬中断的CPU时间
- softirq(通常缩写为si): 代表处理软中断的CPU时间
- steal(通常缩写为st): 代表当系统运行在虚拟机中的时候,被其他虚拟机占用的CPU时间
- guest(通常缩写为guest): 代表通过虚拟化运行其他操作系统的时间,也就是运行虚拟机的CPU时间
- guest_nice(通常缩写为gnice): 代表以低优先级运行虚拟机的时间
而我们通常所说的CPU使用率,就是除了空闲时间外的其他时间占总CPU时间的百分比,用公式来表示就是:
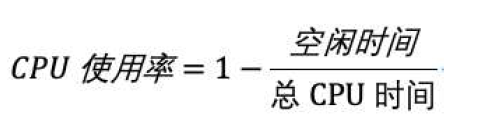
根据这个公式,我们就可以从/proc/stat中的数据,很容易地计算出CPU使用率。当然,也可以用每一个场景的CPU时间,除以总的CPU时间,计算出每个场景的CPU使用率。
不过,先不要着急计算,你能说出,直接用/proc/stat的数据,算的是什么时间段的CPU使用率吗?
看到这里,你应该想起来了,这是开机以来的节拍数累加值,所以直接算出来的,是开机以来的平均CPU使用率,一般并没有什么参考价值。
事实上,为了计算CPU使用率,性能工具一般都会取间隔一段时间(比如3秒)的两次值,作差后,再计算出这段时间内的平均CPU使用率,即

这个公式,就是我们用各种性能工具所看到的CPU使用率的实际计算方法。
因此,我们要分析CPU使用率,通过各种各样的性能分析工具就可以。而不非得去看/proc/stat文件。不过要注意的是,性能分析工具给出的都是间隔一段时间的平均CPU使用率,所以要注意间隔时间的设置,特别是用多个工具对比分析时,你一定要保证他们用的是相同的间隔时间。
比如,对比一下top和ps这两个工具报告的CPU使用率,默认的结果很可能不一样,因为top默认使用3秒时间间隔,而ps使用的却是进程的整个生命周期。
3. 怎么查看CPU使用率?
知道了CPU使用率的含义后,我们再来看看要怎么查看CPU使用率。说到查看CPU使用率的工具,我猜你第一反应肯定是top和ps。的确,top和ps是最常用的性能分析工具
- top显示了系统总体的CPU和内存使用情况,以及各个进程的资源使用情况。
- ps则只显示了每个进程的资源使用情况。
例如:top的输出格式为:
top - 12:30:10 up 3:35, 2 users, load average: 0.00, 0.01, 0.05
Tasks: 105 total, 1 running, 104 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.0 us, 0.2 sy, 0.0 ni, 99.8 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 7990284 total, 7626660 free, 139272 used, 224352 buff/cache
KiB Swap: 2097148 total, 2097148 free, 0 used. 7581316 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1 root 20 0 125432 3776 2552 S 0.0 0.0 0:01.04 systemd
2 root 20 0 0 0 0 S 0.0 0.0 0:00.01 kthreadd
3 root 20 0 0 0 0 S 0.0 0.0 0:00.02 ksoftirqd/0
5 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kworker/0:0H
7 root rt 0 0 0 0 S 0.0 0.0 0:00.02 migration/0
8 root 20 0 0 0 0 S 0.0 0.0 0:00.00 rcu_bh
9 root 20 0 0 0 0 S 0.0 0.0 0:00.31 rcu_sched
10 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 lru-add-drain
11 root rt 0 0 0 0 S 0.0 0.0 0:00.02 watchdog/0
在这个输出结果中,第三行%CPU就是系统的CPU使用率,具体每一列的含义之前都已经说过了,只是把CPU时间变成了CPU使用率。不过需要注意的是,top默认显示的是所有CPU的平均值,这个时候你只需要按下数字1,就可以切换到每个CPU的使用率了。
继续往下看,空白行之后是进程的实时信息,每个进程都有一个%CPU列,表示进程的CPU使用率。它是用户态和内核态CPU使用率的总和,包括进程用户空间使用的CPU,通过系统调用执行的内核空间CPU,以及在就绪队列等待运行的CPU。在虚拟化环境中,它还包括了运行虚拟机占用的CPU。
所以,到这里我们可以发现,top并没有细分进程的用户态CPU和内核态CPU。那要怎么查看每个进程的详细情况呢? pidstat,它正是一个专门分析每个进程CPU使用情况的工具。
比如,下面的pidstat命令,就间隔1秒展示了进程的5组CPU使用率,包括:
- 用户态CPU使用率(%usr)
- 内核态CPU使用率(%system)
- 运行虚拟机CPU使用率(%guest)
- 等待CPU使用率(%wait)
- 总的CPU使用率(%CPU)
最后的Average部分,还计算了5组数据的平均值。
# 每隔1秒输出一组数据,共输出5组
[root@localhost ~]# pidstat 1 5
Linux 3.10.0-957.21.3.el7.x86_64 (localhost.localdomain) 2019年08月06日 _x86_64_ (2 CPU)
22时41分57秒 UID PID %usr %system %guest %wait %CPU CPU Command
22时41分58秒 0 11994 0.00 1.00 0.00 0.00 1.00 0 pidstat
....
