第六周:生成式对抗网络
第六周:生成对抗网络
一、视频学习
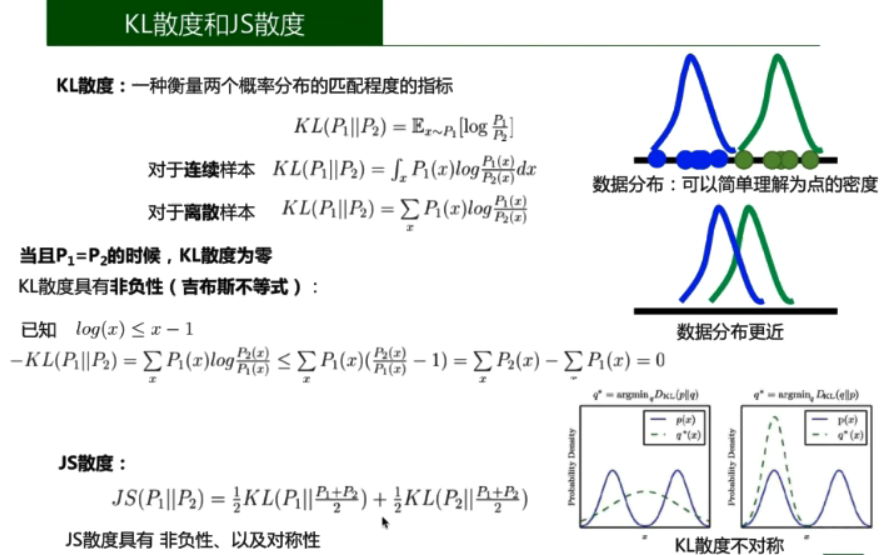
GAN的类型
1,GAN 生成式对抗网络
2,cGAN 条件生成式对抗网络
3,DCGAN 深度卷积生成式对抗网络
4,WGAN/WGAN-GP
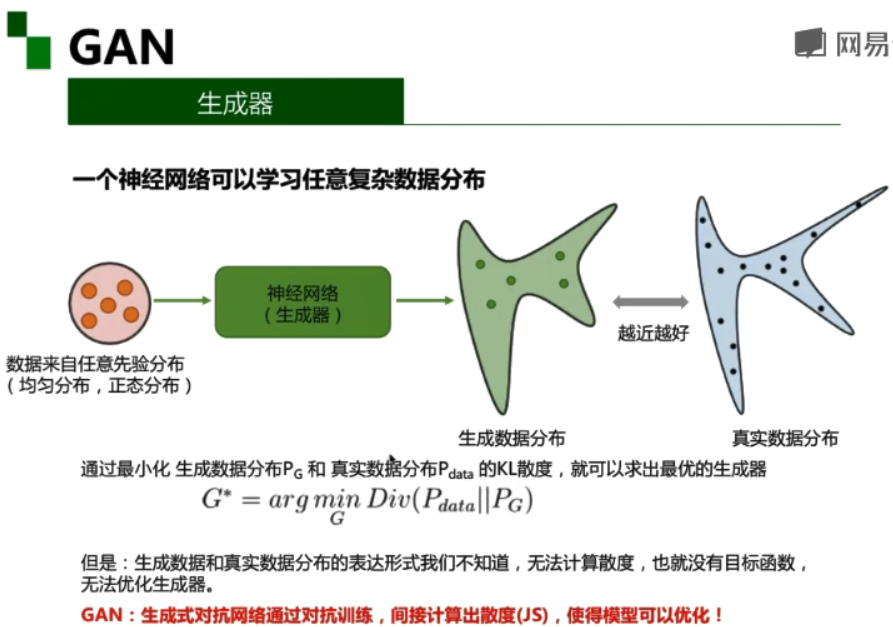
1.GAN
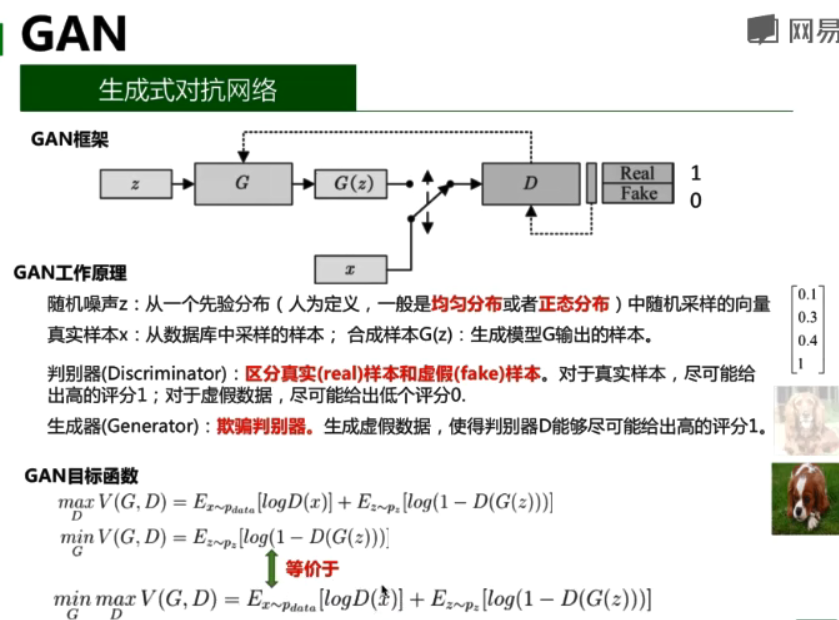
生成式对抗网络由判别器和生成器组成:
- 判别器(Discriminator):区分真实(real)样本和虚假(fake)样本。对于真实样本,尽可能给出高的评分1;对于虚假数据,尽可能给出低个评分0。
- 生成器(Generator):欺骗判别器。生成虚假数据,使得判别器D能够尽可能给出高的评分1。
.
2.cGAN
网络结构

3.DCGAN
原始的GAN使用全连接网络作为判别器和生成器
- 不利于建模图像信息
- 参数量大,需要大量的计算资源,难以优化
DCGAN,使用卷积神经网络作为判别器和生成器
通过大量的工程实践,经验性地提出一系列的网络结构和优化策略,来有效的建模图像数据
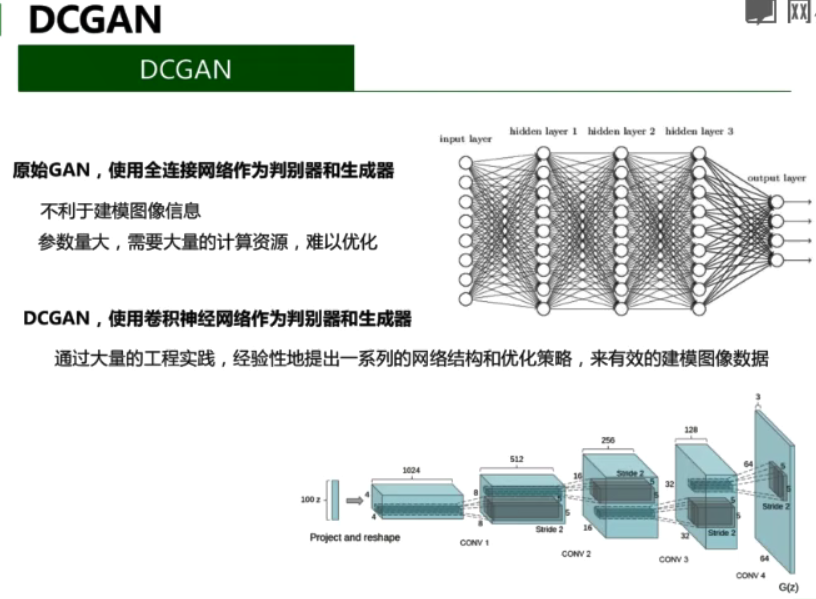
网络结构(判别器)
-
使用滑动卷积(strided convolution)
-
除了输入层,全部使用批归一化
-
使用Leaky ReLu激活函数
-
除了最后一层,不使用全连接层
网络结构(生成器)
-
使用滑动反卷积(fractional strided convolution)
-
除了输出层,全部使用批归一化
-
使用ReLu激活函数,最后一层使用tanh激活函数
滑动卷积、滑动反卷积:
使得判别器和生成器可以学习自己的上采样和下采样策略
批归一化:
训练更稳定
Tanh激活函数:
更快的学习到真实数据的颜色空间
训练策略
-
数据预处理:所有输入数据归一化到[-1,1]
-
激活函数:Leaky ReLu的斜率设置为0.2
-
初始化:使用均值为0,标准差为0.02的正态分布初始化网络参数
-
优化器:使用Adam优化器,学习率为0.0002,betal=0.5,beta2=0.999

二、代码练习
一个简单的 GAN
import torch.nn as nn z_dim = 32 hidden_dim = 128 # 定义生成器 net_G = nn.Sequential( nn.Linear(z_dim,hidden_dim), nn.ReLU(), nn.Linear(hidden_dim, 2)) # 定义判别器 net_D = nn.Sequential( nn.Linear(2,hidden_dim), nn.ReLU(), nn.Linear(hidden_dim,1), nn.Sigmoid()) # 网络放到 GPU 上 net_G = net_G.to(device) net_D = net_D.to(device)
# 定义网络的优化器 optimizer_G = torch.optim.Adam(net_G.parameters(),lr=0.001) optimizer_D = torch.optim.Adam(net_D.parameters(),lr=0.001) batch_size = 250 nb_epochs = 1000 loss_D_epoch = [] loss_G_epoch = [] for e in range(nb_epochs): np.random.shuffle(X) real_samples = torch.from_numpy(X).type(torch.FloatTensor) loss_G = 0 loss_D = 0 