

随着网页越做越复杂,页面上要用到的 JavaScript 也越来越多,一次性把所有可能会用到的 js 全包含在页面中显然不是一个好主意,于是各种各样动态按需加载 js 的方法逐渐流行起来,LABjs 就是这样一个有趣的项目,目前,包括 twitter 在内的很多网站都是 LABjs 的用户。下面将对 LABjs 1.0.4 版的实现原理做一些分析。
限于篇幅,关于 LABjs 的使用说明这儿就不写了,需要的话请看它的官方文档。
所谓动态加载 js ,指的是在页面上的某一些 js 执行时,由这些 js 动态加载外部的 js (有时候也包含执行页面上已经定义的一些模块函数)。
粗略整理,加载外部 js 的方法大致有这么几种:
| 方法 | 说明 |
|---|---|
| XHR Eval | 通过 Ajax 方式获取代码,并通过 eval 方式执行代码。 |
| XHR Injection | 通过 Ajax 方式获取代码,并在页面上创建一个 script 元素,将 Ajax 取得的代码注入。 |
| Script in Iframe | 通过 iframe 加载 js。 |
| Script DOM Element | 使用 JavaScript 动态创建 script DOM 元素并设置其 src 属性。 |
| Script Defer/Async | 严格来说,这一条不算是动态加载外部脚本的方法,但很多动态加载外部脚本的方法里都会用到 sctipt 的 defer 或 async 属性,所以也把它单独列在这儿。这个方法利用 script 的 defer 属性,让脚本“推迟”执行,不阻塞页面加载,或者设置 async 属性,让脚本异步执行。遗憾的是这两个属性不是所有浏览器都支持。 |
| document.write Script Tag | 通过 document.write 把 HTML 标签 script 写入到页面中。 |
| cache trick | 先使用自定义的 script 的 type 属性(如 <script type=”text/cache” …),甚至使用 Image、Object 等 HTML 对象将 js “预下载”(下载到浏览器缓存里),等真正需要执行对应代码时再将它真正地插入页面中。 |
| Web Worker | 部分浏览器支持 web worker 功能,可以创建一个 worker 在后台工作,包括加载外部脚本。 |
各种方式各有优缺点,比如能否跨域、是否会阻塞其它资源的下载(能否并行下载)、能否管理控制执行顺序、耗费的资源、是否兼容各大浏览器等(部分方法的特性可参考这儿)。事实上,如果仅仅只是想把外部 js 动态加载到页面上的话还是很简单的,但如果可能要同时加载多个 js ,希望它们能尽可能快地下载(并行下载),并且有时候可能希望它们能保证执行顺序,而且要兼容各大主流浏览器,就会有一点复杂了。为了实现这样的目标,LABjs 使用了上面方法中的三种,分别是:Script DOM Element、cache trick、XHR Injection。下面我们先详细看一下这三种加载 js 方式的优缺点。
Script DOM Element
这是最常用的方式,它的优点很多:可以跨域、可以加载任何格式的外部 js(不需要对外部 js 进行重构)、不会阻塞其它资源的下载、实现简单。并且,在 Firefox/Opera 下,通过这种方式插入多个 js 脚本,浏览器会并行下载这些 js (同时下载几个取决于浏览器的并行连接数),同时还能保证它们的执行顺序与它们被插入页面的顺序相同。不过,在 IE(以及 Safari/Chrome)下,如果用这种方式同时插入多个 js,这些 js 也会并行下载,但浏览器不能保证这些 js 的执行顺序,哪个先下载完浏览器就会先执行哪个。
从上面可以看到,Script DOM Element这种方式在 Firefox/Opera 下的表现近乎完美,事实上,在这些浏览器下,Script DOM Element 也是 LABjs 默认使用的方式。
cache trick