Average: UID PID %usr %system %guest %wait %CPU CPU Command
Average: 0 1171 0.20 0.00 0.00 0.00 0.20 - tuned
Average: 0 11994 0.00 0.40 0.00 0.00 0.40 - pidstat
4. CPU使用率过高,怎么分析?
通过top,ps,pidstat等工具,你能够轻松找到CPU使用率较高(比如100%)的进程。接下来,你可能又想知道,占用CPU的到底是代码里的哪个函数呢?找到它,你才能更高效,更针对性地进行优化。
我猜你第一个想到的,应该是GDB(The GNU Project Debugger),这个功能强大的程序调试利器。的确,GDB在调试程序错误方面很强大。但是,请记住GDB并不适合在性能分析的早期应用。
为什么呢?因为GDB调试程序的过程会中断程序运行,这在线上环境往往是不允许的。所以,GDB只适合用在性能分析的后期,当你找到了出问题的大致函数后,线下再借助它来进一步调试函数内部的问题。
那么,哪种工具适合在第一时间分析进程的CPU问题呢?我的推荐是perf。它以性能事件采样为基础,不仅可以分析系统的各种事件和内核性能,还可以用来分析指定应用程序的性能问题。
[root@localhost ~]# yum -y install perf
使用perf分析CPU性能问题,我来说两种最常见的
第一种,常见用法是perf top,类似于top,它能够实时显示占用CPU时钟最多的函数或者指令,因此可以用来查找热点函数,使用界面如下说所示:
[root@localhost ~]# perf top
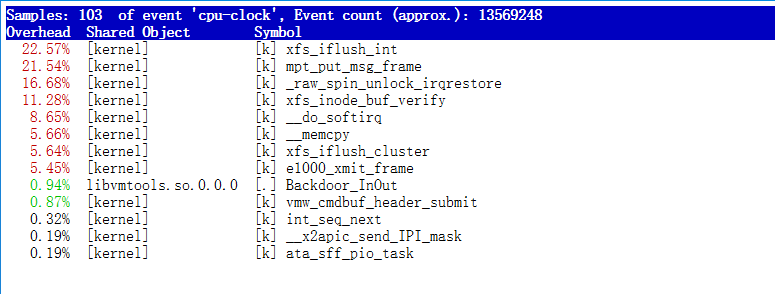
第一行数据
- Samples:采样数
- event:事件类型
- Event count:事件总数量
比如这个例子中:perf总共采集了103个CPU时钟事件,而总事件数则为13569248
另外,采样数需要我们特别注意。如果采样数过少(比如只有十几个),那下面的排序和百分比就没什么实际参考价值了
第二行数据
- 第一列Overhead,是该符号的性能事件在所有采样中的比例,用百分比来表示
- 第二列Shared,是该函数或指令所在的动态共享对象(Dynamic Shared Object),如内核,进程名,动态链接库名,内核模块名等
- 第三列Object,是动态共享对象的类型。比如[.]表示用户空间的可执行程序,或者动态链接库,而[k]则表示内核空间。
- 最后一列Symbol是符号名,也就是函数名。当函数名未知时,用十六进制的地址来表示。
还是以上面的输出为例,我们可以看到,占用CPU时钟最多的是perf工具自身,不过它的比例也只有7.28%,说明系统并没有CPU性能问题。perf top的使用你应该很清楚了把。
接着再来看第二种常见方法,也就是perf record 和 perf report。perf top虽然实时展示了系统的性能信息,但是它的缺点是并不保存数据,也就无法用于离线或者后续的分析。而perf record则提供了保存数据的功能,保存后的数据,需要你用perf report解析展示。
#利用perf record采集静态样本,并保存到本地
[root@localhost ~]# perf record #按Ctrl+C 终止采样
[ perf record: Woken up 23 times to write data ]
[ perf record: Captured and wrote 5.787 MB perf.data (121112 samples) ]
[root@localhost ~]# ls
anaconda-ks.cfg perf.data sysstat-12.1.5-1.x86_64.rpm
[root@localhost ~]# du -sh perf.data #这就是采集到的样本
5.8M perf.data
#对本地的静态样本进行分析
[root@localhost ~]# perf report #会自动打开当前目录下的perf.data
Samples: 121K of event 'cpu-clock', Event count (approx.): 30278000000
