如何理解CPU上下文切换(二)
如何理解CPU上下文切换(二)
1.引
你们好,可爱的小伙伴们。_
多个进程竞争CPU就是一个经常被我们忽视的问题。
你们一定很好奇,进程在竞争CPU的时候并没有真正运行,为什么还会导致系统的负载升高呢?其实CPU上下文切换就是罪魁祸首。
我们都知道,Linux是一个多任务操作系统,它支持远大于CPU数量的任务同时运行。当然,这些任务实际上并不是真的在同时运行,而是因为系统在很短的时间内,将CPU轮流分配给它们,造成多任务同时运行的错觉。
而在每个任务运行前,CPU都需要知道任务从哪里加载,又从哪里开始运行,也就是说,需要系统事先帮它设置好CPU寄存器和程序计数器(Program Counter,PC)
CPU寄存器,是CPU内置的容量小,但速度极快的内存。而程序计数器,则是用来存储CPU正在执行的指令位置,或者即将执行的下一条指令位置。他们都是CPU在运行任何任务前,必须的依赖环境,因此也被叫做CPU上下文。
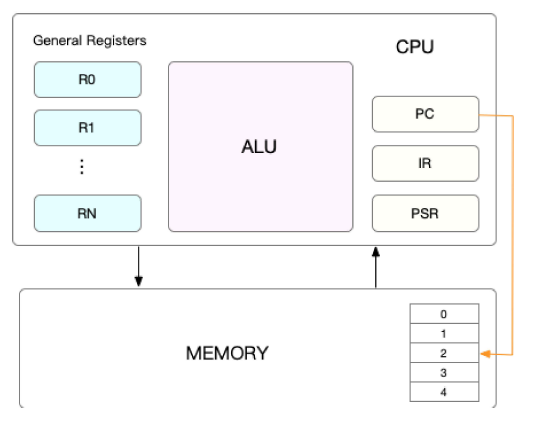
知道了什么是CPU上下文,也很容易理解CPU上下文切换。CPU上下文切换,就是先把前一个任务的CPU上下文(也就是CPU寄存器和程序计数器)保存起来,然后加载新任务的上下文到这些寄存器和程序计数器,最后再跳转到程序计数器所指的新位置,运行新任务。
而这些保存下来的上下文,会存储在系统内核中,并在任务重新调度执行时再次加载进来。这样就能保证任务原来的状态不受影响,让任务看起来还是连续运行。
我猜肯定会有人说,CPU上下文切换无非就是更新了CPU寄存器的值嘛,但这些寄存器,本身就是为了快速运行任务而设计的,为什么会影响系统的CPU性能呢?
在回答这个问题前,你有没有想过,操作系统管理的这些“任务”到底是什么呢?
也许你会说,任务就是进程,或者说任务就是线程。是的,进程和线程正是最常见的任务。但是除此之外,还有没有其他的任务呢?
不要忘了,硬件通过触发信号,会导致中断处理程序的调用,也是一种常见的任务。
所以,根据任务的不同,CPU的上下文切换就可以分为几个不同的场景,也就是进程上下文切换,线程上下文切换以及中断上下文切换。
2.CPU的上下文切换
2.1 系统调用(特权模式切换)
Linux按照特权等级,把进程的运行空间分为内核空间和用户空间,分别对应下图中的,CPU特权等级的Ring 0 和Ring 3.
