
Watcher 系统整体流程图
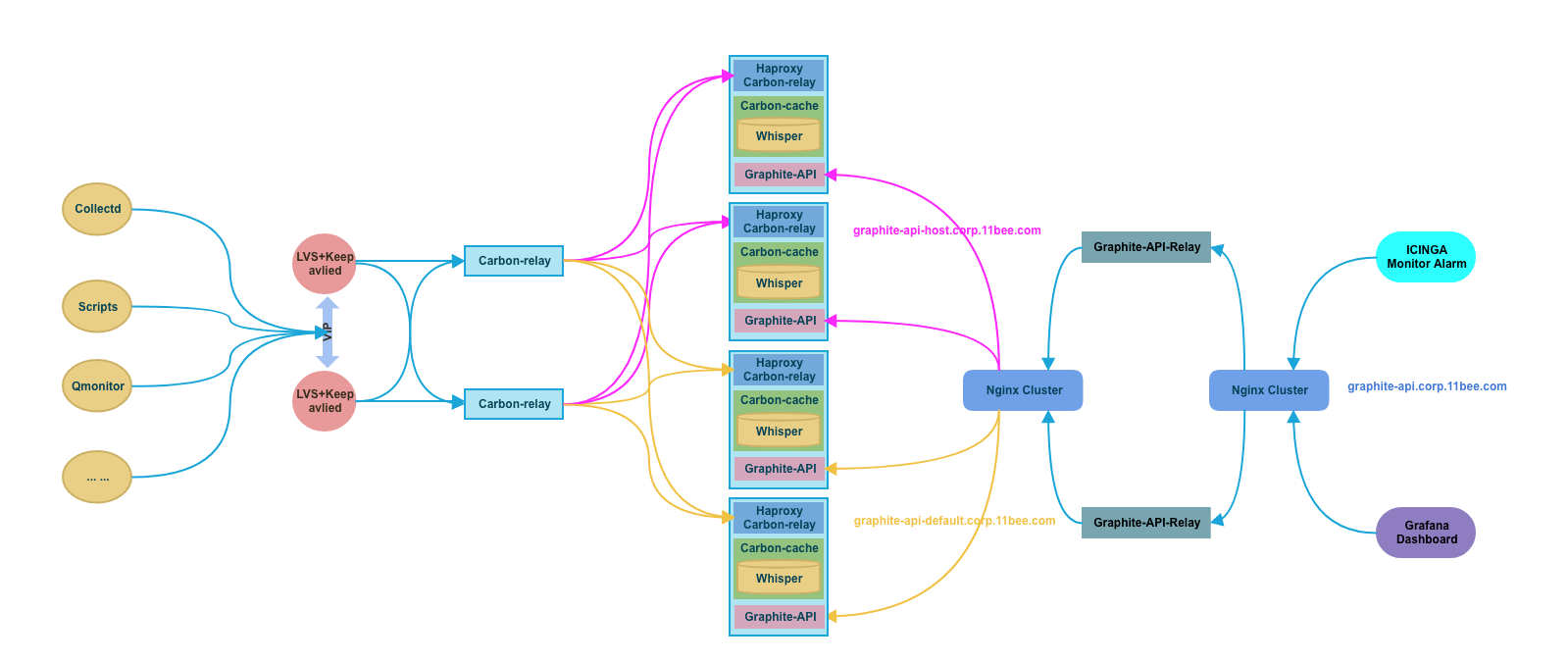
1.收集指标
--------> graphite-backend.xxx.com:2013,2014,2015
--------> lvs+keepalived转发
--------> l-tools[5-6].ops.p1 :2113~5213,2114~5214,2115~5215
/usr/bin/python2 /home/q/graphite/bin/carbon-relay.py start
使用正则表达式来过滤指标并且定义过滤出来的指标要被发送给哪个后端服务器
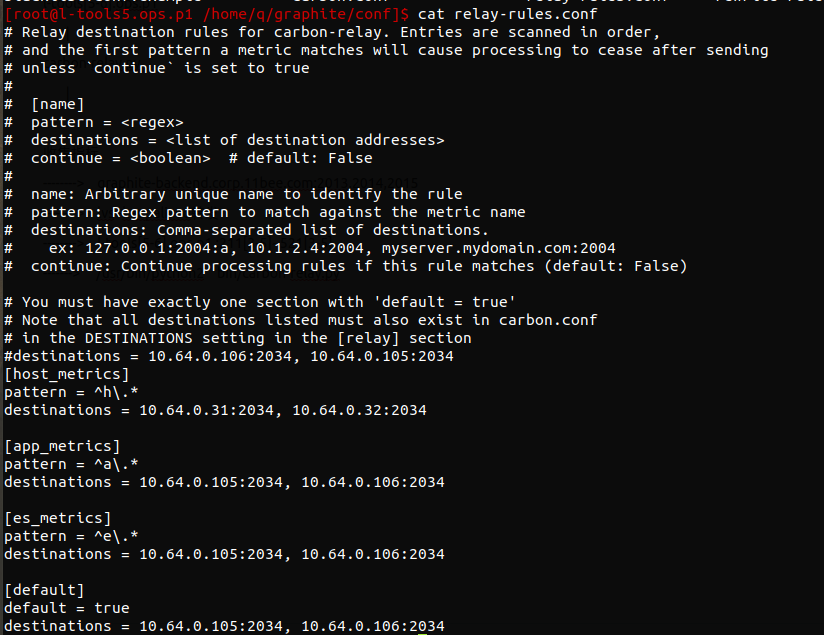
-------> ^h\.* l-nbdata[1-2].db.p1 2034
其他 l-carbon[1-2].ops.p1 2034
haproxy 2014~2714
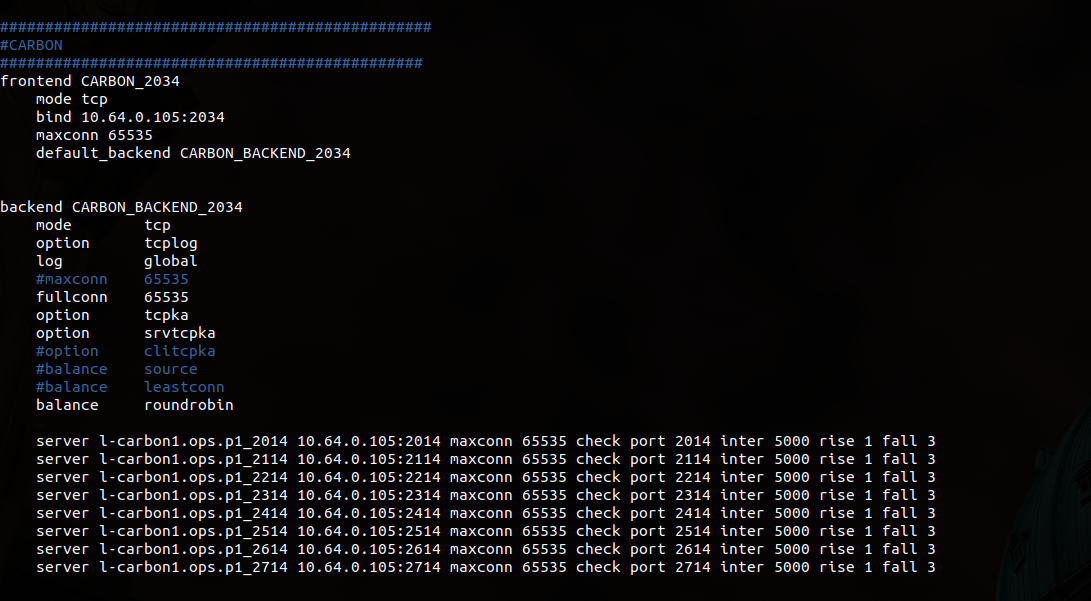
/home/q/graphite/conf/carbon.conf
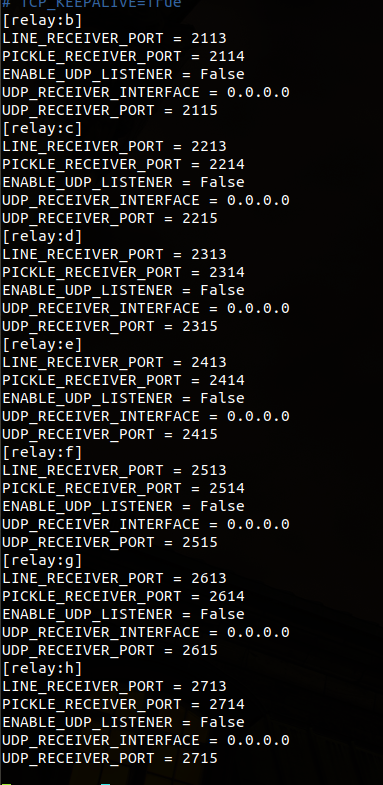
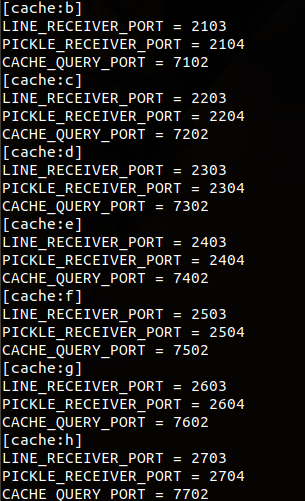