Overhead Command Shared Object Symbol
99.86% swapper [kernel.kallsyms] [k] native_safe_halt
0.03% kworker/1:1 [kernel.kallsyms] [k] _raw_spin_unlock_irqrestore
0.01% bash [kernel.kallsyms] [k] _raw_spin_unlock_irqrestore
0.01% sshd [kernel.kallsyms] [k] e1000_xmit_frame
0.01% kworker/u256:3 [kernel.kallsyms] [k] mpt_put_msg_frame
0.00% swapper [kernel.kallsyms] [k] __do_softirq
0.00% sshd [kernel.kallsyms] [k] __memcpy
0.00% bash [kernel.kallsyms] [k] __x2apic_send_IPI_mask
0.00% ps [kernel.kallsyms] [k] __memcpy
0.00% migration/1 [kernel.kallsyms] [k] migration_cpu_stop
0.00% ps [kernel.kallsyms] [k] follow_page_mask
0.00% ps [kernel.kallsyms] [k] vsnprintf
0.00% bash [kernel.kallsyms] [k] __do_page_fault
0.00% kworker/0:1 [kernel.kallsyms] [k] _raw_spin_unlock_irqrestore
0.00% perf [kernel.kallsyms] [k] mem_cgroup_update_page_stat
0.00% ps [kernel.kallsyms] [k] format_decode
在实际使用中,我们还经常为perf top和perf record加上-g参数,开启调用关系的采样,方便我们根据调用链来分析性能问题。
5. 案例分析
下面,我们就以Nginx+PHP的Web服务为例,来看看当你发现CPU使用率过高的问题后,要怎么使用top等工具找出异常的进程,又要怎么利用perf找出引发性能问题的函数。
5.1 环境准备
以下案例基于Centos7.6,同样适用其他Linux操作系统
- 机器配置:2CPU,8GB内存
- 预先安装docker,sysstat,perf,ab等工具
[root@localhost ~]# cat /etc/redhat-release
CentOS Linux release 7.6.1810 (Core)
[root@localhost ~]# uname -r
3.10.0-957.21.3.el7.x86_64
[root@localhost ~]# yum -y install epel-release
[root@localhost ~]# yum -y install httpd-tools sysstat perf
#安装docker
[root@localhost ~]# yum -y install yum-utils device-mapper-persistent-data lvm2
[root@localhost ~]# curl https://download.docker.com/linux/centos/docker-ce.repo -o /etc/yum.repos.d/docker-ce.repo
[root@localhost ~]# yum -y install docker-ce
[root@localhost ~]# systemctl start docker
[root@localhost ~]# systemctl enable docker
Created symlink from /etc/systemd/system/multi-user.target.wants/docker.service to /usr/lib/systemd/system/docker.service.
