
(Python第六天)文件处理
一、文件操作
通常我们把文件分为两类,文本文件和二进制文件。
1)文件打开
使用open()函数打开文件,需要两个参数,第一个参数是文件路径或者文件名,第二个是文件的打开模式
'r' 以只读模式打开,只读取文件不可编辑删除文件的任何内容
'w' 以写入模式打开,文件存在将会删除里面的所有内容,然后打开这个文件进行写入
'a' 以追加模式打开,写入到文件中的任何数据将自动添加到末尾
默认模式为只读模式
打开一个文件,实例:在windows下打开一个文件,必须使用绝对路径,如:
>>>fobj = open ("G:\PythonStudy\sample.txt")
>>> fobj
2)文件关闭
只要打开一个文件,就必须关闭一个文件,则使用方法close()完成这个操作
>>>fobj.close()
始终确保你显式关闭每个打开的文件,一旦工作完成没有任何理由保持打开文件,因为程序能打开的文件数量是有上限的,如果超过这个限制,没有任何可靠的方法回复,所以程序可能会崩溃。
3)文件读取
使用read()一次性读取整个文件
read(size)有一个可选的参数size,用于指定字符串长度,如果没有指定size或者指定为负数,都会读取并返回整个文件,如果文件大小为当前机器内存的两倍时,就会产生问题
readlines()方法可以读取所有行到一个列表中,而readline()每次读取文件的一行,实例:循环遍历文件对象来读取文件中的每一行
>>>fobj = open('sample.txt')
>>> for x in fobj:
print(x,end = ' ')
实验:接受用户输入的字符串作为将要读取的文件的文件名,并在屏幕上打印文件内容
1 name = input("Enter the file name:") 2 fobj = open (name) 3 print(fobj.read()) 4 fobj.close()
4)文件写入
通过write()打开一个文件然后我们随便写入一些文本
二、文件操作实例程序
1)拷贝文件
拷贝给定的文本文件到另一个给定的文本文件
ps:模块sys.模块sys.argv包含所有命令行参数,获取程序外部向程序传递的参数,传递给Python脚本的命令行参数列表,argv[0]是脚本名称,如果使用-c解释器的命令行选项执行命令,argv[0]则将其设置为字符串‘-c’,如果没有脚本名称传递给Pyhton解释器,argv[0]为空字符串。
sys.exit({arg})程序中间的退出,当arg=0为正常退出,其他数值(1-127)为不正常,可抛异常事件供捕获。
关于sys详细参数功能,参考:https://blog.csdn.net/qq_38526635/article/details/81739321
这个程序的功能完全可以使用shell的cp命令替代,在cp后首先输入被拷贝的文件的文件名,然后输入新文件名
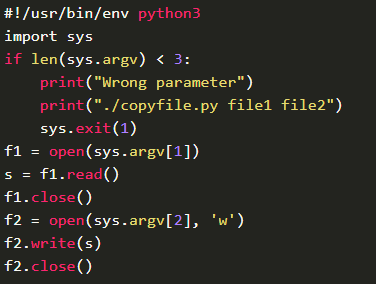
提供sys模块功能,先判断命令行是否有两个文件,argv[0]代表着这个命令本身的名字,argv[1]是准备复制的文本文件的名字,argv[2]是复制过新的文本文件的名字,如果少于,则不正常退出命令行,反之,进行打开第一个文件,读出里面的内容给s,然后以w的方式打开一个新的文本文件,把s的内容输入到新的文本文件中去。
2)文本文件相关信息统计
对任意给定文本文件中的制表符、行、空格进行计数
ps:
1) enumerate(iterableobject),在序列中循环时,索引位置和对应值可以使用它同时得到,组合为一个索引序列,同时列出数据和下标,语法是enumerate(sequence,[start=0])
>>>seasons = ['Spring', 'Summer', 'Fall', 'Winter'] >>> list(enumerate(seasons)) [(0, 'Spring'), (1, 'Summer'), (2, 'Fall'), (3, 'Winter')] >>> list(enumerate(seasons, start=1)) # 下标从 1 开始 [(1, 'Spring'), (2, 'Summer'), (3, 'Fall'), (4, 'Winter')]
2) count()方法,查看某对象中所包含相同元素的数量,使用Python列表内置的count()方法可以统计某个元素在列表中出现的次数。
比如,在列表列表['a','iplaypython.com','c','b‘,'a'],想统计字符串'a'在列表中出现的次数,可以