for t, real_batch in enumerate(real_samples.split(batch_size)): # 固定生成器G,改进判别器D # 使用normal_()函数生成一组随机噪声,输入G得到一组样本 z = torch.empty(batch_size,z_dim).normal_().to(device) fake_batch = net_G(z) # 将真、假样本分别输入判别器,得到结果 D_scores_on_real = net_D(real_batch.to(device)) D_scores_on_fake = net_D(fake_batch) # 优化过程中,假样本的score会越来越小,真样本的score会越来越大,下面 loss 的定义刚好符合这一规律, # 要保证loss越来越小,真样本的score前面要加负号 # 要保证loss越来越小,假样本的score前面是正号(负负得正) loss = -torch.mean(torch.log(1-D_scores_on_fake) + torch.log(D_scores_on_real)) # 梯度清零 optimizer_D.zero_grad() # 反向传播优化 loss.backward() # 更新全部参数 optimizer_D.step() loss_D += loss # 固定判别器,改进生成器 # 生成一组随机噪声,输入生成器得到一组假样本 z = torch.empty(batch_size,z_dim).normal_().to(device) fake_batch = net_G(z) # 假样本输入判别器得到 score D_scores_on_fake = net_D(fake_batch) # 我们希望假样本能够骗过生成器,得到较高的分数,下面的 loss 定义也符合这一规律 # 要保证 loss 越来越小,假样本的前面要加负号 loss = -torch.mean(torch.log(D_scores_on_fake)) optimizer_G.zero_grad() loss.backward() optimizer_G.step() loss_G += loss if e % 50 ==0: print(f'\n Epoch {e} , D loss: {loss_D}, G loss: {loss_G}') loss_D_epoch.append(loss_D) loss_G_epoch.append(loss_G)
z = torch.empty(n_samples,z_dim).normal_().to(device) fake_samples = net_G(z) fake_data = fake_samples.cpu().data.numpy() fig, ax = plt.subplots(1, 1, facecolor='#4B6EA9') all_data = np.concatenate((X,fake_data),axis=0) Y2 = np.concatenate((np.ones(n_samples),np.zeros(n_samples))) plot_data(ax, all_data, Y2) plt.show()
z = torch.empty(10*n_samples,z_dim).normal_().to(device) fake_samples = net_G(z) fake_data = fake_samples.cpu().data.numpy() fig, ax = plt.subplots(1, 1, facecolor='#4B6EA9') all_data = np.concatenate((X,fake_data),axis=0) Y2 = np.concatenate((np.ones(n_samples),np.zeros(10*n_samples))) plot_data(ax, all_data, Y2) plt.show();
