第四周:卷积神经网络 part3
第四周:卷积神经网络 part3
【第一部分】 问题总结
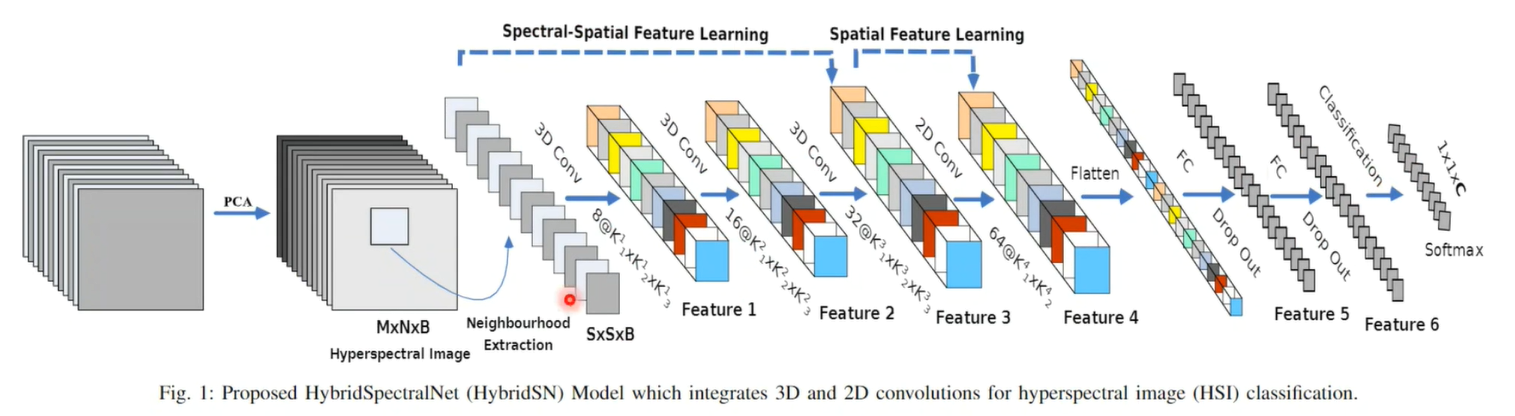
1.HybridSN 高光谱分类网络
HybridSN 网络解决的是对高光谱图像的的分类
加入了3D和2D卷积是的可以对高光谱图像进行很好的分类
其中1D、2D和3D的卷积区别在于
1D卷积是对只有一个维度的时间序列提取特征,比如信号、股价、天气、文本等等。普通的
2D卷积是提取的单张静态图像的空间特征,同神经网络结合之后在图像的分类、检测等任务上取得了很好的效果。但是对视频,即多帧图像就束手无策了,
因为2D卷积没有考虑到图像之间的时间维度上的物体运动信息,即光流场。
因此,为了能够对视频进行特征,以便用来分类等任务,就提出了3D卷积,在卷积核中加入时间维度。下图就很好的说明了2D卷积和3D卷积之间的差异。
回顾论文HybridSN网络的结构
2.代码实现
代码是参考了同学的,写的非常详细,也研究说明了 我们每次模型结果的不一样的原因
如果网络中添加了BN层和dropout层而不使用model.eval()的话,
每次测试的时候 模型并不是固定的,所以每次的分类结果可能并不一致。
