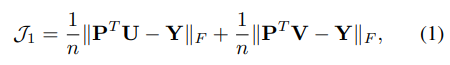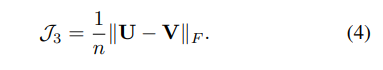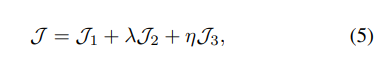第三周:卷积神经网络 part2
第三周:卷积神经网络 part2
【第一部分】 问题总结
1.在第二部分代码练习中可以发现每次的测试结果都会不同,是否这种差异存在于所有CNN模型
2.DSCMR中的J2损失函数的作用是什么
【第二部分】 代码练习
1、MobileNetV1
MobileNetV1 网络:简要阅读谷歌2017年的论文《MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications》
阅读代码:https://github.com/OUCTheoryGroup/colab_demo/blob/master/202003_models/MobileNetV1_CIFAR10.ipynb
Depthwise(DW)卷积与Pointwise(PW)卷积,合起来被称作Depthwise Separable Convolution(参见Google的Xception),
该结构和常规卷积操作类似,可用来提取特征,但相比于常规卷积操作,其参数量和运算成本较低。
所以在一些轻量级网络中会碰到这种结构如MobileNet。
class HybridSN(nn.Module):
def __init__(self):
super(HybridSN, self).__init__()
self.conv1 = nn.Conv3d(1, 8, (7, 3, 3), stride=1, padding=0)
self.conv2 = nn.Conv3d(8, 16, (5, 3, 3), stride=1, padding=0)
self.conv3 = nn.Conv3d(16, 32, (3, 3, 3), stride=1, padding=0)
self.conv4 = nn.Conv2d(576, 64, kernel_size=3, stride=1, padding=0)
self.bn1 = nn.BatchNorm2d(64)
self.fc1 = nn.Linear(18496, 256)
self.dropout1 = nn.Dropout(p=0.4)
self.fc2 = nn.Linear(256, 128)
self.dropout2 = nn.Dropout(p=0.4)
self.fc3 = nn.Linear(128, class_num)
def forward(self, x):
out = self.conv1(x)
out = self.conv2(out)
out = self.conv3(out)
#print(batch)
out = out.reshape(batch, 576, 19, 19)
out = self.conv4(out)
out = self.bn1(out)
out = F.relu(out)
out = out.view(-1, 64 * 17 * 17)
out = self.fc1(out)
out = F.relu(out)
out = self.dropout1(out)
out = self.fc2(out)
out = F.relu(out)
out = self.dropout2(out)
out = self.fc3(out)
return out
class MobileNetV1(nn.Module):
# (128,2) means conv planes=128, stride=2
cfg = [(64,1), (128,2), (128,1), (256,2), (256,1), (512,2), (512,1),
(1024,2), (1024,1)]
def __init__(self, num_classes=10):
super(MobileNetV1, self).__init__()
self.conv1 = nn.Conv2d(3, 32, kernel_size=3, stride=1, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(32)
self.layers = self._make_layers(in_planes=32)
self.linear = nn.Linear(1024, num_classes)
def _make_layers(self, in_planes):
layers = []
for x in self.cfg:
out_planes = x[0]
stride = x[1]
layers.append(Block(in_planes, out_planes, stride))
in_planes = out_planes
return nn.Sequential(*layers)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.layers(out)
out = F.avg_pool2d(out, 2)
out = out.view(out.size(0), -1)
out = self.linear(out)
return out
