Beautifulsoup提取特定丁香园帖子回复
DataWhale-Task3(Beautifulsoup爬取丁香园)
简要分析
任务3:爬取丁香园论坛特定帖子,包括帖子主题,帖子介绍,回贴内容(用户名,用户头像,用户所在城市,用户回贴内容)
此次爬取的url:http://i.dxy.cn/topic/admerahealthcollege
其加载帖子内容的接口:http://i.dxy.cn/topic/admerahealthcollege/feeds/list

其数据接口仅在于路径不同,host是相同的,在帖子url补上/feeds/list
数据接口共有三个GET参数:JUTE_TOKEN,type,page,size
| 参数 | 说明 |
|---|---|
| JSTE_TOKE | 是第一次请求服务器响应的 cookies 之一 |
| type | 默认为 0 |
| page | 评论的页码 |
| size | 每次请求多少条评论 |
代码函数功能
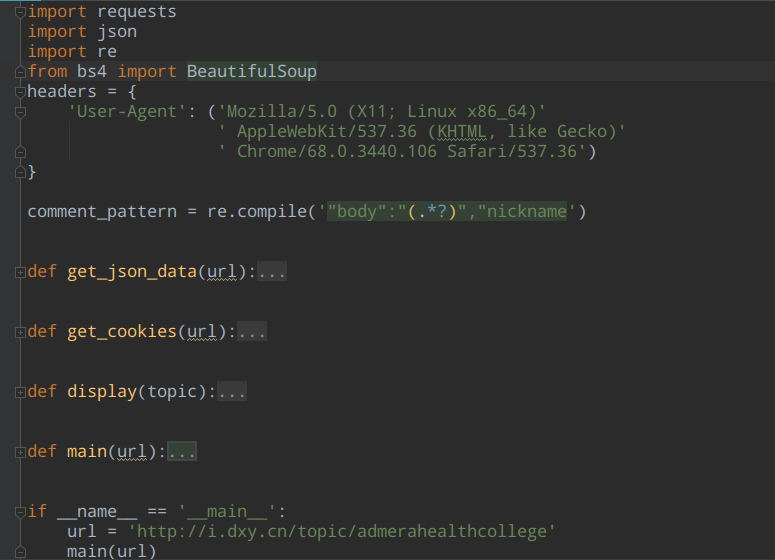
get_json_data:获取评论的数据(用户名,用户头像地址,用户所在城市,评论内容)get_cookies:获取cookies,以备设置JUTE_TOKEN参数值display: 显示提取的最终数据main:主模块,负责调用以上三个函数
完整代码
import requests
import json
import re
from bs4 import BeautifulSoup
"""
爬取: http://i.dxy.cn/topic/admerahealthcollege
爬取丁香园:丁香园是用 js 接口加载信息的,即直接请求上面的网址
得到的只是一个模板文件
通过浏览器开发者工具可以看到其加载信息的接口为
http://i.dxy.cn/topic/admerahealthcollege/feeds/list?JUTE_TOKEN=f79d77be-f161-4b2a-bc87-b20271b018ba&type=0&page=1&size=20
可以发现的是有三个请求参数 JSTE_TOKEN type page size
url: http://i.dxy.cn/topic/admerahealthcollege/feeds/list
JSTE_TOKE 是第一次请求服务器响应的 cookies 之一
type 默认为 0
page 评论的页码
size 每次请求多少条评论
"""
headers = {
'User-Agent': ('Mozilla/5.0 (X11; Linux x86_64)'
' AppleWebKit/537.36 (KHTML, like Gecko)'
' Chrome/68.0.3440.106 Safari/537.36')
}
comment_pattern = re.compile('"body":"(.*?)","nickname')
def get_json_data(url):
"""
:param url: api
:return: comment dict
comment
nickname 作键值
avator 头像 url 地址
body 评论内容
city 用户省份
"""
comment = []
tarage_index = 1
while True:
target_url = url.format(tarage_index)
resp = requests.get(target_url, headers=headers)
resp_dict = json.loads(resp.content.decode("utf-8"))
if len(resp_dict['items']) == 0:
break
for item in resp_dict['items']:
body = re.search(comment_pattern, item['content']).group(1)
comment.append({item['nickname']: {'avator': item['infoAvatar'], 'body': body, 'city': item['city']}})
tarage_index += 1
return comment
def get_cookies(url):
# 获取 cookies
resp = requests.get(url, headers=headers)
for k, v in resp.cookies.items():
headers[k] = v
resp.encoding = 'utf-8'
return resp.text
def display(topic):
"""
topic: 字典,键值有 topic info comment
topic key 主题名
info key 主题介绍
comment key 相关评论
"""
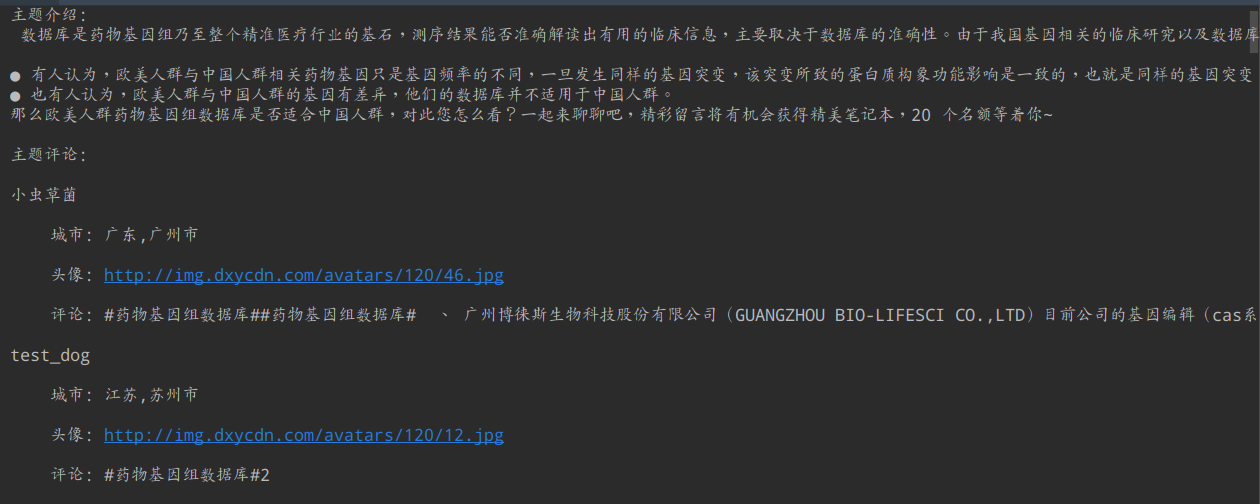
print("主题:\n", topic['topic'])
print("主题介绍:\n", topic['info'])
print("主题评论:\n")
for item in topic['comment']:
for k, v in item.items():
print(k, '\n')
print("\t城市:", v['city'], '\n')
print('\t头像:', v['avator'], '\n')
print('\t评论:', v['body'], '\n')
def main(url):
html = get_cookies(url)
soup = BeautifulSoup(html, 'lxml')
topic = {}
# 设置 json 接口的 host, JUTE_TOKEN, page 先设为占位符
topic['topic'] = soup.select('#topic-con > div.brief > h2 > a')[0].text
topic['info'] = soup.select('#topic-con > div.brief > p')[0].text
js_url = '{}/feeds/list?JUTE_TOKEN={}&type=0&page={}&size=20'.format(url, headers['JUTE_TOKEN'], '{}')
topic['comment'] = get_json_data(js_url)
display(topic)
if __name__ == '__main__':
url = 'http://i.dxy.cn/topic/admerahealthcollege'
main(url)
结果图