- 内核空间(Ring 0):具有最高权限,可以直接访问所有资源
- 用户空间(Ring 3):只能访问受限资源,不能直接访问内存等硬件设备,必须通过系统调用陷入到内核中,才能访问这些特权资源。
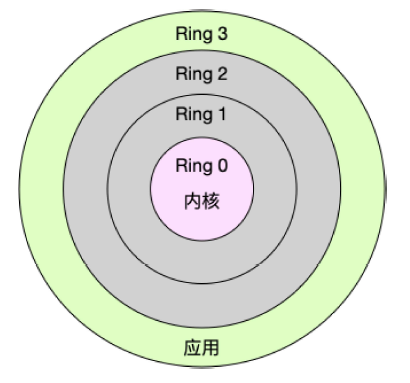
换个角度看,也就是说,进程既可以在用户空间运行,又可以在内核空间中运行。进程在用户空间运行时,被称为进程的用户态,而陷入内核空间的时候,被称为进程的内核态。
从用户态到内核态的转变,需要通过系统调用来完成。比如,当我们查看文件内容时,就需要多次系统调用来完成:首先调用open()打开文件,然后调用read()读取文件内容,并调用write()将内容写到标准输出,最后再调用close()关闭文件。
那么,系统调用的过程有没有发生CPU上下文的切换呢?答案自然是肯定的。
CPU寄存器里原来用户态的指令位置,需要先保存起来。接着,为了执行内核态代码,CPU寄存器需要更新为内核态指令的新位置。最后才是跳转到内核态运行内核任务。
而系统调用结束后,CPU寄存器需要恢复原来保存的用户态,然后再切换到用户空间,继续运行进程。所以,一次系统调用的过程,其实发生了两次CPU上下文切换。
- 进程上下文切换,是指从一个进程切换到另一个进程运行。
- 而系统调用过程中一直是同一个进程在运行。
因此,系统调用的过程通常称为特权模式切换,而不是上下文切换。但实际上,系统调用过程中,CPU的上下文切换还是无法避免的。
2.2 进程的上下文切换
进程的上下文切换和系统调用到底有什么区别呢?
首先,我们需要知道,进程是由内核来管理和调度的,进程的切换只能发生在内核态。所以,进程的上下文不仅包含了虚拟内存,栈,全局变量等用户空间的资源,还包括了内核堆栈,寄存器等内核空间的状态。
因此,进程的上下文切换就比系统调用时多了一步:在保存当前进程的内核状态和CPU寄存器之前,需要先把该进程的虚拟内存,栈等保存下来;而加载了下一进程的内核态后,还需要刷新进程的虚拟内存和用户栈。
如下图所示,保存上下文和恢复上下文的过程并不是“免费”的,需要内核在CPU上运行才能完成。
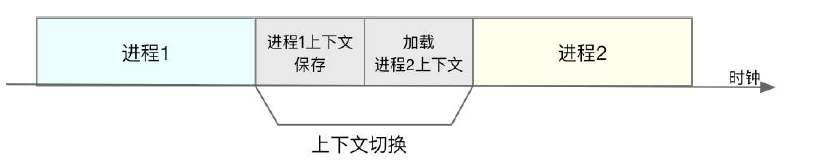
根据Tsuna的测试报告,每次上下文切换都需要几十纳秒到数微秒的CPU时间。这个时间还是相当可观的,特别是在进程上下文切换次数较多的情况下,很容易导致CPU将大量时间消耗在寄存器,内核栈以及虚拟内存等资源的保存和恢复上,进而大大缩短了真正运行进程的时间。这也正是上一节中我们所讲的,导致平均负载升高的一个重要因素。
另外,我们知道,Linux通过TLB(Translation Lookaside Buffer)来管理虚拟内存到物理内存的映射关系。当虚拟内存更新后,TLB也需要刷新,内存的访问也会随之变慢。特别是在多处理器系统上,缓存是被多个处理器共享的,刷新缓存不仅会影响当前处理器的进程,还会影响共享缓存的其他处理器的进程。
知道了进程上下文切换潜在的性能问题后,我们再来看,究竟什么时候会切换进程上下文。
显然,进程切换时才需要切换上下文,换句话说,只有在进程调度的时候,才需要切换上下文。Linux为每个CPU都维护了一个就绪队列,将活跃进程(即正在运行和正在等待CPU的进程)按照优先级和等待CPU的时间排序,然后选择最需要CPU的进程,也就是优先级最高和等待CPU时间最长的进程来运行。
2.3 进程的调度规则
进程在什么时候才会被调度到CPU上运行呢?