# 网络放到GPU上
net = MobileNetV1().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.001)
for epoch in range(10): # 重复多轮训练
for i, (inputs, labels) in enumerate(trainloader):
inputs = inputs.to(device)
labels = labels.to(device)
# 优化器梯度归零
optimizer.zero_grad()
# 正向传播 + 反向传播 + 优化
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# 输出统计信息
if i % 100 == 0:
print('Epoch: %d Minibatch: %5d loss: %.3f' %(epoch + 1, i + 1, loss.item()))
print('Finished Training')
correct = 0 total = 0 for data in testloader: images, labels = data images, labels = images.to(device), labels.to(device) outputs = net(images) _, predicted = torch.max(outputs.data, 1) total += labels.size(0) correct += (predicted == labels).sum().item() print('Accuracy of the network on the 10000 test images: %.2f %%' % ( 100 * correct / total))
Accuracy of the network on the 10000 test images: 78.30 % Accuracy of the network on the 10000 test images: 77.08 % Accuracy of the network on the 10000 test images: 78.27 %
2、MobileNetV2
MobileNetV2 网络:简要阅读谷歌在CVPR2018上的论文《MobileNetV2: Inverted Residuals and Linear Bottlenecks》,体会第二个版本的改进。
阅读代码:https://github.com/OUCTheoryGroup/colab_demo/blob/master/202003_models/MobileNetV2_CIFAR10.ipynb
#expand + Depthwise + Pointwise class Block(nn.Module): def __init__(self, in_planes, out_planes, expansion, stride): super(Block, self).__init__() self.stride = stride planes = expansion * in_planes self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=1, stride=1, padding=0, bias=False) self.bn1 = nn.BatchNorm2d(planes) self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride, padding=1, groups=planes, bias=False) self.bn2 = nn.BatchNorm2d(planes) self.conv3 = nn.Conv2d(planes, out_planes, kernel_size=1, stride=1, padding=0, bias=False) self.bn3 = nn.BatchNorm2d(out_planes) if stride == 1 and in_planes != out_planes: self.shortcut = nn.Sequential( nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=1, padding=0, bias=False), nn.BatchNorm2d(out_planes)) if stride == 1 and in_planes == out_planes: self.shortcut = nn.Sequential() def forward(self, x): out = F.relu(self.bn1(self.conv1(x))) out = F.relu(self.bn2(self.conv2(out))) out = self.bn3(self.conv3(out)) if self.stride == 1: return out + self.shortcut(x) else: return out