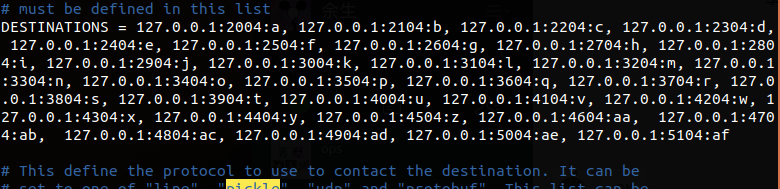
默认为pickle协议。以2114为例,2114--->relay:b--->cache:b--->2104

/usr/bin/python2 /home/q/graphite/bin/carbon-relay.py start
/usr/bin/python2 /home/q/graphite/bin/carbon-cache.py start
whisper文件存储目录 /data1/whisper
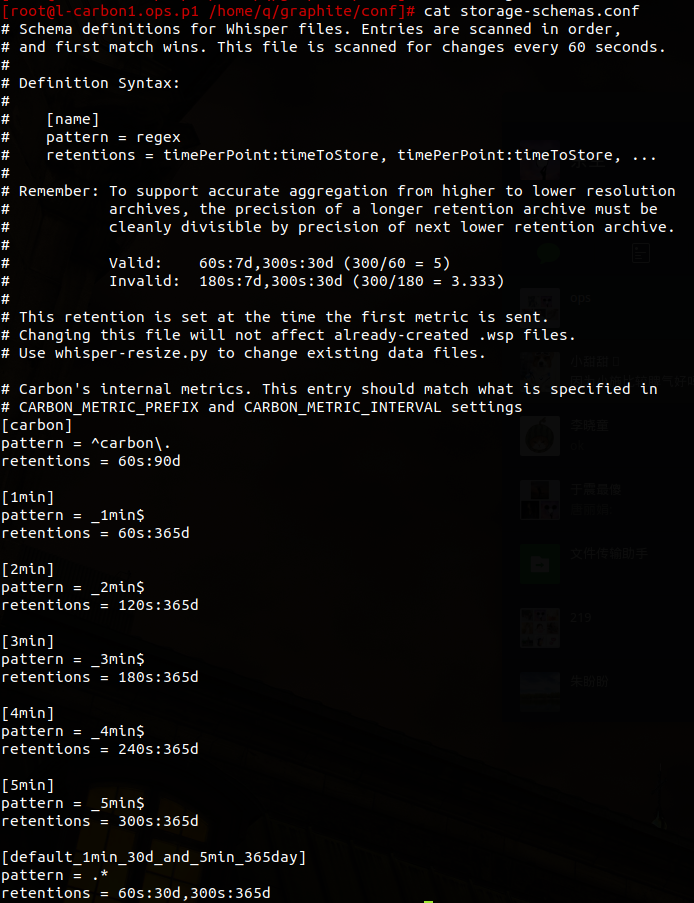
/home/q/graphite/conf/storage-schemas.conf 配置文件详细地定义了数据的采样频率,存储时长以及指标的的匹配规则,Whisper数据库将使用这个配置文件来生成数据库里面的所有数据点,如图
1.这个文件里面可能会有多个section
2.匹配数据的时候,文件里面的section是从上到下顺序遍历的。
3.匹配规则使用的是正则表达式
4.第一个匹配上metrics的名字的规则会被使用。
5.收到第一个metrics的时候设置采样频率