最容易想到的一个时机,就是进程执行完终止了,它之前使用的CPU会释放出来,这个时候再从就绪队列里,拿一个新的进程过来运行。
其实,还有很多其他场景,也会触发进程调度,在这里我们梳理一下
- 为了保证所有进程可以得到公平调度,CPU时间被划分为一段段的时间片,这些时间片再被轮流分配给各个进程。这样,当某个进程的时间片耗尽了,就会被系统挂起,切换到其它正在等待CPU的进程上运行。
- 进程在系统资源不足(比如内存不足)时,要等到资源满足后才可以运行,这个时候进程也会被挂起,并由系统调度其他进程运行。
- 当进程通过睡眠函数sleep这样的方法将自己主动挂起时,自然也会重新调度。
- 当有优先级更高的进程运行时,为了保证高优先级进程的运行,当前进程会被挂起,由高优先级进程来运行。
- 当发生硬件中断时,CPU上的进程会被中断挂起,转而执行内核中的中断服务程序。
2.4 线程的上下文切换
线程和进程最大的区别在于,线程是调度的基本单位,而进程则是资源拥有的基本单元。说白了,所谓内核中的任务调度,实际上的调度对象是线程;而进程只是给线程提供了虚拟内存,全局变量等资源。所以,对于线程和进程,我们也可以这么理解:
- 当进程只有一个线程时,可以认为进程就等于线程
- 当进程拥有多个线程时,这些线程会共享相同的虚拟内存和全局变量等资源。这些资源在上下文切换时是不需要修改的。
- 另外,线程也有自己的私有数据,比如栈和寄存器等,这些在上下文切换时也是需要保存的。
这样一来,线程的上下文切换其实就可以分为两种情况:
- 第一种:前后两个线程属于不同进程。此时,因为资源不共享,所以切换过程就跟进程上下文切换是一样的。
- 第二种,前后两个线程属于同一个进程。此时,因为虚拟内存是共享的,所以在切换时,虚拟内存这些资源就保持不动,只需要切换线程的私有数据,寄存器等不共享的数据。
虽然同为上下文切换,但同一个进程内的线程切换,要比多进程间的切换消耗更少的资源,而这,也正是多线程代替多进程的一个优势。
2.5 中断上下文切换
除了之前提到的两种上下文切换,还有一个场景也会切换CPU上下文,那就是中断.
为了快速响应硬件的事件,中断处理会打断进程的正常调度和执行,转而调用中断处理程序,响应设备事件。而在打断其他进程时,就需要将进程当前的状态保存下来,这样在中断结束后,进程仍然可以从原来的状态恢复运行。
跟进程上下文不同,中断上下文切换并不涉及到进程的用户态。所以,即便中断过程打断了一个正处在用户态的进程,也不需要保存和恢复这个进程的虚拟内存,全局变量等用户态资源。中断上下文,其实只包括内核态中断服务程序执行所必须的状态,包括CPU寄存器,内核堆栈,硬件中断参数等。
对同一个CPU来说,中断处理比进程拥有更高的优先级,所以中断上下文切换并不会与进程上下文切换同时发生。同样道理,由于中断会打断正常进程的调度和执行,所以大部分中断处理程序都短小精悍,以便尽可能快的执行结束。
另外,跟进程上下文切换一样,中断上下文切换也需要消耗CPU,切换次数过多也会耗费大量的CPU,甚至严重降低系统的整体性能。所以,当你发现中断次数过多时,就需要注意去排查它是否会给你的系统带来严重的性能问题。
3.阶段小结
- CPU上下文切换,是保证Linux系统正常工作的核心功能之一,一般情况下不需要我们特别关注。
- 但过多的上下文切换,会把CPU时间消耗在寄存器,内核栈以及虚拟内存等数据的保存和恢复上,从而缩短进程真正运行的时间,导致系统的整体性能大幅下降。
4.如何查看系统的上下文切换情况?
通过之前的学习我们知道,过多的上下文切换,会把CPU时间消耗在寄存器,内核栈以及虚拟内存等数据的保存和恢复上,缩短进程真正运行的时间,成了系统性能大幅下降的一个元凶。
既然上下文切换对系统性能影响那么大,你肯定迫不及待想知道,到底要怎么查看上下文切换呢?在这里,我们可以使用vmstat这个工具,来查询系统的上下文切换情况。
vmstat是一个常用的系统性能分析工具,主要用来分析系统的内存使用情况,也常用来分析CPU上下文切换和中断的次数。
比如,下面就是一个vmstat的使用示例:
#每隔5秒输出1组数据
[root@localhost ~]# vmstat 5
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
2 0 0 6124344 4196 1710304 0 0 8 16555 572 881 35 3 61 2 0
0 0 0 6124320 4196 1710304 0 0 0 0 50 46 0 0 100 0 0
0 0 0 6124320 4196 1710304 0 0 0 0 46 42 0 0 100 0 0
我们一起来看这个结果,你可以先试着自己解读每列的含义。在这里,我重点强调下,需要特别关注的四列内容:
- cs (context switch):每秒上下文切换的次数
- in(interrupt):每秒中断的次数
- r(Running or Runnable):就绪队列的长度,也就是正在运行和等待CPU的进程数
- b(Blocked):处于不可中断睡眠状态的进程数
可以看到,这个例子中的上下文切换次数cs是881次,而系统中断次数in则是25次,而就绪队列长度r是2,不可中断状态进程数b则是0.