#创建MobileNetV2网络 class MobileNetV2(nn.Module): #(expansion,out_planes,num_blocks,stride) cfg = [(1,16,1,1),(6,24,2,1),(6,32,3,2),(6,64,4,2),(6,96,3,1),(6,160,3,2),(6,320,1,1)] def __init__(self,num_classes=10): super(MobileNetV2,self).__init__() self.conv1 = nn.Conv2d(3,32,kernel_size=3,stride=1,padding=1,bias=False) self.bn1 = nn.BatchNorm2d(32) self.layers = self._make_layers(in_planes=32) self.conv2 = nn.Conv2d(320,1280,kernel_size=1,stride=1,padding=0,bias=False) self.bn2 = nn.BatchNorm2d(1280) self.linear = nn.Linear(1280,num_classes) def _make_layers(self,in_planes): layers = [] for expansion,out_planes,num_blocks,stride in self.cfg: strides = [stride] + [1]*(num_blocks-1) for stride in strides: layers.append(Block(in_planes,out_planes,expansion,stride)) in_planes = out_planes return nn.Sequential(*layers) def forward(self,x): out = F.relu(self.bn1(self.conv1(x))) out = self.layers(out) out = F.relu(self.bn2(self.conv2(out))) out = F.avg_pool2d(out,4) out = out.view(out.size(0),-1) out = self.linear(out) return out
第一次测试结果: Accuracy of the network on the 10000 test images: 78.89 % 第二次测试结果: Accuracy of the network on the 10000 test images: 82.07 % 第三次测试结果: Accuracy of the network on the 10000 test images: 81.43 %
3、HybridSN
HybridSN 高光谱分类网络:阅读论文《HybridSN: Exploring 3-D–2-DCNN Feature Hierarchy for Hyperspectral Image Classification》,思考3D卷积和2D卷积的区别。
阅读代码:https://github.com/OUCTheoryGroup/colab_demo/blob/master/202003_models/HybridSN_GRSL2020.ipynb
class HybridSN(nn.Module): def __init__(self): super(HybridSN, self).__init__() self.conv1 = nn.Conv3d(1, 8, (7, 3, 3), stride=1, padding=0) self.conv2 = nn.Conv3d(8, 16, (5, 3, 3), stride=1, padding=0) self.conv3 = nn.Conv3d(16, 32, (3, 3, 3), stride=1, padding=0) self.conv4 = nn.Conv2d(576, 64, kernel_size=3, stride=1, padding=0) self.bn1 = nn.BatchNorm2d(64) self.fc1 = nn.Linear(18496, 256) self.dropout1 = nn.Dropout(p=0.4) self.fc2 = nn.Linear(256, 128) self.dropout2 = nn.Dropout(p=0.4) self.fc3 = nn.Linear(128, class_num) def forward(self, x): out = self.conv1(x) out = self.conv2(out) out = self.conv3(out) #print(batch) out = out.reshape(batch, 576, 19, 19) out = self.conv4(out) out = self.bn1(out) out = F.relu(out) out = out.view(-1, 64 * 17 * 17) out = self.fc1(out) out = F.relu(out) out = self.dropout1(out) out = self.fc2(out) out = F.relu(out) out = self.dropout2(out) out = self.fc3(out) return out
