201871030139-于泽浩 实验三 结对项目—《D{0-1}KP 实例数据集算法实验平台》项目报告
201871030139-于泽浩 实验三 结对项目—《D{0-1}KP 实例数据集算法实验平台》项目报告
| 项目 | 内容 |
|---|---|
| 课程班级博客链接 | 2018级卓越班 |
| 这个作业要求链接 | 软件工程结对项目 |
| 我的课程学习目标 | (1)体验软件项目开发中的两人合作,练习结对编程(Pair programming)。 (2)掌握Github协作开发程序的操作方法。 (3)使用Python编写D{0-1}KP 实例数据集算法实验平台 |
| 这个作业在哪些方面帮助我实现学习目标 | (1)自学《构建之法》第3-4章内容,学习本次作业相关概念。 (2)结对编程,评价对方《实验二 软件工程个人项目》并学习对方优点。 (3)合作开发设计D{0-1}KP 实例数据集算法实验平台。 (4)查阅资料设计遗传算法解决D{0-1}KP。 |
| 结对方学号-姓名 | 201871030132-熊文婷 |
| 结对方本次博客作业链接 | 熊文婷的博客 |
| 本项目Github的仓库链接地址 | 结对编程仓库 |
任务1:阅读《现代软件工程—构建之法》第3-4章内容,理解并掌握代码风格规范、代码设计规范、代码复审、结对编程概念;
(1)代码风格规范
a.代码风格的原则
代码风格的原则是:简明,易读,无二义性。
b.几种代码风格规范
缩进
-
在学习之前习惯性理解为:对于缩进Tab键是最好的方式,也是最简单的,不用一个空格一个空格的敲,这样的习惯主要是因为大一学习C语言和WEB前端设计养成的。对于Tab键在不同的情况下会显示不同的长度的情况其实在去年学习Linux操作系统的时候用文件编写C语言程序时,就是使用Tab键来规范缩进的,那时很明显Tab键的长度和我之前在Windows系统下写代码时的长度不一样,显示长度为8个空格长度。
是用Tab键好,还是2、4、8个空格?
结论:4个空格,在VS2005和其他的一些编辑工具中都可以定义Tab键扩展成为几个空格键。不用 Tab键的理由是Tab键在不同的情况下会显示不同的长度。4个空格的距离从可读性来说正好。
命名
-
对于命名,最初接触的时候就知道要把程序中的变量、函数等要设计的有意义,然而大多数情况下自己的命名经常图简单用A、B、C...来随意命名,从而导致很多问题,如其他人看不懂你的意义,自己时间久了也不清楚等等一系列影响后续使用修改的问题,这些感受如《构建之法》10.1.6命名所说:
阿超:我在某个同学的程序中看到有些变量叫“lili”,“yunyun”,不知道这些变量在现实生活中有没有什么意义。
下面哄笑起来。
果冻:(红着脸问)那有些变量的确想不出名字,简单的变量像i、j、k都用完了,怎么办?
阿超:当我们的程序比“Hello World”复杂10倍以上的时候,像给变量命名这样简单的事看起来也不那么简单了。我们就来谈谈如何起名字这个问题。程序中的实体、变量是程序员昼思夜想的对象,要起一个好的名字才行。大家都知道用单个字母给有复杂语义的实体命名是不好的,目前最通用的,也是经过了实践检验的方法叫“匈牙利命名法”。例如:
fFileExist,表明是一个bool值,表示文件是否存在;
szPath,表明是一个以0结束的字符串,表示一个路
-
除此之外,有一些地方不适合用“匈牙利命名法”,如文中所说:
在一些强类型的语言(如C#)中,不同类型的值是不能做运算的,对类型有严格的要求,例如C# 中,if()语句只能接受bool值的表达式,这样就大大地防止了以上问题的发生。在这样的语言中,前缀就不是很必要的,匈牙利命名法则不适用了。Microsoft .Net Framework就不主张用这样的法则。
注释
谁不会写注释?但是,需要注释什么?