#添加国内镜像源
[root@localhost ~]# cat /etc/docker/daemon.json
{
"registry-mirrors":[ "https://registry.docker-cn.com" ]
}
[root@localhost ~]# systemctl daemon-reload
[root@localhost ~]# systemctl restart docker
#下载两个镜像
[root@localhost ~]# docker pull feisky/nginx
[root@localhost ~]# docker pull feisky/php-fpm
5.2 操作说明
我们这次需要用到两个虚拟机和一个新的工具ab。
ab : 一个常用的HTTP服务性能测试工具,这里用来模拟Nginx的客户端。
由于Nginx和PHP配置麻烦,我们在这里使用镜像进行模拟
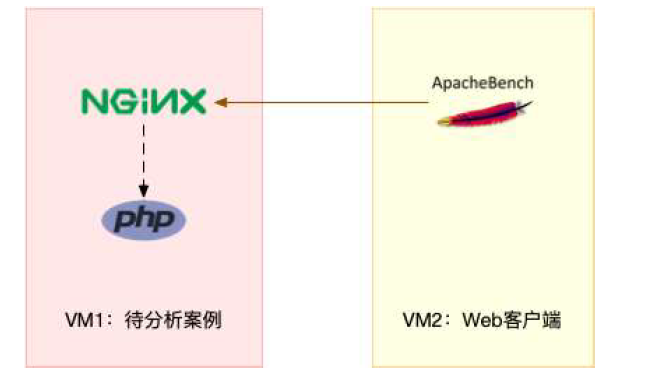
你们可以看到,其中一台用作Web服务器,来模拟性能出现问题;
另外一台用作访问Web服务器的客户端,来给Web服务增加压力请求。
接下来,我们打开两个终端,分别SSH登陆到两台机器上,并安装上面提到的工具。
还是同样的情况。下面的所有命令,都默认假设以root身份运行;
5.3 操作分析
(1)在第一台虚拟机上执行下面的命令来运行Nginx和PHP的服务
[root@LNMP ~]# hostname -I
192.168.200.201
[root@LNMP ~]# docker run --name nginx -p 10000:80 -itd feisky/nginx
[root@LNMP ~]# docker run --name phpfpm -itd --network container:nginx feisky/php-fpm
(2)然后,在第二个终端使用curl访问http://[VM1的IP]:10000,确认Nginx已经正常启动。你应该可以看到It works!的响应。
[root@ab ~]# hostname -I
192.168.200.222
[root@ab ~]# curl http://192.168.200.201:10000
It works!
(3)接着,我们来测试一下,这个Nginx服务的性能。在第二个终端运行下面的ab命令
# 并发10个请求测试Nginx性能,总共测试100个请求
[root@ab ~]# ab -c 10 -n 100 http://192.168.200.201:10000/
This is ApacheBench, Version 2.3 <$Revision: 1430300 $>
Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/
Licensed to The Apache Software Foundation, http://www.apache.org/
Benchmarking 192.168.200.201 (be patient).....done
Server Software: nginx/1.15.4
Server Hostname: 192.168.200.201
Server Port: 10000
Document Path: /
Document Length: 9 bytes
Concurrency Level: 10
Time taken for tests: 6.433 seconds
Complete requests: 100
Failed requests: 0
Write errors: 0
Total transferred: 17200 bytes
HTML transferred: 900 bytes