HybridSN 高光谱分类网络的优化
https://www.cnblogs.com/yuzhenfu/p/13509743.html
【第二部分】 视频学习
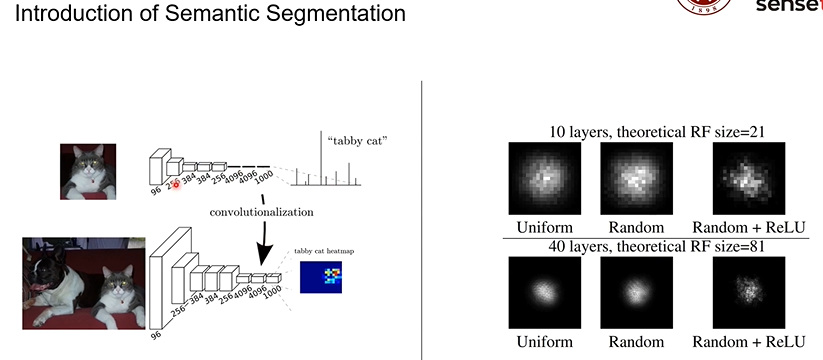
李夏《语义分割中的自注意力机制和低秩重重建》
视频中说道,我们的网络模型可以对抓子的识别但无法识别是狗还是猫的
是网络中缺少对图片语义相关的分割和联系,仅仅对局部的信息的识别
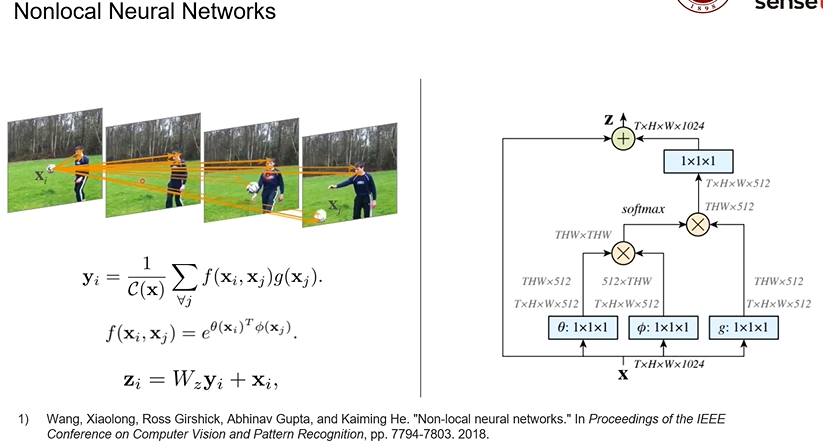
何恺明团队对视频中识别球和人之间的关系
语义分割对不同的物体的分割
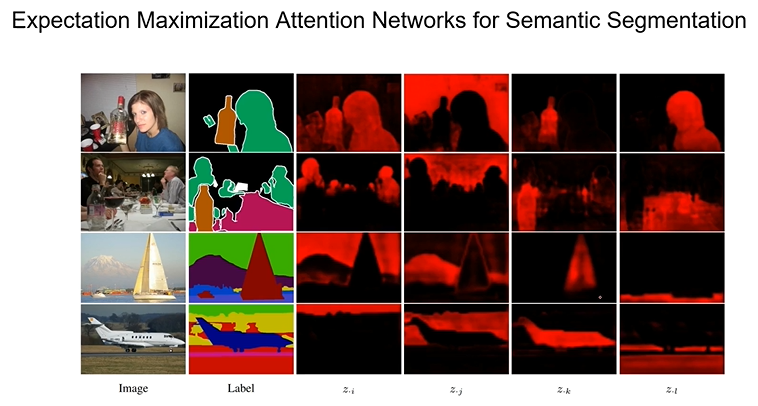
程明明教授的报告《图像语义分割前沿进展》
为了获得多尺寸表示能力,要求特征提取可以以较大范围的感受野来描述不同尺寸的 object/part/context。
CNN通过简单的堆叠卷积操作得到coarse-to-fine的多尺寸特征。
VGG,Alex通过简单的堆积卷积让多尺寸信息成为了可能。
Inception系列通过组合不同大小的卷积核来获得多尺寸信息。