-
注释问题,个人理解是对所写程序的解释说明,增加了程序可读性。好的代码是自我解释的,然而仍然有大量的设计信息不能用代码表示。例如,只能在代码中正式指定类接口的一小部分,如其方法的签名。接口的非正式方面,例如每个方法的高级描述或其结果的含义,只能在注释中进行描述。还有许多其他的例子无法在代码中描述,比如特定设计决策的基本原理,或者调用特定方法的条件。注释背后的总体思想是捕获设计者头脑中但是不能在代码中表示的信息。这些信息的范围很广,从底层的细节(比如驱动一段特别复杂的代码的硬件怪癖),到高层的概念(比如类的基本原理)。当其他开发人员稍后进行修改时,注释将允许他们更快更准确地工作。
(2)代码设计规范
a.概念
代码设计规范不光是程序书写的格式问题,而且牵涉到程序设计、模块之间的关系、设计模式等方方面面,这里有不少与具体程序设计语言息息相关的内容(如C、C++、Java、C#),但是也有通用的原则,这里主要讨论通用的原则。如果你只想为了“爽”而写程序,那么可以忽略下面的原则;如果你写的程序会被很多人使用,并且你自己会加班Debug 你的程序,那最好还是遵守下面的规定。
b.一些通用的原则
函数
现代程序设计语言中的绝大部分功能,都在程序的函数(Function, Method)中实现,关于函数最重要的原则是:只做一件事,但是要做好。
错误处理
80%的程序代码,都是对各种已经发生和可能发生的错误的处理。
——阿超
如果错误会发生,那就让程序死的地方离错误产生的地方越近越好。
——阿超
-
对于错误处理,个人认为书中“如果你认为某事可能会发生,这时就要用错误处理。”所说很对,在很多时候我们需要提前对这些问题作出处理,如:当有一个程序的运行需要几个小时的时候,我们不可能一直守在电脑前,而当你离开电脑让他自己进行的时候过来很长时间回来发现程序因为一个问题报错停了,可以想象的到是多么的绝望,所以我们一定得在可能要发生问题的地方,提前做出处理如:
…… p = AllocateNewSpace(); // could fail if (p == NULL) { // error handling. } else { // use p to do something }
(3)代码复审
a.概念
代码复审看什么?是不是把你的代码拿给别人看就行了?
(1)别人根本就不懂,给他们讲也是白讲。
(2)我是菜鸟,别的大牛能看得上我的代码么?
(3)也就是形式而已,说归说,怎么做,还是我说了算。
代码复审的正确定义:看代码是否在“代码规范”的框架内正确地解决了问题
-
复审的形式
名 称 形 式 目 的 自我复审 自己 vs. 自己 用同伴复审的标准来要求自己。不一定最有效,因为开发者对自己总是过于自信。如果能持之以恒,则对个人有很大好处 同伴复审 复审者 vs. 开发者 简便易行 团队复审 团队 vs. 开发者 有比较严格的规定和流程,用于关键的代码,以及复审后不再更新的代码。覆盖率高——有很多双眼睛盯着程序。但是有可能效率不高(全体人员都要到会)
b.复审目的
(1)找出代码的错误。如:
a. 编码错误,比如一些能碰巧骗过编译器的错误。
b. 不符合项目组的代码规范的地方。
(2)发现逻辑错误,程序可以编译通过,但是代码的逻辑是错的。
(3)发现算法错误,比如使用的算法不够优化。
(4)发现潜在的错误和回归性错误——当前的修改导致以前修复的缺陷又重新出现。
(5)发现可能改进的地方。
(6)教育(互相教育)开发人员,传授经验,让更多的成员熟悉项目各部分的代码,同时熟悉和应用领域相关的实际知识。
c.为什么复审
- 首先,在代码复审中发现的问题,绝大多数都可以由开发者独立发现。从这一意义上说,复审者是在替开发者干开发者本应干的事情。即使是完美,代码复审还有“教育”和“传播知识”的作用。更重要的是,不管多么厉害的开发者都会或多或少地犯一些错误,有欠考虑的地方,如果有问题的代码已签入到产品代码中,再要把所有的问题找出来就更困难了。大家学习软件工程都知道越是项目后期发现的问题,修复的代价越大。代码复审正是要在早期发现,并修复这些问题。