Requests per second: 15.54 [#/sec] (mean) # Nginx每秒平均处理的请求数
Time per request: 643.333 [ms] (mean) # Nginx处理每个请求平均花费时间
Time per request: 64.333 [ms] (mean, across all concurrent requests)
Transfer rate: 2.61 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 0 1 0.3 1 1
Processing: 114 612 136.3 620 887
Waiting: 114 612 136.4 620 887
Total: 115 613 136.4 621 888
Percentage of the requests served within a certain time (ms)
50% 621
66% 663
75% 684
80% 712
90% 767
95% 818
98% 849
99% 888
100% 888 (longest request)
从ab的输出结果我们可以看到,Nginx能承受的每秒平均请求数只有15.54个。同学们一定会觉得,这也太差了吧。
那么到底是哪里出了问题呢?我们用top和pidstat再来观察下。
这次,我们在第二个终端,将测试的请求数量增加到10000。这样当你在第一个终端使用性能分析工具时,Nginx的压力还是继续的。
(4)继续在第二个终端,运行ab命令:
[root@ab ~]# ab -c 10 -n 10000 http://192.168.200.201:10000/
接着,回到第一个终端运行top命令,并按下数字1,切换到每个CPU的使用率:
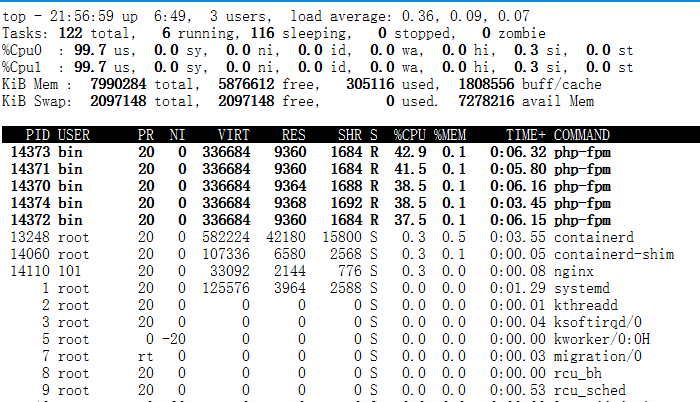
在这里可以看到,系统中有几个php-fpm进程的CPU使用率加起来接近200%;
而每个CPU的用户使用率(us)也已经超过了98%,接近饱和。这样,我们就可以确认,正是用户空间的php-fpm进程,导致CPU使用率骤升。
那么,我们继续进行实验,我们该如何知道是php-fpm的哪个函数导致了CPU使用率升高呢?我们用perf分析一下。
(5)在第一个终端运行下面的perf命令:
# -g 开启调用关系分析,-p指定php-fpm的进程号14372
[root@LNMP ~]# perf top -g -p 14372
我们可以通过键盘上下左右进行移动,移动到php-fpm进程时,利用Enter进行进程的打开操作
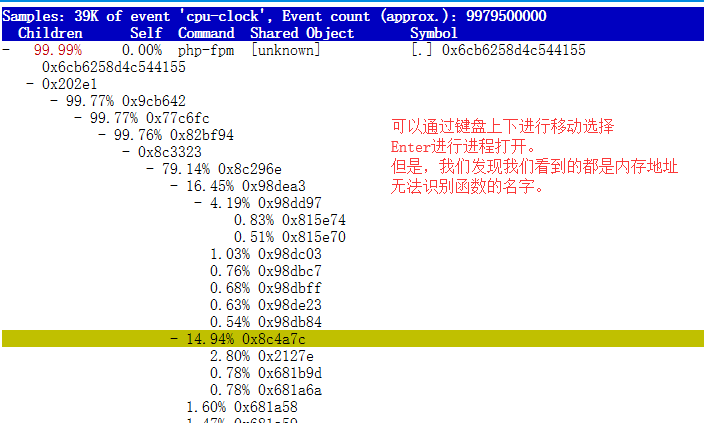
通过perf进行分析,我们发现分析出来的都是内存的地址,具体函数的名字无法识别
这是因为,我们的Web服务器是在容器里的,容器完全封装了软件的运行环境,其中也包含了所需的依赖库函数等
因此,我们在宿主机操作系统上分析,是无法找到对应的容器的依赖函数库的(函数库在容器里,不在操作系统上)
所以,我们需要通过perf record -g -p采集分析报告
而后,将分析报告perf.data复制到容器里后,通过容器里的perf命令进行分析才可以。
(6)生成perf分析报告,复制报告到容器内,进行分析
#生成perf分析报告
[root@LNMP ~]# perf record -g -p 14372
[ perf record: Woken up 17 times to write data ]
[ perf record: Captured and wrote 4.038 MB perf.data (34532 samples) ]
[root@LNMP ~]# ls
anaconda-ks.cfg perf.data
[root@LNMP ~]# du -sh perf.data