vmstat只给出了系统总体的上下文切换情况,要想查看每个进程的详细情况,就需要使用我们前面提到过的pidstat了。给它加上-w选项,你就可以查看每个进程上下文切换的情况了。
例如。。。
[root@localhost ~]# pidstat -w 5
Linux 3.10.0-862.3.3.el7.x86_64 (localhost.localdomain) 2019年07月25日 _x86_64_ (2 CPU)
21时27分41秒 UID PID cswch/s nvcswch/s Command
21时27分46秒 0 1 0.20 0.00 systemd
21时27分46秒 0 3 0.20 0.00 ksoftirqd/0
21时27分46秒 0 9 1.60 0.00 rcu_sched
21时27分46秒 0 11 0.20 0.00 watchdog/0
21时27分46秒 0 12 0.20 0.00 watchdog/1
21时27分46秒 0 476 0.20 0.00 systemd-journal
21时27分46秒 0 15463 10.58 0.00 vmtoolsd
21时27分46秒 0 61220 1.40 0.00 kworker/0:0
21时27分46秒 0 61262 1.00 0.00 kworker/u256:0
21时27分46秒 0 61502 0.20 0.00 sshd
这个结果中,有两列内容是我们的重点关注对象。一个是cswch,表示每秒自愿上下文切换(voluntary context switches)的次数,另一个则是nvcswch,表示每秒非自愿上下文切换(non voluntary context switches)的次数。
这两个概念你一定要牢牢记住,因为它们意味着不同的性能问题:
- 所谓自愿上下文切换,是指进程无法获取所需资源,导致的上下文切换。比如说,I/O,内存等系统资源不足时,就会发生自愿上下文切换。
- 而非自愿上下文切换,则是指进程由于时间片已到等原因,被系统强制调度,进而发生的上下文切换。比如说,大量进程都在争抢CPU时,就容易发生非自愿上下文切换。
5.案例分析
知道了怎么查看这些指标,终极问题就来了,那就是上下文切换频率是多少次才算正常呢?别急着要答案,同样的,我们先来看一个上下文切换的案例。通过案例实战演练,你自己就可以分析并找出这个标准了。
5.1 环境准备
这次,我们需要使用sysbench来模拟系统多线程调度切换的情况。
sysbench:
- sysbench是一个多线程的基准测试工具,一般用来评估不同系统参数下的数据库负载情况。
- 当然,在这次案例中,我们只把它当成一个异常进程来看,作用是模拟上下文切换过多的问题。
- 机器配置:2CPU,8GB内存
- 预先安装sysbench和sysstat包
[root@localhost ~]# cat /etc/redhat-release
CentOS Linux release 7.6.1810 (Core)
[root@localhost ~]# uname -r
3.10.0-862.3.3.el7.x86_64
[root@localhost ~]# yum -y install sysbench sysstat
安装完成后,我们先用vmstat看一下空闲系统的上下文切换次数:
[root@localhost ~]# vmstat 1 1
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
1 0 0 6113420 4212 1721516 0 0 5 10063 357 544 21 2 76 1 0
在这里,我们看到,目前系统的上下文切换次数cs是544,而中断次数in是357,r是1,b是0
这会儿我并没有运行其他任务,所以他们就是空闲系统的上下文切换次数。
5.2 上下文切换操作分析
我们需要开三个终端进行操作
第一个终端里运行sysbench,模拟系统多线程调度的瓶颈
#以10个线程运行5分钟的基准测试,模拟多线程切换的问题
[root@localhost ~]# sysbench --threads=10 --max-time=300 threads run
第二个终端里运行vmstat,观察上下文切换情况
#每隔1秒输出1组数据
[root@localhost ~]# vmstat 1
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
9 0 0 7634332 2124 214648 0 0 221 43 3413 38973 4 15 81 0 0