2.CGAN
首先实现CGAN。下面分别是 判别器 和 生成器 的网络结构,可以看出网络结构非常简单,具体如下:
# 开始训练,一共训练total_epochs for epoch in range(total_epochs): # torch.nn.Module.train() 指的是模型启用 BatchNormalization 和 Dropout # torch.nn.Module.eval() 指的是模型不启用 BatchNormalization 和 Dropout # 因此,train()一般在训练时用到, eval() 一般在测试时用到 generator = generator.train() # 训练一个epoch for i, data in enumerate(dataloader): # 加载真实数据 real_images, real_labels = data real_images = real_images.to(device) # 把对应的标签转化成 one-hot 类型 tmp = torch.FloatTensor(real_labels.size(0), 10).zero_() real_labels = tmp.scatter_(dim=1, index=torch.LongTensor(real_labels.view(-1, 1)), value=1) real_labels = real_labels.to(device) # 生成数据 # 用正态分布中采样batch_size个随机噪声 z = torch.randn([batch_size, z_dim]).to(device) # 生成 batch_size 个 ont-hot 标签 c = torch.FloatTensor(batch_size, 10).zero_() c = c.scatter_(dim=1, index=torch.LongTensor(np.random.choice(10, batch_size).reshape([batch_size, 1])), value=1) c = c.to(device) # 生成数据 fake_images = generator(z,c) # 计算判别器损失,并优化判别器 real_loss = bce(discriminator(real_images, real_labels), ones) fake_loss = bce(discriminator(fake_images.detach(), c), zeros) d_loss = real_loss + fake_loss d_optimizer.zero_grad() d_loss.backward() d_optimizer.step() # 计算生成器损失,并优化生成器 g_loss = bce(discriminator(fake_images, c), ones) g_optimizer.zero_grad() g_loss.backward() g_optimizer.step() # 输出损失 print("[Epoch %d/%d] [D loss: %f] [G loss: %f]" % (epoch, total_epochs, d_loss.item(), g_loss.item()))
#用于生成效果图 # 生成100个随机噪声向量 fixed_z = torch.randn([100, z_dim]).to(device) # 生成100个one_hot向量,每类10个 