- 另外,在代码复审中的提问与回应能帮助团队成员互相了解,就像练武之人互相观摩点评一样。在一个新成员加入一个团队的时候,代码复审能非常有效地帮助新成员了解团队的开发策略、编程风格及工作流程。
注:关于代码复审的步骤等其他知识将在任务2中对结对对象的实验二申评中体现所学。
(4)结对编程
a.概念
在结对编程模式下,一对程序员肩并肩地、平等地、互补地进行开发工作。两个程序员并排坐在一台电脑前,面对同一个显示器,使用同一个键盘,同一个鼠标一起工作。他们一起分析,一起设计,一起写测试用例,一起编码,一起单元测试,一起集成测试,一起写文档等。
结对编程不是程序开发者独到的发明,在现实生活中,也存在着类似的搭档关系(Partnership):
越野赛车(驾驶,领航员)
驾驶飞机(驾驶,副驾驶)
战斗机的编组(长机,僚机)
提示:这些任务都有共同点:在高速度中完成任务,任务有较高的技术要求,任务失败的代价很高。
b.为什么要结对编程
-
每人在各自独立设计、实现软件的过程中不免要犯这样那样的错误。在结对编程中,因为有随时的复审和交流,程序各方面的质量取决于一对程序员中各方面水平较高的那一位。这样,程序中的错误就会少得多,程序的初始质量会高很多,这样会省下很多以后修改、测试的时间。具体地说,结对编程有如下的好处:
(1)在开发层次,结对编程能提供更好的设计质量和代码质量,两人合作能有更强的解决问题的能力。
(2)对开发人员自身来说,结对工作能带来更多的信心,高质量的产出能带来更高的满足感。
(3)在心理上, 当有另一个人在你身边和你紧密配合, 做同样一件事情的时候, 你不好意思开小差, 也不好意思糊弄。
(4)在企业管理层次上,结对能更有效地交流,相互学习和传递经验,能更好地处理人员流动。因为一个人的知识已经被其他人共享。
总之,如果运用得当,结对编程能得到更高的投入产出比(Return of Investment)。
c.如何结对编程
-
书中以驾驶员和领航员为例有如下几点:
(1)驾驶员:写设计文档,进行编码和单元测试等XP开发流程。
(2)领航员:审阅驾驶员的文档、驾驶员对编码等开发流程的执行;考虑单元测试的覆盖程度;是否需要和如何重构;帮助驾驶员解决具体的技术问题。
(3)驾驶员和领航员不断轮换角色,不宜连续工作超过一小时。领航员要控制时间。
(4)主动参与。任何一个任务都首先是两个人的责任,也是所有人的责任。没有“我的代码”、“你的代码”或“她的代码”,只有“我们的代码”。
(5)只有水平上的差距,没有级别上的差异。尽管可能大家的级别资历不同,但不管在分析、设计或编码上,双方都拥有平等的决策权利。
注:结对编程是个渐进的过程,在学习本门可之前虽然没有听过结对编程的概念,也没有很全面的专门去了解结对编程,但在实际的学习过程中,我们不仅存在两人的结对合作,也经历多5~7人小组合作,这些都为这次的结对编程打下一定基础。真的如书中舞蹈版解释存在萌芽、磨合、规范、创造以及解体各个阶段。
d.两人的合作——如何影响对方
两人在一起合作,自然会出现不同意见,每个人都有自己的想法,在两个人平等合作的情况下,不存在领导与被领导的关系,如何能说服对方?要听对方的话语和观察对方的肢体语言,了解它们所表示的潜台词,试着从对方的角度看待问题。同时也要根据情况采取不同的方法影响别人,有以下几种方式,如表所示:
| 方式 | 简介 | 逻辑/感情 | 推/拉 | 注解 |
|---|---|---|---|---|
| 断言(Assertion) | 就是这样吧,听我的,没错! | 感情 | 推——主动推动同伴做某事 | 感情很强烈,适用于有充分信任的同伴。语音、语调、肢体语言都能帮助传递强烈的信息 |
| 桥梁(Bridge) | 能不能再给我讲讲你的理由…… | 逻辑 | 拉——吸引对方,建立共识 | 给双方充分条件互相了解 |
| 说服(Persuasion) | 如果我们这样做,根据我的分析,我们会有这样的好处,a、 b、 c…… | 逻辑 | 推——让对方思考 | 有条理,建立在逻辑分析的基础上。即使不能全部说服,对方也可能接受部分意见 |