6 0 0 7634324 2124 214672 0 0 0 0 41931 1987190 13 83 4 0 0
5 0 0 7634324 2124 214672 0 0 0 0 47298 1921415 13 84 3 0 0
8 0 0 7634324 2124 214672 0 0 0 0 43138 1995670 13 82 5 0 0
5 0 0 7634324 2124 214672 0 0 0 0 39985 2003544 12 84 4 0 0
9 0 0 7634324 2124 214672 0 0 0 0 43128 1948219 12 85 3 0 0
8 0 0 7634324 2124 214672 0 0 0 0 41523 1996370 12 83 5 0 0
5 0 0 7634324 2124 214672 0 0 0 0 41408 1986546 13 84 3 0 0
6 0 0 7634324 2124 214672 0 0 0 0 44835 1963354 14 83 3 0 0
5 0 0 7634324 2124 214672 0 0 0 0 40687 1962756 13 84 4 0 0
8 0 0 7634324 2124 214672 0 0 0 0 44554 1962270 11 86 3 0 0
在这里应该可以发现,cs列的上下文切换从544骤然上升到了190多万。同时,注意观察其他几个指标:
- r列:就绪队列的长度已经到了9,远远超过了系统CPU的个数2,所以肯定会有大量的CPU竞争。
- us(user)和sy(system)列:这两列的CPU使用率加起来上升到了趋近于100%,其中系统CPU使用率,也就是sy列高达84%,说明CPU主要是被内核占用了。
- in列:中断次数也上升到了4万左右,说明中断处理也是个潜在的问题。
综合这几个指标,我们可以知道,系统的就绪队列过长,也就是正在运行和等待CPU的进程数过多,导致了大量的上下文切换,而上下文切换又导致了系统CPU的占用率升高。
那么,到底是什么进程导致了这些问题呢?
我们继续打开第三个终端进行分析,通过pidstat来看一下,CPU和进程上下文切换的情况:
# 每隔1秒输出1组数据
# -w 参数表示输出进程切换指标,而-u参数则表示输出CPU使用指标
[root@localhost ~]# pidstat -w -u 1
Linux 3.10.0-957.21.3.el7.x86_64 (localhost.localdomain) 2019年07月30日 _x86_64_ (2 CPU)
20时13分56秒 UID PID %usr %system %guest %wait %CPU CPU Command
20时13分57秒 0 10986 26.73 167.33 0.00 0.00 194.06 0 sysbench
20时13分57秒 0 10997 0.00 0.99 0.00 0.00 0.99 0 pidstat
20时13分56秒 UID PID cswch/s nvcswch/s Command
20时13分57秒 0 3 0.99 0.00 ksoftirqd/0
20时13分57秒 0 9 8.91 0.00 rcu_sched
20时13分57秒 0 30 2.97 0.00 kworker/0:1
20时13分57秒 0 37 0.99 0.00 khugepaged
20时13分57秒 0 47 0.99 0.00 kworker/u256:1
20时13分57秒 0 276 0.99 0.00 kworker/1:2
20时13分57秒 0 893 0.99 0.00 irqbalance
20时13分57秒 0 894 9.90 0.00 vmtoolsd
20时13分57秒 0 978 0.99 0.00 kworker/0:1H
20时13分57秒 0 10997 0.99 0.00 pidstat
从pidstat的输出我们可以发现,CPU使用率的升高果然是sysbench导致的,它的CPU使用率已经达到了194%。但上下文切换则是来自其他进程,例如vmtoolsd和rcu_sched。
不过,有个奇怪的事情:我们发现以上数据输出的cswch/s(自愿上下文切换)的总数一共也没有几个,那么之前vmstat怎么会显示190多万次上下文切换呢?难道工具本身有问题吗?
在这里,我们先回想一下Linux调度的基本单位实际上是线程,而我们的场景sysbench模拟的也是线程的调度问题,那么,是不是忽略了线程的数据呢?