>>> ['a','iplaypython.com','c','b','a'].count('a')
2
其返回值就是要统计参数出现的次数,在应用的时候就是把列表赋给一个变量,之后再用count()方法操作,
3)OS模块就是对操作系统进行操作,使用该模块必须先导入模块
getcwd()就是获得当前工作目录,默认为当前文件所在的文件夹
chdir()改变当前工作目录
还有一些在os.path子模块中的内容:
exists()检测某个路径是否真实存在,如:
filepath = '/home/...' result = os.path.exists(filepath) print(result)
给任意的给定文本文件进行计数,代码为:
1 import os 2 import sys 3 4 5 def parse_file(path): 6 """ 7 分析给定文本文件,返回其空格、制表符、行的相关信息 8 9 :arg path: 要分析的文本文件的路径 10 11 :return: 包含空格数、制表符数、行数的元组 12 """ 13 fd = open(path) 14 i = 0 15 spaces = 0 16 tabs = 0 17 for i,line in enumerate(fd): 18 spaces += line.count(' ') 19 tabs += line.count('\t') 20 # 现在关闭打开的文件 21 fd.close() 22 23 # 以元组形式返回结果 24 return spaces, tabs, i + 1 25 26 def main(path): 27 """ 28 函数用于打印文件分析结果 29 30 :arg path: 要分析的文本文件的路径 31 :return: 若文件存在则为 True,否则 False 32 """ 33 if os.path.exists(path): 34 spaces, tabs, lines = parse_file(path) 35 print("Spaces {}. tabs {}. lines {}".format(spaces, tabs, lines)) 36 return True 37 else: 38 return False 39 40 41 if __name__ == '__main__': 42 if len(sys.argv) > 1: 43 main(sys.argv[1]) 44 else: 45 sys.exit(-1) 46 sys.exit(0)
即:先判断是否是直接运行,还是导入,再判断运行的命令是否正确,用过main自定义函数来处理命令中的文本文件,否则返回错误退出。main()函数就是判断这个路径是否存在,存在则通过parse_file函数处理,打印出空格,制表符和行数。parse_file函数就是打开这个文本文件,通过enumrate方法统计出这个文本文件的这几个符号的次数、
三、使用with语句
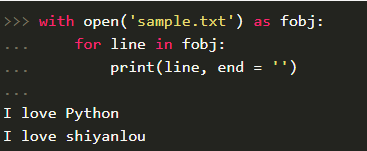
通过with语句处理文件对象,它会在文件用完后自动关闭,就算发生异常也没有关系。
四、实现lscpu
在Linux下使用lscpu命令来查看cpu当前信息,实际上是通过lscpu命令读取/proc/cpuinfo这个文件的信息并美化输出,
试验:在Windows下读取一个文件‘c:\\test.txt’,统计出该文件中出现的字符'a'的次数
1 import os 2 3 b=0 4 5 def get_number_of_char(filePath, c): 6 global b 7 if os.path.exists(filePath): 8 with open(filePath) as fp: 9 for line in fp: 10 n = line.count(c) #就是一行一行的统计出每一行的字符a的次数赋值给b,让b成为全局变量,在main方法中打印出b 11 b+=n 12 else: 13 print('the path:[{}] is not exist!'.format(filePath)) 14 15 def main(): 16 file_path = 'G:\\PythonStudy\\sample.txt' 17 get_number_of_char(file_path, 'a') 18 print(b) 19 20 if __name__ == '__main__': 21 main()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号