| 吸引(Attraction) | 你想过舒适的生活么?你想在家里发财么?加入我们的传销队伍吧,几个月后就可以有上万元的收入…… | 感情 | 拉——描述理想状态,吸引对方加入 | 可以有效地传递信息,但是要注意信息的准确性。夸大的渲染会降低个人的可信度 |
任务2:两两自由结对,对结对方《实验二 软件工程个人项目》的项目成果进行评价,具体要求如下:
(1)对项目博文作业进行阅读并进行评论,评论要点包括:博文结构、博文内容、博文结构与PSP中“任务内容”列的关系、PSP中“计划共完成需要的时间”与“实际完成需要的时间”两列数据的差异化分析与原因探究,将以上评论内容发布到博客评论区。
(2)克隆结对方项目源码到本地机器,阅读并测试运行代码,参照《现代软件工程—构建之法》4.4.3节核查表复审同伴项目代码并记录。
(3)依据复审结果尝试利用github的Fork、Clone、Push、Pull request、Merge pull request等操作对同伴个人项目仓库的源码进行合作修改。
(1)代码复审核查表
b.对结对方的博文进行阅读和评论
-
结对对象
熊文婷
-
评论内容
-
结构方面
首先,任务1以表格形式体现就给人眼前一亮的感觉,前面看了自己以及其他一些同学的实验2的博客内容,基本都是使用列表形式展现,并没有表格展现形式清晰明了,层次分明和对比显著。
而后,其他的任务内容排版也是条理清晰,点点分明,加上淡雅的背景让人读起来是感到舒服的。尤其是图文结合使得阅读体验升华,更易于理解博客内容,这些都值得我们去学习。
-
内容方面
首先,针对任务1熊文婷的评论不仅有优缺点评论,也对一些问题提了一些建议,这是很好的一点,知识的学习是在不断的交流中进步的,而建议是交流很好的开始,宜于让大家展开思考。
其次,针对任务2熊文婷的SPS文档计划完成学业的时间一般情况都比实际完成需要的时间久,尤其是在编写代码的过程,可见其在代码编写方面存在一些问题,值得下来总结经验提升自己。不过虽然实践实践缓慢但可以看出她的认真对待,值得鼓励给予肯定。
最后,针对任务3除了图文结合的展现形式,其有一点参考文献的列出从另一方面展现了她学习的过程,充分利用资源来解决实践面临的问题。而实验的总结中也体现出她学习过程的阶段,不断学习不断反思同时也不断进步着。
-
-
博客评论区截图
(2)克隆结对方项目源码到本地机器,阅读并测试运行代码
结对方姓名:熊文婷
结对方Github的仓库链接:熊文婷的实验2仓库
| 复审部分 | 提出问题 | 执行情况 |
|---|---|---|
| 概要部分 | 1)代码符合需求和规格说明么? 2)代码设计是否考虑周全? 3)代码可读性如何? 4)代码容易维护么? 5)代码的每一行都执行并检查过了吗? |
1)代码部分层次分明,以函数为模块功能明确,代码注释清晰详细; 2)代码部分层次分明,所以在代码维护方面比较容易,各个函数也容易理解; 3)代码的可读性很好,命名规范、注释详细; 4)由于各个功能明确独立,故代码容易维护; 5)每一行代码都执行检查,确认无误,执行正常; |
| 设计规范部分 | 1)设计是否遵从已知的设计模式或项目中常用的模式? 2)有没有硬编码或字符串/数字等存在? 3)代码有没有依赖于某一平台,是否会影响将来的移植(如Win32到 Win64 ) ? 4)开发者新写的代码能否用已有的Library/SDK/Framework中的功能实现?在本项目中是否存在类似的功能可以调用而不用全部重新实现? 5)有没有无用的代码可以清除? |
1)设计遵从常用模式; 2)合理运用函数模块化,也存在有字符串和数字; 3)代码没有依赖于某一平台,不会会影响将来的移植 ; 4)没有无用代码; |
| 代码规范部分 | 修改的部分符合代码标准和风格吗? | 修改的部分符合代码标准和风格 |
| 具体代码部分 | 1)有没有对错误进行处理?对于调用的外部函数,是否检查了返回值或处理了异常? 2)参数传递有无错误,字符串的长度是字节的长度还是字符(可能是单/双字节)的长度,是以0开始计数还是以1开始计数? 3)边界条件是如何处理的?switch语句的default分支是如何处理的?循环有没有可能出现死循环? 4)有没有使用断言(Assert)来保证我们认为不变的条件真的得到满足? 5)对资源的利用,是在哪里申请,在哪里释放的?有无可能存在资源泄漏(内存、文件、各种GUI资源、数据库访问的连接,等等)?有没有优化的空间? 6)数据结构中有没有用不到的元素? |