上面我们看到,Script DOM Element方式可以满足 Firefox/Opera 下的需求了,那么 IE/Safari/Chrome 下怎么办呢?LABjs 中使用了一种 cache trick 的手段,它创建一个 script 标签,并将其 type 设为 “text/cache” ,把它插入页面。这种 trick 似乎是 LABjs 的作者 @getify 首先提出来的。这个 “text/cache” 只是为了语义上有意义,你完全可以把 type 属性设为任何不为 “text/javascript” 的值,比如 “love/oldj” 等。
根据 LABjs 作者博客上的文章,在 IE/Safari/Chrome 这三个浏览器下,如果一个 script 元素的 type 属性为一个类似 “text/cache” 这样的浏览器不认识的值,浏览器仍然会正常下载这些 js ,并且下载完成后正常触发 onload 事件,但是它们将不会执行这些脚本。于是,通过这样的方式可以先将 script 加载到浏览器缓存中,等对应的 js 需要被执行时,再创建一个新的 script 元素,设置其 type 为正确的值,src 为刚才“预下载”的脚本的值,将其插入页面,这样,这个 script 将会从缓存(而不是网络)瞬间加载对应的 js,并立即执行。通过这样的方式,LABjs 在 IE/Safari/Chrome 等浏览器下实现了脚本的预加载以及执行顺序管理。
另外,”text/cache” 这种 trick 在 Firefox/Opera 下是不能工作的,因为这两种浏览器会拒绝下载它们不认识的 type 的 script,这样也就无法“预加载”了。不过这不会造成问题,因为这两种浏览器可以直接通过上面的 Script DOM Element 的方式来加载外部脚本。(Firefox 4 曾试图更改相关特性,结果导致 getify 的强烈不满,具体事件可看这里。)同时,这种方法需要浏览器支持并且开启缓存,如果浏览器禁用或不支持缓存,也就无法“预加载”了,而且更糟糕的是,几乎没有 js 方法能检查用户浏览器是否支持并开启了缓存。
XHR Injection
cache trick 方式虽然可以实现并行下载、管理执行顺序,但毕竟是一种很依赖于特定浏览器特定版本的特性的方法,如果万一哪一天某个浏览器某个新版本改变了它的特性,这种方式可能就失效了,作者本人也觉得它很丑。所以,如果 LABjs 检测到要下载的外部 js 与当前页面是同域并且浏览器不为 Firefox/Opera(不能保证执行顺序与插入顺序一致)的话,它会优先采用 XHR Injection 的方式。
XHR Injection 的原理很简单,就不多说了。下面我们来看一看有了这三种方式后, LABjs 是如何实现的。
LABjs 的内部逻辑比较复杂,变量也比较多。不过简单来看,LABjs 的结构主要如下图所示。
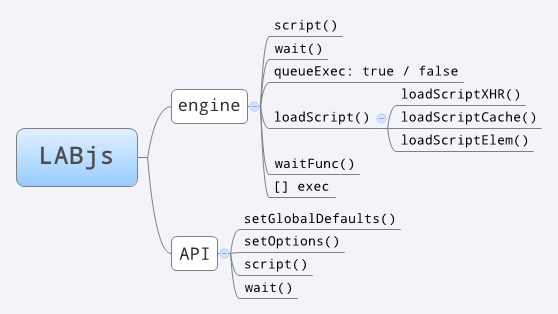
可以看到,LABjs 对外公开的 API 一共有 4 个方法,分别为 setGlobalDefaults() 方法,setOptions() 方法,script() 方法以及 wait() 方法。其中最常用的是 script() 以及 wait()。LABjs 的内部变量中,最重要的是一个叫 engine 的对象,它负责 script() 以及 wait() 方法的具体实现以及内部变量的维护。
engine 对象主要有这么几个方法:script()、wait()、loadScript() 以及 waitFunc(),另外还有两个主要的属性:queueExec 及 exec。下面简单解释一下这几个方法及属性的作用。
script() 公共 API 中的 script() 事实上是生成一个 engine 对象,再调用这个 engine 中的 sctipt() 方法。这个方法根据 queueExec 的值,调用 loadScript() 方法对传入的 js 地址进行加载或预加载操作。
wait() 公共 API 中的 wait() 事实上是生成一个 engine 对象,再调用这个 engine 中的 wait() 方法。