作为backbone的CNN表现更高效,多尺寸的表征能力更强。
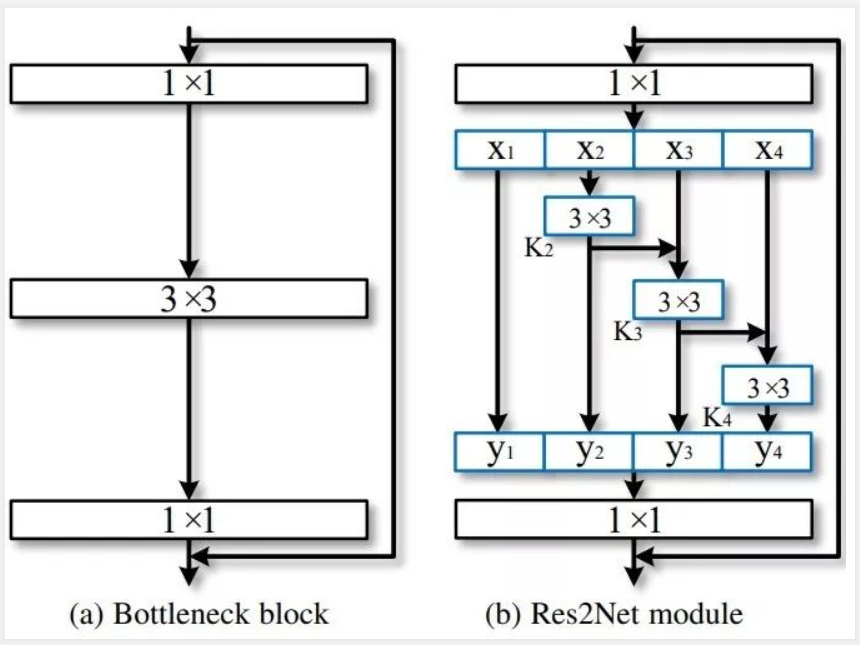
对经过1x1输出后的特征图按通道数均分为4块,每一部分做3*3卷积或融合后进行卷积,这样可以得到不同感受野大小的输出。
【第三部分】 Paper阅读
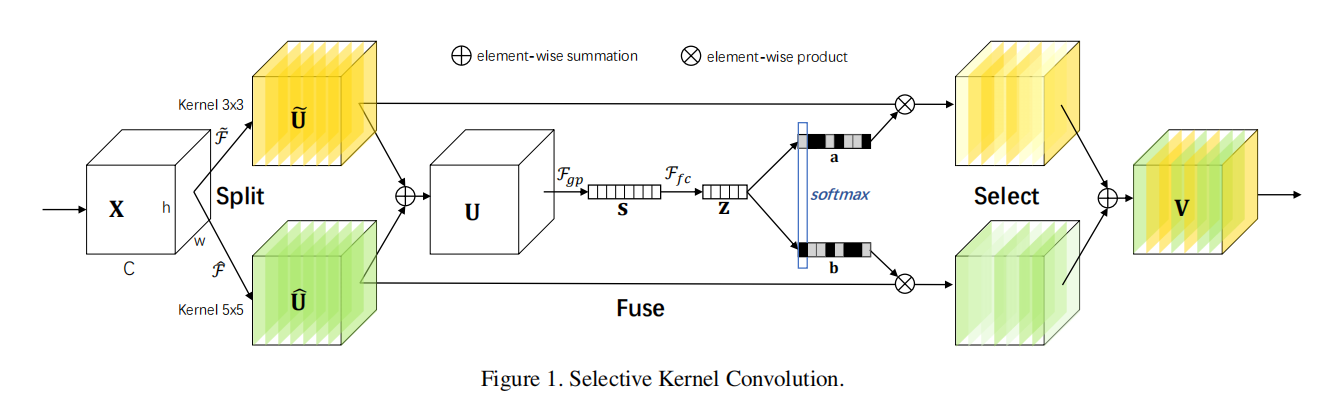
CVPR 2019 的论文《Selective Kernel Networks》
这篇论文可以对比SENet学习,也是对SENet的改进
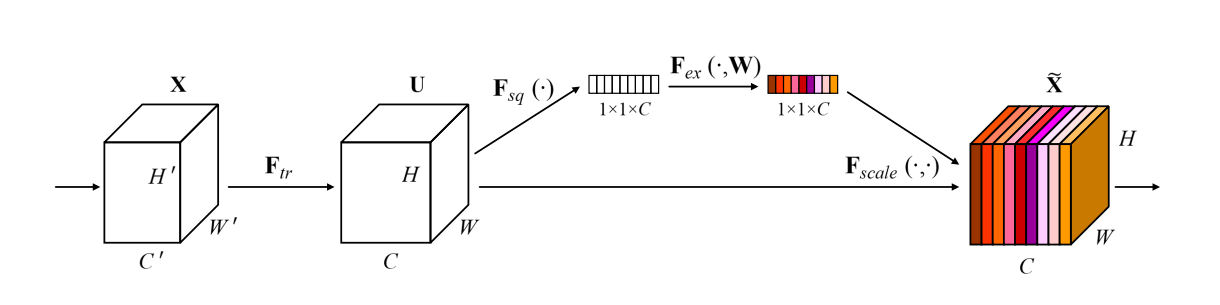
SENet两个过程
Squeeze压缩:嵌入全局信息
将全局空间信息压缩成一个通道描述符,利用全局平均池化得到一个通道维度
(特征维度)上的统计数据。
Excitation激发:自适应重标定
根据输入特征的描述符,来给每个通道赋予权重。
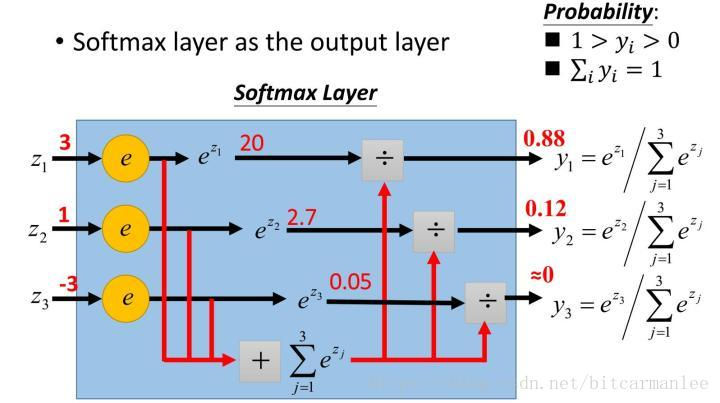
softmax函数
在机器学习尤其是深度学习中,softmax是个非常常用而且比较重要的函数,尤其在多分类的场景中使用广泛。