1)开发者多次上传,对错误进行了处理,不断完善自己的程序; 2)参数传递无错误,字符串的长度是以0开始计数 ; 3)程序执行过程中没有出现循环死循环问题; 4)两个算法的实现优化了解决问题的空间; 5)数据结构中没有用不到的元素; |
| 效能 | 1)代码的效能( Performance )如何?最坏的情况是怎样的? 2)代码中,特别是循环中是否有明显可优化的部分(C++中反复创建类,C# 中 string的操作是否能用StringBuilder来优化)? 3)对于系统和网络的调用是否会超时?如何处理? |
1)代码的效能很好,最坏的情况是执行时间过程(在使用回溯算法时); 2)对于系统和网络的调用可能会超时,因为在运用回溯算法的时候耗时较长,算法本身问题,建议优化算法; |
| 可读性 | 代码可读性如何?有没有足够的注释? | 1)代码可读性很好; 2)有足够的注释; |
| 可测试性 | 代码是否需要更新或创建新的单元测试? | 不需要; |
-- 引用《现代软件工程—构建之法》4.4.3 代码复审的核查表(P82)
任务3:采用两人结对编程方式,设计开发一款D{0-1}KP 实例数据集算法实验平台,使之具有以下功能:
(1)平台基础功能:实验二 任务3;
(2)D{0-1}KP 实例数据集需存储在数据库;
(3)平台可动态嵌入任何一个有效的D{0-1}KP 实例求解算法,并保存算法实验日志数据;
(4)人机交互界面要求为GUI界面(WEB页面、APP页面都可);
(5)查阅资料,设计遗传算法求解D{0-1}KP,并利用此算法测试要求(3);
(6)附加功能:除(1)-(5)外的任意有效平台功能实现。
需求分析陈述
- 目前,求解折扣{0-1}背 包 问 题(D{0-1}KP)的主要算法是基于动态规划的具有伪多项式时间的确定性算法,当D{0-1}KP实例中各项的价值系数与重量系数在大范围内取值时缺乏实用性。折扣{0-1}背包问题(Discounted {0-1} Knapsack Problem,D{0-1}KP)是比0-1背包还要难以求解的NP-hard问题。提出了一种求解D{0-1}KP的新遗传算法GADKP。
(1)平台基础功能:实验二 任务3
- 实验二任务3的链接:以熊文婷的为主要实现基础。
(2)D{0-1}KP 实例数据集需存储在数据库
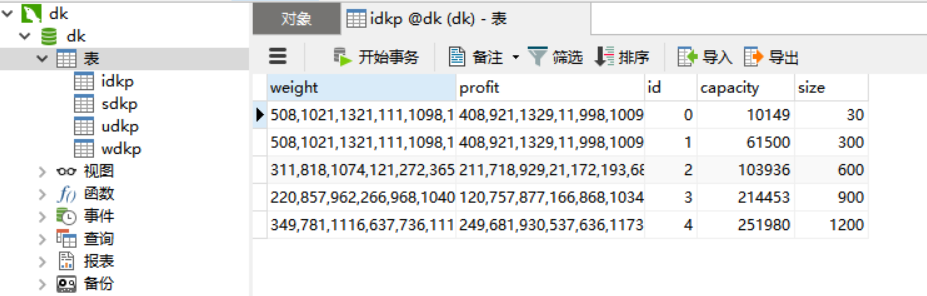
- 利用MySQL软件与Python数据库连接,将实验二的数据集中的一部分加入数据库,如图所示。
![img]()
数据库连接
config = {
'host': 'localhost',
'port': 3307,
'user': 'root',
'password': '815490',
'db': 'dk',
'charset': 'utf8',
'cursorclass': pymysql.cursors.DictCursor,
}
connection = pymysql.connect(**config)
connection.autocommit(True)
cursor = connection.cursor()
def get_table_list():
results=[]
cursor.execute('show tables from dk;')
query_result = cursor.fetchall()
for i in query_result:
results.append(i['Tables_in_dk'])
return results
def get_data(sets_name):
sql='select * from '+sets_name+';'
cursor.execute(sql)
query_result = cursor.fetchall()
