python爬虫之天气预报网站--查看最近(15天)的天气信息(正则表达式)
python爬虫之天气预报网站--查看最近(15天)的天气信息(正则表达式)
思路:
1.首先找到一个自己想要查看天气预报的网站,选择自己想查看的地方,查看天气(例:http://www.tianqi.com/xixian1/15/)
2.打开"网页源代码",分析自己想要获取数据的特点
3.运用正则表达式来对数据进行处理,获得自己想要的数据 #网站可能反爬虫,需要绕过,这里用浏览器的代理(python默认的用户代理是自己,需要改成浏览器的用户代理,这样就能绕过一些网站简单的反爬虫)
4.获得数据后,对数据进行简单的美化
5.把数据写入文件(用pickle模块)
2.打开"网页源代码",分析自己想要获取数据的特点(不同网站的数据不同,需要具体问题具体分析)

3.1被网站禁止爬虫效果图如下:

3.2运用正则表达式来对数据进行处理,获得自己想要的数据
代码如下:
查看天气预报
import re
import requests
from prettytable import PrettyTable
url="http://www.tianqi.com/xixian1/15/"
#绕过网站反爬虫
txt=requests.get(url,headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36","Host":"www.tianqi.com"}).text
#print(txt)
s1=re.compile(r'<b>(\d\d月\d\d日)</b>') #日期
print(s1.findall(txt))
s2=re.compile(r'<li class="temp">(.+) (-?\d+)(\W+)<b>(-?\d+)</b>℃</li>')
print(s2.findall(txt))
s3=re.compile('>(.{1,4})</b></li>')
print(s3.findall(txt))
s4=re.compile(r'<li>([\u4e00-\u9fa5].+)</li>')
print(s4.findall(txt))
tianqi=[]
for i in range(len(s1.findall(txt))):
tianqi.append([s1.findall(txt)[i],s2.findall(txt)[i][0],s2.findall(txt)[i][1]+s2.findall(txt)[i][2]+s2.findall(txt)[i][3],s3.findall(txt)[i],s4.findall(txt)[i]])
print(tianqi)
ptable=PrettyTable('日期 天气 气温(℃) 空气质量 风级'.split())
for i in tianqi:
ptable.add_row(i)
print(ptable)
运行效果如下:
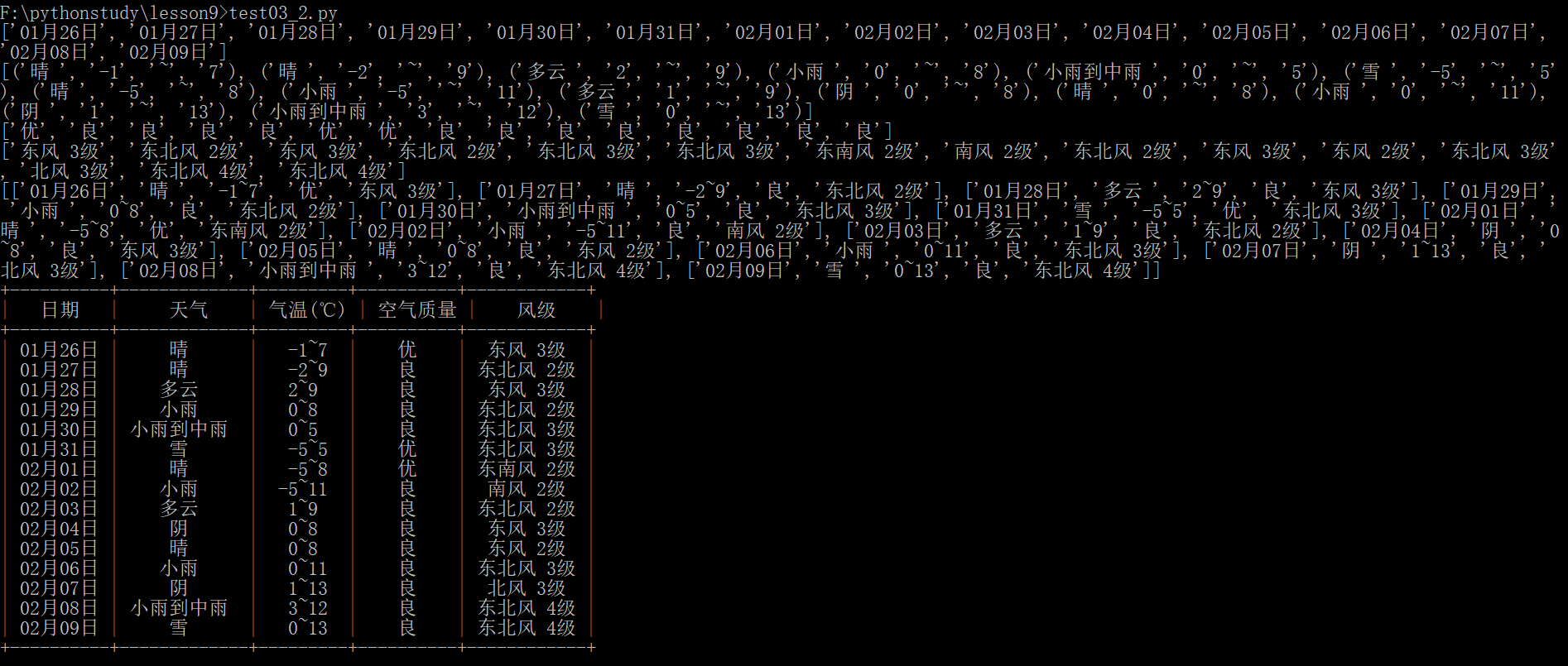
5.把数据写入文件(pickle)
代码如下:
import re
import requests
import pickle
from prettytable import PrettyTable
url="http://www.tianqi.com/xixian1/15/"
#绕过网站反爬虫
#把内容写入到文件中(序列化)
try:
with open("tianqi.txt","rb") as f:
txt=pickle.load(f)
print("结果已加载")
except:
txt=requests.get(url,headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36","Host":"www.tianqi.com"}).text
with open("tianqi.txt","wb") as f:
pickle.dump(txt,f)
print("文件已写入!")
#print(txt)
s1=re.compile(r'<b>(\d\d月\d\d日)</b>') #日期
print(s1.findall(txt))
s2=re.compile(r'<li class="temp">(.+) (-?\d+)(\W+)<b>(-?\d+)</b>℃</li>')
print(s2.findall(txt))
s3=re.compile('>(.{1,4})</b></li>')
print(s3.findall(txt))
s4=re.compile(r'<li>([\u4e00-\u9fa5].+)</li>')
print(s4.findall(txt))
tianqi=[]
for i in range(len(s1.findall(txt))):
tianqi.append([s1.findall(txt)[i],s2.findall(txt)[i][0],s2.findall(txt)[i][1]+s2.findall(txt)[i][2]+s2.findall(txt)[i][3],s3.findall(txt)[i],s4.findall(txt)[i]])
print(tianqi)
ptable=PrettyTable('日期 天气 气温(℃) 空气质量 风级'.split())
for i in tianqi:
ptable.add_row(i)
print(ptable)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号