4.1M perf.data
#将分析报告拷贝到php-fpm容器中的/tmp目录下
[root@LNMP ~]# docker cp perf.data phpfpm:/tmp
#进行phpfpm容器中
[root@LNMP ~]# docker exec -it phpfpm /bin/bash
root@4ae3d2daa8b8:/app# cd /tmp
#安装perf分析工具(此为Ubentu系统)
root@4ae3d2daa8b8:/tmp# apt-get update && apt-get -y install linux-perf linux-tools procps
#对perf.data进行分析
root@4ae3d2daa8b8:/tmp# perf_4.9 report
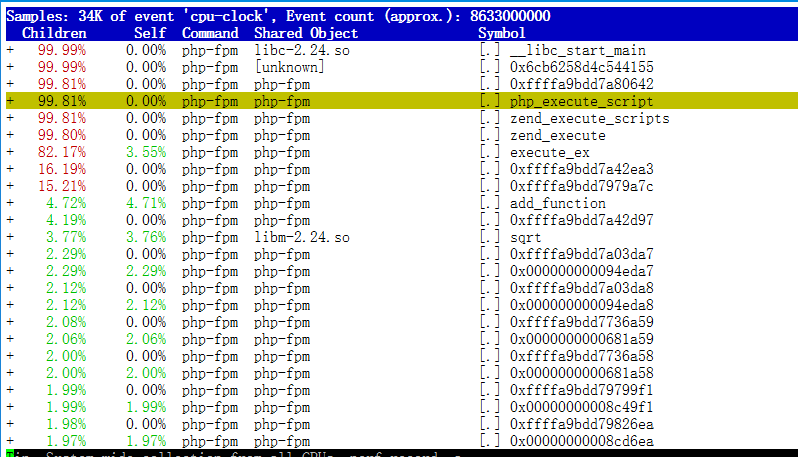
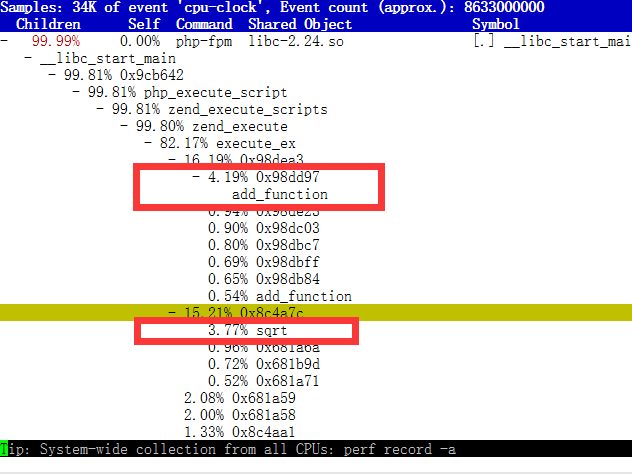
这次通过在容器内的分析,我们发现php-fpm进程一直都在反复调用两个函数名:add_function和sqrt
(7)add_function和sqrt是什么函数代码?
# 将php-fpm容器的网页代码拷贝到宿主机上进行分析
[root@LNMP yunjisuan]# pwd
/root/yunjisuan
[root@LNMP yunjisuan]# ls
[root@LNMP yunjisuan]# docker cp phpfpm:/app .
[root@LNMP yunjisuan]# ls
app
[root@LNMP yunjisuan]# grep -r “sqrt” app/
app/index.php: $x += sqrt($x); #找到了有关sqrt函数的调用,在app目录下的index.php文件里
[root@LNMP yunjisuan]# grep -r "add_function" app/ #这个函数调用没找到,因为这其实是个PHP的内置调用函数
OK,原来只有sqrt函数在app/index.php文件中调用了。那最后一步,我们就该看看这个文件的源代码了。
[root@LNMP yunjisuan]# cat app/index.php
<?php
// test only.
$x = 0.0001;
for ($i = 0; $i <= 1000000; $i++) {
$x += sqrt($x);
}
echo "It works!"
到此应该已经发现,这其实就是一个PHP的测试页代码。
而之所以会出现这个问题,只是因为在发布应用代码的时候,没有删除PHP的测试页代码
因此,我们删除测试页内容再重新启动容器即可
(8)修复Web服务器的测试页问题
[root@localhost ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
9867f918a31c feisky/php-fpm "php-fpm -F --pid /o…" 5 seconds ago Up 4 seconds phpfpm
41db97b9c815 feisky/nginx "nginx -g 'daemon of…" 31 seconds ago Up 31 seconds 0.0.0.0:10000->80/tcp nginx
#进入nginx容器
[root@localhost ~]# docker exec -it nginx /bin/bash
root@41db97b9c815:/# cd app/
root@41db97b9c815:/app# ls
404.html index.php ok.php phpinfo.php
root@41db97b9c815:/app# cat index.php #错误的测试页
<?php
// test only.