return query_result
(3)平台可动态嵌入任何一个有效的D{0-1}KP 实例求解算法,并保存算法实验日志数据
在实验二的基础上,加入实验日志数据,文件命名为“月-日-年.txt”,如图所示。

回溯算法并剪枝
def bound(self, k, caup): # 计算上界函数,功能为剪枝
ans = self.val
while k < self.size and caup >= self.items[k].pack[2].weight:
caup -= self.items[k].pack[2].weight
ans += self.items[k].pack[2].profit
k += 1
if k < self.size:
ans += self.items[k].pack[2].profit / self.items[k].pack[2].weight * caup
return ans
def Backtracking(self, k, i, caup): # 回溯算法
bound_val = self.bound(k + 2, caup)
if k == self.size - 1:
if self.max_val < self.val:
self.max_val = self.val
self.so_res = list.copy(self.so_tmp)
return
for j in range(3):
if caup >= self.items[k + 1].pack[j].weight:
self.val += self.items[k + 1].pack[j].profit
self.so_tmp.append((k + 1, j))
self.Backtracking(k + 1, j, caup - self.items[k + 1].pack[j].weight)
self.so_tmp.pop()
self.val -= self.items[k + 1].pack[j].profit
if bound_val > self.max_val:
self.Backtracking(k + 1, j, caup)
动态规划算法
def DP(self): # 动态规划算法
dp = [[[0 for k in range(self.cubage + 5)] for i in range(4)] for j in range(self.size + 5)] # 三维dp数组
for k in range(1, self.size + 1):
for i in range(1, 4):
for v in range(self.cubage + 1):
for j in range(1, 4):
dp[k][i][v] = max(dp[k][i][v], dp[k - 1][j][v])
if v >= self.items[k - 1].pack[i - 1].weight:
dp[k][i][v] = max(dp[k][i][v],dp[k - 1][j][v - self.items[k - 1].pack[i - 1].weight]+self.items[k - 1].pack[i - 1].profit)
self.max_val = max(self.max_val, dp[k][i][v])
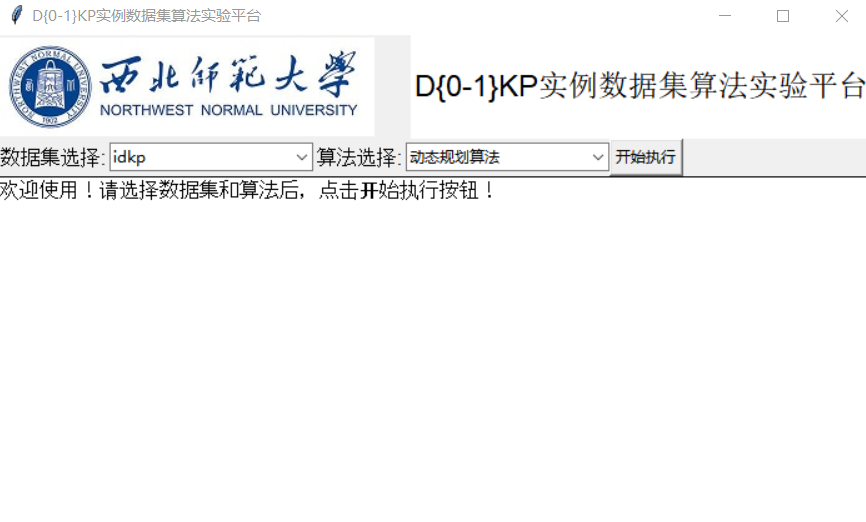
(4)人机交互界面要求为GUI界面(WEB页面、APP页面都可)
- 利用python自带框架tkinter绘制GUI界面,如图所示。
![img]()
(5)查阅资料,设计遗传算法求解D{0-1}KP,并利用此算法测试要求(3)
-
参考文献:
- [1]吴聪聪,贺毅朝,赵建立.求解折扣{0-1}背包问题的新遗传算法[J].计算机工程与应用,2020,56(07):57-66.
- [2]杨洋,潘大志,刘益,谭代伦.折扣{0-1}背包问题的简化新模型及遗传算法求解[J].计算机应用,2019,39(03):656-662.