通过运行man pidstat,我们会发现,pidstat默认显示进程的指标数据,加上-t参数后,才会输出线程的指标。
因此,我们可以在第三个终端里,Ctrl+C停止刚才的pidstat命令,再加上-t参数,重试一下看看:
# 每隔1秒输出一组数据
# -wt 参数表示输出线程的上下文切换指标
[root@localhost ~]# pidstat -wt 1
Linux 3.10.0-957.21.3.el7.x86_64 (localhost.localdomain) 2019年07月30日 _x86_64_ (2 CPU)
20时31分49秒 UID TGID TID cswch/s nvcswch/s Command
20时31分50秒 0 3 - 1.96 0.00 ksoftirqd/0
20时31分50秒 0 - 3 1.96 0.00 |__ksoftirqd/0
20时31分50秒 0 9 - 8.82 0.00 rcu_sched
20时31分50秒 0 - 2649 0.98 0.00 |__tuned
20时31分50秒 0 - 1181 0.98 0.00 |__in:imjournal
20时31分50秒 0 11177 - 0.98 0.00 kworker/0:3
20时31分50秒 0 - 11177 0.98 0.00 |__kworker/0:3
20时31分50秒 0 - 11208 25707.84 143927.45 |__sysbench
20时31分50秒 0 - 11209 22346.08 172766.67 |__sysbench
20时31分50秒 0 - 11210 24196.08 146108.82 |__sysbench
20时31分50秒 0 - 11211 21345.10 159336.27 |__sysbench
20时31分50秒 0 - 11212 22296.08 165614.71 |__sysbench
20时31分50秒 0 - 11213 22575.49 149888.24 |__sysbench
20时31分50秒 0 - 11214 26113.73 160592.16 |__sysbench
20时31分50秒 0 - 11215 23901.96 172510.78 |__sysbench
20时31分50秒 0 - 11216 28253.92 137909.80 |__sysbench
20时31分50秒 0 - 11217 25075.49 164235.29 |__sysbench
20时31分50秒 0 11219 - 0.98 0.98 pidstat
20时31分50秒 0 - 11219 0.98 0.98 |__pidstat
现在,你就能看到了,虽然sysbench进程(也就是主线程)的上下文切换次数看起来并不多,但它的子线程的上下文切换次数却有很多。看来,上下文切换罪魁祸首,还是过多的sysbench线程。
5.3 中断操作分析
在之前我们已经找到了上下文切换次数增多的根源,那是不是到这里就可以结束了呢?
当然不是。前面在观察系统指标时,除了上下文切换频率骤然升高,还有一个指标也有很大的变化。是的,正是中断次数。中断次数也上升到了4万多。但到底是什么类型的中断上升了,现在还不清楚。我们接下来继续抽丝剥茧寻找源头。
既然是中断,我们知道它只发生在内核态,而pidstat只是一个进程的性能分析工具,并不能提供任何关于中断的详细信息,怎样才能知道中断发生的类型呢?
是的,那就必须从/proc/interrupts这个只读文件中读取。/proc实际上是Linux的一个虚拟文件系统,用于内核空间与用户空间之间的通信。/proc/interrupts就是这种通信机制的一部分,提供了一个只读的中断使用情况。
我们现在还是在第三个终端里,Ctrl+C停止刚才的pidstat命令,然后运行下面的命令,观察中断的变化情况:
# -d 参数表示高亮显示变化区域
[root@localhost ~]# watch -d grep "RES" /proc/interrupts
RES: 21124648 21432646 Rescheduling interrupts
观察一段时间,你就可以发现,变化速度最快的是重调度中断(RES),这个中断类型表示,唤醒空闲状态的CPU来调度新的任务运行。这是多处理器系统(SMP)中,调度器用来分散任务到不同CPU的机制,通常也被称为处理器间中断(Inter-Processor Interrupts,IPI)
所以,这里的中断升高还是因为过多任务的调度问题,跟前面上下文切换次数的分析结果是一致的。
5.4 测试分析总结
通过这个案例,咱们应该发现使用多工具,多方面指标对比观测的好处。如果最开始时,我们只用了pidstat观测,这些很严重的上下文切换线程,压根儿就发现不了。
那么,每秒上下文切换多少次才算得上正常呢?
这个数值总体来说取决于系统本身的CPU性能。
在我看来,如果系统的上下文切换次数比较稳定,那么从数百到一万以内,都应该算得上正常。但是,当上下文切换次数超过一万次,或者切换次数出现数量级的增长时,就很可能已经出现了性能问题。
在这种情况下,我们还需要根据上下文切换的类型,再做具体分析。比如说:
- 自愿上下文切换变多了,说明进程都在等待资源,有可能发生了I/O等其他问题;
- 非自愿上下文切换变多了,说明进程都在被强制调度,也就是都在争抢CPU,说明CPU的确成了瓶颈。
- 中断次数变多了,说明CPU被中断处理程序占用,还需要通过查看/proc/interrupts文件来分析具体的中断类型。
6.阶段小结
本次,我们通过一个sysbench的案例,给同学们讲解了上下文切换问题的分析思路。碰到上下文切换次数过多的问题时,我们可以借助vmstat,pidstat和/proc/interrupts等工具,来辅助排查性能问题的根源。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号