fixed_c = torch.FloatTensor(100, 10).zero_() fixed_c = fixed_c.scatter_(dim=1, index=torch.LongTensor(np.array(np.arange(0, 10).tolist()*10).reshape([100, 1])), value=1) fixed_c = fixed_c.to(device) generator = generator.eval() fixed_fake_images = generator(fixed_z, fixed_c) plt.figure(figsize=(8, 8)) for j in range(10): for i in range(10): img = fixed_fake_images[j*10+i, 0, :, :].detach().cpu().numpy() img = img.reshape([28, 28]) plt.subplot(10, 10, j*10+i+1) plt.imshow(img, 'gray')
3.DCGAN
# 开始训练,一共训练 total_epochs for e in range(total_epochs): # 给generator启用 BatchNormalization g_dcgan = g_dcgan.train() # 训练一个epoch for i, data in enumerate(dcgan_dataloader): # 加载真实数据,不加载标签 real_images, _ = data real_images = real_images.to(device) # 用正态分布中采样batch_size个噪声,然后生成对应的图片 z = torch.randn([batch_size, z_dim]).to(device) fake_images = g_dcgan(z) # 计算判别器损失,并优化判别器 real_loss = bce(d_dcgan(real_images), ones) fake_loss = bce(d_dcgan(fake_images.detach()), zeros) d_loss = real_loss + fake_loss d_dcgan_optim.zero_grad() d_loss.backward() d_dcgan_optim.step() # 计算生成器损失,并优化生成器 g_loss = bce(d_dcgan(fake_images), ones) g_dcgan_optim.zero_grad() g_loss.backward() g_dcgan_optim.step() # 输出损失 print ("[Epoch %d/%d] [D loss: %f] [G loss: %f]" % (e, total_epochs, d_loss.item(), g_loss.item()))
#用于生成效果图 # 生成100个随机噪声向量 fixed_z = torch.randn([100, z_dim]).to(device) g_dcgan = g_dcgan.eval() fixed_fake_images = g_dcgan(fixed_z) plt.figure(figsize=(8, 8)) for j in range(10): for i in range(10): img = fixed_fake_images[j*10+i, 0, :, :].detach().cpu().numpy() img = img.reshape([32, 32]) plt.subplot(10, 10, j*10+i+1) plt.imshow(img, 'gray')