遗传算法伪代码,如下图所示。
![img]()
-
遗传算法代码
class GAType(): # 种群 def __init__(self, obj_count): self.gene = [0 for x in range(0, obj_count, 1)] # 序列编码 0 / 1 self.fitness = 0 # 适应度 self.cho_feq = 0 # choose 选择概率 self.cum_feq = 0 # cumulative 累积概率 class genetic(): def __init__(self, value, weight, max_weight): self.value = value self.weight = weight self.max_weight = max_weight self.obj_count = len(weight) self._gatype = [GAType(self.obj_count) for x in range(0, population_size, 1)] self.total_fitness = 0 def avoid_zero(self): '''防止遗传的下一代为全零,若为全零,则将随机的位数置1''' flag = 0 for i in range(0, population_size, 1): res = [] for j in range(0, self.obj_count, 1): res.append(self._gatype[i].gene[j]) if [0 for x in range(0, self.obj_count, 1)] == res: # 全零 # print('找到了全零的状态!') flag = 1 set_one = random.randint(1,self.obj_count) for k in range(0,set_one,1): idx = random.randint(0,self.obj_count-1) self._gatype[i].gene[idx] = 1 # print(self._gatype[i].gene) return True if flag else False def initialize(self): '''初始化种群''' for i in range(0, population_size, 1): while (1): # 保证不全为零 res = [] for j in range(0, self.obj_count, 1): self._gatype[i].gene[j] = random.randint(0,1) res.append(self._gatype[i].gene[j]) if [0 for x in range(0, self.obj_count, 1)] != res: break def envaluateFitness(self): '''适应度评估 = 背包内装入物品的总价值,如果超出max_weight,则置1(惩罚性措施)''' self.total_fitness = 0 # 每次计算时,先将总数置0 for i in range(0, population_size, 1): max_w = 0 self._gatype[i].fitness = 0 # 置0后再计算 for j in range(0, self.obj_count, 1): if self._gatype[i].gene[j] == 1: self._gatype[i].fitness += self.value[j] # 适应度 max_w += self.weight[j] # 最大重量限制 if max_w > self.max_weight: self._gatype[i].fitness = 1 # 惩罚性措施 if 0 == self._gatype[i].fitness: # 出现了全零的种群 self.avoid_zero() i = i - 1 # 重新计算该种群的fitness else: self.total_fitness += self._gatype[i].fitness # 种群的所有适应度 if 0 == self.total_fitness: print('total_fitness = 0 ') def select(self): '''采用选择概率和累积概率来做选择,得出下一代种群(个数不变) 对环境适应度高的个体,后代多,反之后代少,最后只剩下强者''' last_cho_feq = 0 for i in range(0, population_size, 1): try: self._gatype[i].cho_feq = self._gatype[i].fitness / float(self.total_fitness) # 选择概率 except: # print('error', self.total_fitness) pass self._gatype[i].cum_feq = last_cho_feq + self._gatype[i].cho_feq # 累积概率 last_cho_feq = self._gatype[i].cum_feq # _next = deepcopy(self._gatype) # 下一代种群,参与到后续的交叉和变异 _next = [GAType(self.obj_count) for x in range(0, population_size, 1)] for i in range(0, population_size, 1): choose_standard = random.randint(1, 100) / 100.0 # print('choose_standard: %f' % choose_standard) if choose_standard < self._gatype[0].cum_feq: # 选出下一代种群 _next[i] = self._gatype[0] else: for j in range(1, population_size, 1): if self._gatype[j-1].cum_feq <= choose_standard < self._gatype[j].cum_feq: _next[i] = self._gatype[j] self._gatype = deepcopy(_next) self.avoid_zero() # 全零是不可避免的?? def crossover(self): '''采用交叉概率p_cross进行控制,从所有种群中,选择出两个种群,进行交叉互换''' first = -1 for i in range(0, population_size, 1): choose_standard = random.randint(1, 100) / 100.0 if choose_standard <= p_cross: # 选出两个需要交叉的种群 if first < 0: first = i else: self.exchangeOver(first, i) first = -1 def exchangeOver(self,first,second): '''交叉互换''' exchange_num = random.randint(1, self.obj_count) # 需要交换的位置数量 # print(exchange_num) for i in range(0, exchange_num, 1): idx = random.randint(0, self.obj_count - 1) self._gatype[first].gene[idx], self._gatype[second].gene[idx] = \ self._gatype[second].gene[idx], self._gatype[first].gene[idx] def mutation(self): '''随机数小于变异概率时,触发变异''' for i in range(0, population_size, 1): choose_standard = random.randint(1, 100) / 100.0 if