6.改变这个配置文件不会改变已经生成的.wsp文件,使用whisper-resize.py来改变已经生成的文件。
7.规则由三行组成:
名字,定义在方括号里面
正则表达式,定义方式:pattern=xxx
数据采样频率,定义方式:retentions=xxx
采样频率这一项可一定义多个采样频率,使用逗号分隔开( s : 秒,m :分钟,h :小时,d:天,y:年)
设置指标采样频率的一般规则是高精度短时长到低精度长时长– whisper会根据指定的聚合规则(默认是取平均值)对指标进行聚合。
例如:60s:90d 表示采样频率为60秒采样一次,并且保存90天的数据;
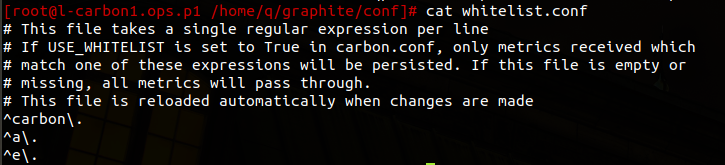
/home/q/graphite/conf/whitelist and blacklist
使用whitelist这个功能可以让carbon daemons只接受白名单里面的指标,拒绝黑名单里面的指标。设置carbon.conf里面的USE_WHITELIST字段可以启用这个功能。当很多指标发送给graphite或者有人发送了很多没有的指标的时候,这个功能会很有用。