他把一些输入映射为0-1之间的实数,并且归一化保证和为1,因此多分类的概率之和也刚好为1。
首先我们简单来看看softmax是什么意思。顾名思义,softmax由两个单词组成,其中一个是max。
对于max我们都很熟悉,比如有两个变量a,b。如果a>b,则max为a,反之为b。用伪码简单描述一下就是 if a > b return a; else b。
另外一个单词为softmax存在的一个问题是什么呢?
如果将max看成一个分类问题,就是非黑即白,最后的输出是一个确定的变量。
更多的时候,我们希望输出的是取到某个分类的概率,或者说,
我们希望分值大的那一项被经常取到,而分值较小的那一项也有一定的概率偶尔被取到,
所以我们就应用到了soft的概念,即最后的输出是每个分类被取到的概率。
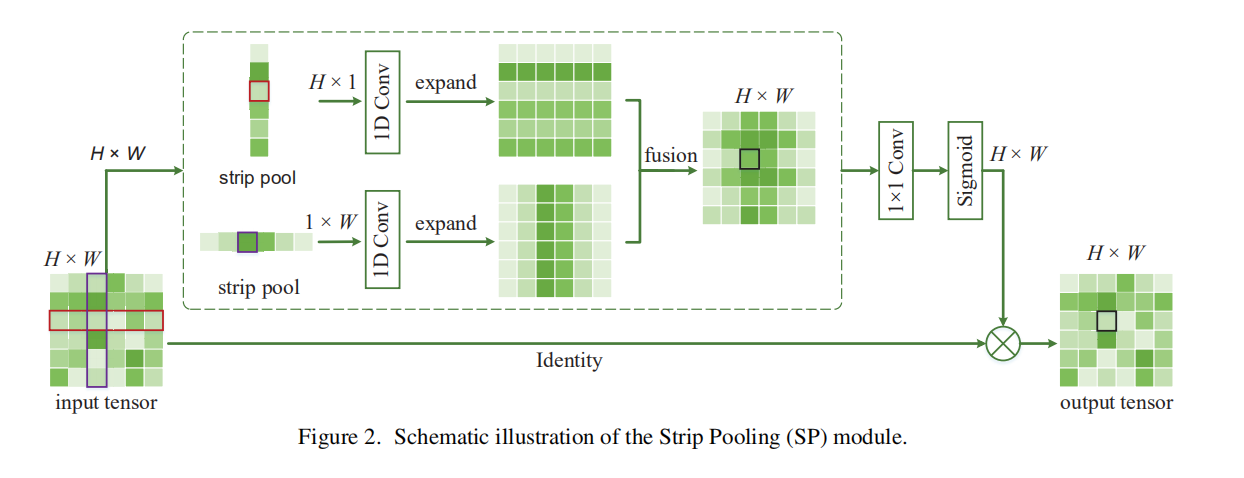
CVPR 2020 的论文《Strip Pooling: Rethinking Spatial Pooling for Scene Parsing》
SPNet是运用条状卷积,打破传统1*1,3*3,5*5等方卷积。
这样跟好对条状物体的识别和分类