loadScript() 加载 js 的方法。根据具体浏览器情况,以及是否同域,这个方法会调用上面提到的三种方式之一来加载 js,或者预加载 js ,或者将预加载完成的 js 最终加载到页面中。
waitFunc() 每一个 engine 内部有一个 ready 变量,默认为 false,如果这个 engine 要加载的 js 都已加载完成了,则 ready 为 true,同时执行 waitFunc(),这个 waitFunc() 里一般包含你想要在指定 js 加载完成后执行的函数,接下来则是触发下一个 engine(如果有的话)。
queueExec 这是一个布尔值属性,用于标明当前 engine 加载 js 时是否需要预加载。默认状态下,queueExec 为 false,表示直接加载指定的 js,当使用了 wait() 方法后,queueExec 在新生成的 engine 里的值为 true,表示这个 engine 中的 js 先预加载。
exec 这是一个数组,其中的元素都是待执行的函数。预加载 js 时,loadScript() 会立即执行以便预加载指定 js,同时同样的 loadScript() 也会被 push 一份到当前 engine 对象的exec 数组中,并在当前 engine 的 waitFunc() 执行时被依次调用,loadScript() 这次执行时则会将刚才预加载的 js 真正加载到页面上。
整个流程大致如下:
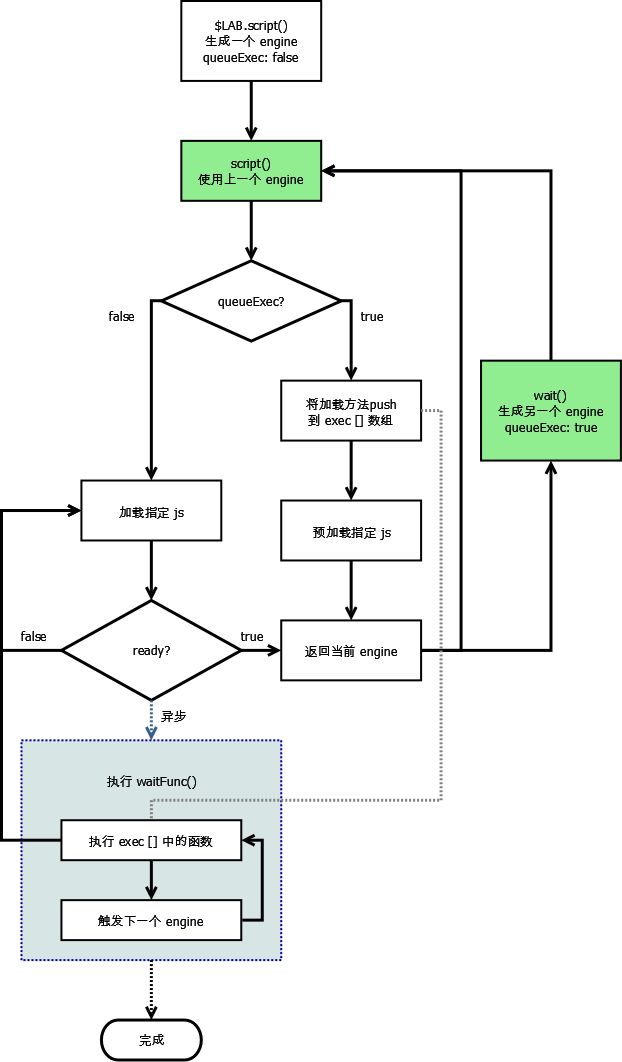
上面这个流程图只是一个简化版(比如有关浏览器判断,以及选择哪种方式下载 js 的部分全部省略了),LABjs 内部的完整的逻辑要更加复杂。
图中的 ready 表示当前 engine 中引入的 js 是否都已加载完成(LABjs 中有一个同名的内部变量)。可以看到,一开始执行 $LAB.script 时,LABjs 会生成一个 engine 对象,在此之后的链式调用的所有的 script() 方法实际上调用的都是这个 engine 内部的 script() 方法,直到链条上出现 .wait() 为止。wait() 方法将生成一个新的 engine,之后所有通过的 script() 方法引入的 js 都将先被预加载,等上一个 engine 完成时才被触发正式加载。
关于 LABjs 的实现原理就介绍到这儿了。这篇帖子写了很久,在电脑里及脑子里反复修改了很多次,一直觉得说得不够清楚而不敢放上来,不过貌似现在这个版本依然写得很复杂,要写好技术文章果然不是一件容易的事,呵呵。
LABjs 中用到了很多技巧,比如用 setTimeout(fn, 0) 的方式把一个耗时的操作“丢”到另一个“线程”上去。如果有兴趣,不妨花一些时间阅读一下它的源代码。与其它动态加载外部 js 的解决方案相比,LABjs 是我见过的最小巧同时最强大的一个,它的最大特点是能尽可能并行地下载待加载的 js ,但需要时又能保证 js 的执行顺序。其它 js loader 也有很多,但它们默认情况下要么不支持并行下载,要么虽然支持并行下载但在部分浏览器下不能保证 js 的执行顺序,从这个角度来看,LABjs 是它们中最出色的。但其它解决方案也各有特色,比如 RequireJS 等,与 LABjs 相比,它不仅能加载外部 js ,还能动态地定义、添加 js 模块,在某些应用场景下,它可能更合适或更为强大。
另外,LABjs 也有一些不足,比如一些 trick 方法过于信赖特定浏览器特定版本的非标准(或标准中没有定义)的特性,但这些特性是无法通过 js 来检测的,只能通过判断浏览器版本信息以及以往的经验来假设它具有或不具有某种特性。这种方式比较丑陋,而且是不安全的,如果某一天某个浏览器的新版本改变了相关的特性,js 代码将完全无法知道,于是相关的功能或 trick 就失效了。最好的办法是能直接通过检测浏览器特性来完成相关的判断,但谁让有些特性真的难以取到呢?而且,更好的方式,大概是一起推动更合理的标准,让将来某一天在新的浏览器下能非常轻松自然地实现 js loader,让 LABjs 等解决方案彻底地退出前端开发的历史舞台,或许这才是前端工程师们最美好的未来。