#转为二维+三维 class HybridSN(nn.Module): def __init__(self): super(HybridSN, self).__init__() self.conv4 = nn.Conv2d(30, 64, kernel_size=3, stride=1, padding=0) self.bn1 = nn.BatchNorm2d(64) self.conv1 = nn.Conv3d(1, 8, (7, 3, 3), stride=1, padding=0) self.conv2 = nn.Conv3d(8, 16, (5, 3, 3), stride=1, padding=0) self.conv3 = nn.Conv3d(16, 32, (3, 3, 3), stride=1, padding=0) self.fc1 = nn.Linear(480896, 256) self.dropout1 = nn.Dropout(p=0.4) self.fc2 = nn.Linear(256, 128) self.dropout2 = nn.Dropout(p=0.4) self.fc3 = nn.Linear(128, class_num) def forward(self, x): out = x.reshape(batch, 30, 25, 25) out = self.conv4(out) out = self.bn1(out) out = F.relu(out) out = out.reshape(batch, 1, 64, 23, 23) out = F.relu(self.conv1(out)) out = F.relu(self.conv2(out)) out = F.relu(self.conv3(out)) out = out.view(-1, 32 * 52 * 17 * 17) out = self.fc1(out) out = F.relu(out) out = self.dropout1(out) out = self.fc2(out) out = F.relu(out) out = self.dropout2(out) out = self.fc3(out) return out
HybridSN准确率 三次实验结果 95.56% 97.05% 98.35% 转为二维+三维 三次实验结果 97.09% 98.38% 98.26%
【第三部分】 论文阅读心得
一、DnCNN
《Beyond a Gaussian Denoiser: Residual Learning of Deep CNN for Image Denoising》,该论文提出了卷积神经网络结合残差学习来进行图像降噪,直接学习图像噪声,可以更好的降噪。
残差学习:拟合H(x),由于网络退化问题难以训练出来,转为训练F(x),F(x)=H(x)-x,F(x)称为残差,然后H(x)=F(x)+x。
DnCNN是将网络的输出直接改成residual image(残差图片),设纯净图片为x,带噪音图片为y,假设y=x+v,则v是残差图片。
即DnCNN的优化目标不是真实图片与网络输出之间的MSE(均方误差),而是真实残差图片与网络输出之间的MSE。
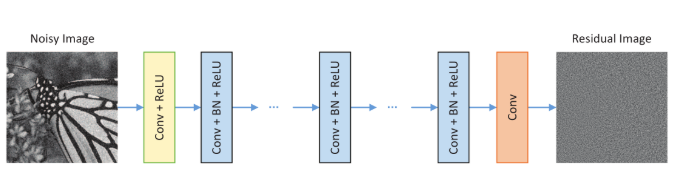
网络结构:
- Conv+ReLU:64个大小为3x3xc的滤波器被用于生成64个特征图。然后将整流的线性单元用于非线性
- Conv+BN+ReLU:64个大小3x3x64的过滤器,并且将批量归一化加在卷积和ReLU之间
- Conv:c个大小为3x3x64的滤波器被用于重建输出。
特征:采用残差学习公式来学习R(y),并结合批量归一化来加速训练以及提高去噪性能
边界伪影:采用0填充的方法解决了边界伪影
二、SENet
CVPR2018的论文《Squeeze-and-Excitation Networks》,国内自动驾驶创业公司 Momenta 在 ImageNet 2017 挑战赛中夺冠,
网络架构为 SENet,论文作者为 Momenta 高级研发工程师胡杰。该网络通过学习的方式获取每个特征通道的重要程度,然后依照这个重要程度去提升有用的特征并抑制对当前任务用处不大的特征。
注意力机制
SE模块首先对卷积得到的特征图进行Squeeze操作,采用global average pooling来实现,然后对全局特征进行Excitation操作,
学习各个channel间的关系,得到不同channel的权重,最后乘以原来的特征图得到最终特征。

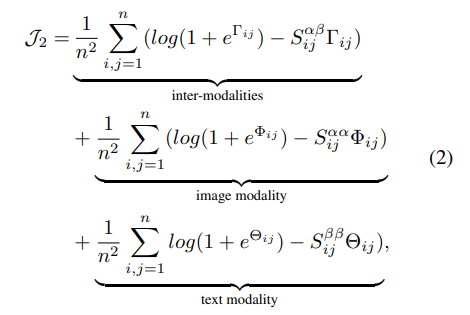
三、DSCMR
DSCMR (Deep Supervised Cross-modal Retrieval)
CVPR2019的论文《Deep Supervised Cross-modal Retrieval》,该论文设计了三个损失函数,用来提升深度跨模态检索的准确率。
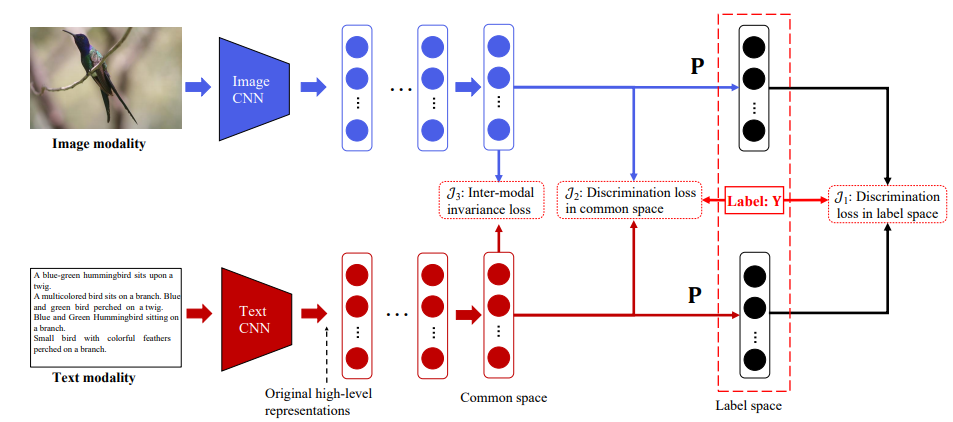
- 对于图像:利用预训练在 ImageNet 的网络提取出图像的 4096 维的特征作为原始的图像高级语义表达。然后后续是几个全连接层,来得到图像在公共空间中的表达。
- 对于文本:利用预训练在 Google News 上的 Word2Vec 模型,来得到 k 维的特征向量。一个句子可以表示为一个矩阵,然后使用一个Text CNN来得到原始的句子高级语义表达。之后也是同样的形式,后面是几个全连接层来得到句子在公共空间中的表达。
三个损失函数
这三个损失函数中去决定性作用的也就只有1、4
的2个函数作用很小