$x = 0.0001;
for ($i = 0; $i <= 1000000; $i++) {
$x += sqrt($x);
}
echo "It works!"
?>root@41db97b9c815:/app# cat ok.php #正常页
<?php
echo "It works!"
?>
root@41db97b9c815:/app# cat ok.php > index.php #用正常页内容覆盖测试页内容
#退出nginx容器
root@41db97b9c815:/app# exit
exit
#进入phpfpm容器,修改测试页
[root@localhost ~]# docker exec -it phpfpm /bin/bash
root@41db97b9c815:/app# ls
404.html index.php ok.php phpinfo.php
root@41db97b9c815:/app# cat ok.php > index.php
root@41db97b9c815:/app# exit
exit
#重新启动nginx和phpfpm容器
[root@localhost ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
9867f918a31c feisky/php-fpm "php-fpm -F --pid /o…" 2 minutes ago Up 2 minutes phpfpm
41db97b9c815 feisky/nginx "nginx -g 'daemon of…" 3 minutes ago Up 3 minutes 0.0.0.0:10000->80/tcp nginx
[root@localhost ~]# docker restart nginx phpfpm
nginx
phpfpm
(9)再次对Web服务的虚拟机进行压力测试
[root@ab ~]# ab -c 10 -n 10000 http://192.168.200.201:10000/
This is ApacheBench, Version 2.3 <$Revision: 1430300 $>
Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/
Licensed to The Apache Software Foundation, http://www.apache.org/
Benchmarking 192.168.200.201 (be patient)
Completed 1000 requests
Completed 2000 requests
Completed 3000 requests
Completed 4000 requests
Completed 5000 requests
Completed 6000 requests
Completed 7000 requests
Completed 8000 requests
Completed 9000 requests
Completed 10000 requests
Finished 10000 requests
Server Software: nginx/1.15.4
Server Hostname: 192.168.200.201
Server Port: 10000
Document Path: /
Document Length: 9 bytes
Concurrency Level: 10
Time taken for tests: 2.255 seconds
Complete requests: 10000
Failed requests: 0
Write errors: 0
Total transferred: 1720000 bytes
HTML transferred: 90000 bytes
Requests per second: 4434.83 [#/sec] (mean) #nginx每秒处理的请求数提高到4434个
Time per request: 2.255 [ms] (mean)
Time per request: 0.225 [ms] (mean, across all concurrent requests)
Transfer rate: 744.91 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 0 0 0.1 0 1
Processing: 1 2 0.8 2 9
Waiting: 1 2 0.7 2 9
Total: 1 2 0.8 2 9
Percentage of the requests served within a certain time (ms)
50% 2
66% 2
75% 2
80% 3
90% 3
95% 4
98% 4
99% 5
100% 9 (longest request)
6. 阶段小结
CPU使用率是最直观和最常用的系统性能指标,更是我们在排查性能问题时,通常会关注的第一个指标。所以我们更要熟悉它的含义,尤其要弄清楚用户(%user),Nice(%nice),系统(%system),等待I/O(%iowait),中断(%irq)以及软中断(%softirq)这几种不同CPU使用率。
- 用户CPU和Nice CPU高,说明用户态进程占用了较多的CPU,所以应该着重排查进程的性能问题。
- 系统CPU高,说明内核态占用了较多的CPU,所以应该着重排查内核线程或者系统调用的性能问题
- I/O等待CPU高,说明等待I/O的时间比较长,所以应该着重排查系统存储是不是出现了I/O问题。
- 软中断和硬中断高,说明软中断或硬中断的处理程序占用了较多的CPU,所以应该着重排查内核中的中断服务程序。
碰到CPU使用率升高的问题,可以借助top,pidstat等工具,确认引发CPU性能问题的来源;
再使用perf等工具,排查出引起性能问题的具体函数。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号