Carbon daemon会在GRAPHITE_CONF_DIR路径下搜索whitelist.conf 和 blacklist.conf。配置文件里面的每一行都定义了一个匹配指标的正则表达式。如果whitelist.conf不存在,或者里面的内容是空的,那么所有的指标都会被graphite接受。
2.icinga/grafana拉取指标
--------> graphite-api.xxx.com(l-tools[1-2].ops.p1:8888)(使用配置/etc/graphite-api.yaml)
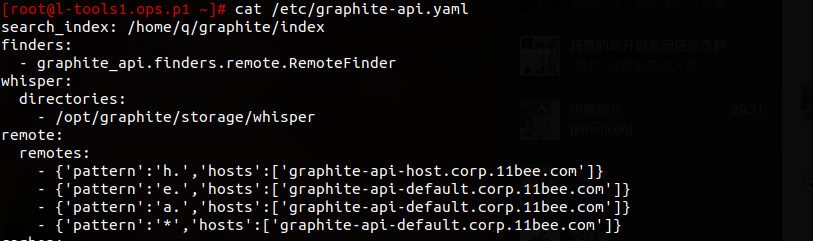
--------> h. graphite-api-host.xxx.com(l-nbdata[1-2].db.p1:8888)
其他 graphite-api-default.xxx.com(l-carbon[1-2].ops.p1 :8888)
配置/etc/graphite-api.yaml
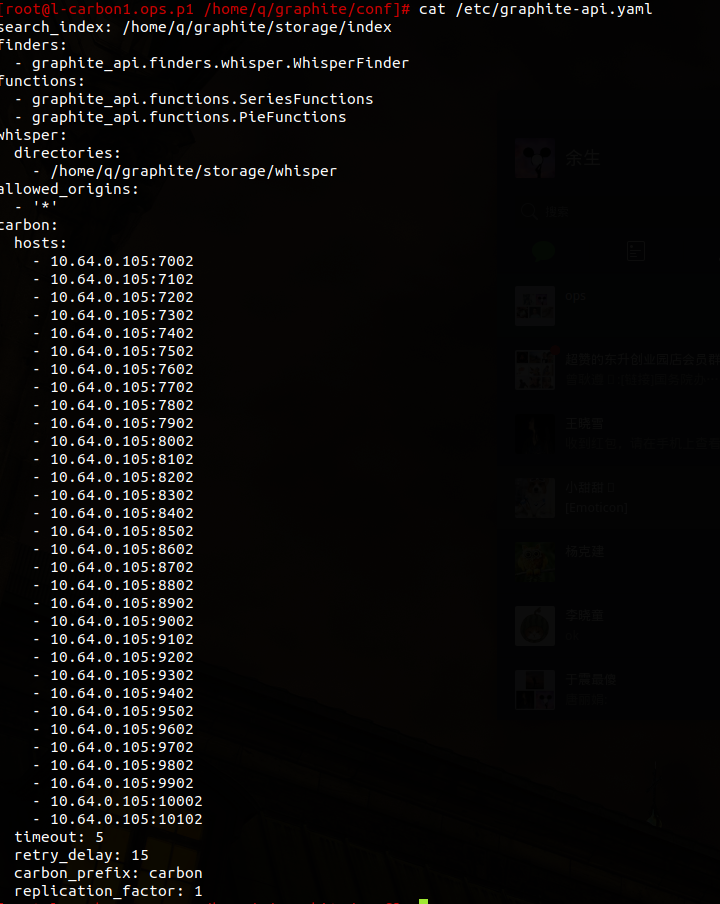
3.配置官方详解
https://graphite.readthedocs.io/en/latest/config-carbon.html
https://graphite-api.readthedocs.io/en/latest/configuration.html#default-values