choose_standard <= p_mutation: # 选出需要变异的种群 self.reverseGene(i) def reverseGene(self, index): '''变异,将0置1,将1置0''' reverse_num = random.randint(1, self.obj_count) # 需要变异的位置数量 for i in range(0, reverse_num, 1): idx = random.randint(0, self.obj_count - 1) self._gatype[index].gene[idx] = 1 - self._gatype[index].gene[idx] def genetic_result(self): cnt = 0 while (1): cnt = cnt + 1 if cnt > 100: break self.initialize() self.envaluateFitness() for i in range(0, max_generations, 1): self.select() self.crossover() self.mutation() self.envaluateFitness() if True == self.is_optimal_solution(self._gatype, opt_result): #print('循环的次数为:%d' % cnt) break self.show_res(self._gatype) def is_optimal_solution(self, gatype0, opt_result): '''判断是否达到了最优解''' for i in range(0, population_size, 1): res_list = [] for j in range(0, self.obj_count, 1): res_list.append(gatype0[i].gene[j]) if opt_result == res_list: return True return False def show_res(self, gatype0): '''显示所有种群的取值''' res = [] res_list = [] for i in range(0, population_size, 1): #print('种群:%d --- ' % i), list0 = [] for j in range(0, self.obj_count, 1): list0.append(gatype0[i].gene[j]) #print(gatype0[i].gene[j]), #print(' --- 总价值:%d' % gatype0[i].fitness) res.append(gatype0[i].fitness) res_list.append(list0) # max_index = 0 for i in range(0, len(res), 1): if res[max_index] < res[i]: max_index = i weight_all = 0 for j in range(0, self.obj_count, 1): if gatype0[max_index].gene[j] == 1: weight_all += self.weight[j] print('当前算法的最优解(种群%d):' % max_index), print(res_list[max_index]), print('总重量(不超过%d):' % self.max_weight), print(weight_all), print('总价值:'), print(res[max_index]) if __name__ == '__main__': f = open("idkp1-10.txt",'r+') #打开文件 print("请输入你要处理的数据为第几组:") group = int(input()) lnum = 0 for line in f: #按行读取 lnum += 1 if(lnum == 4 + group * 8): #获取物品数量n s = line.strip().split(' ') n = str(s[3]) n = n.strip().split('d=3*') n = str(n[1]) n = n.strip().split(',') n = 3* int(n[0]) print("物品数量 n = :",n) #获取背包容量c c = str(s[-1]) c = c.strip().split('.') c = int(c[0]) print("背包容量 c = :",c) #获取各个物品价值存入V中 if(lnum == 6 + group * 8): V = line.strip().split(',') Vv = V[-1].split('.') V[-1] = Vv[0] #print("物品价值 V = :",V) #获取各个物品重量存入W中 if(lnum == 8 + group * 8): W = line.strip().split(',') Ww = W[-1].split('.') W[-1] = Ww[0] #print("物品重量 W = ",W) X = [] #物品重量 weight = [] Y = [] #物品价值 value = [] for i in range(n): X = int(W[i]) weight.append(X) Y = int(V[i]) value.append(Y) #print(value) max_weight = c opt_result = [] for i in range(n): p = random.randint(0,1) opt_result.append(p) print("opt_result = ",opt_result) population_size = n # 种群 max_generations = 50 # 进化代数 p_cross = 0.8 # 交叉概率 p_mutation = 0.15 # 变异概率 #用户能够自主选择动态规划算法、回溯算法求解指定D{0-1} KP数据的最优解和求解时间(以秒为单位) print("动态规划算法:") start = time.time() value1 = [[0 for j in range(c + 1)] for i in range(n + 1)] for i in range(1, n + 1): for j in range(1, c + 1): if j < weight[i - 1]: value1[i][j] = value1[i - 1][j] else: value1[i][j] = max(value1[i - 1][j], value1[i - 1][j - weight[i - 1]] + value[i - 1]) print('\n最大价值为:', value1[n][c]) x = [0 for i in range(n)] j = c for i in range(n, 0, -1): if value1[i][j] > value1[i - 1][j]: x[i - 1] = 1 j -= weight[i - 1] print('背包中所装物品为:') for i in range(n): if x[i]: print('第', i+1, '个,', end='') end = time.time() print("\n循环运行时间:%.2f秒"%(end-start)) print("\n遗传算法:\n") genetic(value, weight, max_weight).genetic_result() -
运行结果(错误)


- 注:在遗传算法解决问题过程中出现了问题,使得结果不正确,经过团队讨论研究仍然没有发现问题原因,有待后续继续研究。
(6)附加功能:除(1)-(5)外的任意有效平台功能实现
在问题(1)-(5)外的问题中,我们实现的其他功能有:
- 计算不同算法运行的时间
- 优化实验二中文件读取的功能
(7)结对PSP
| 任务内容 | 计划共完成的时间(min) | 实际完成时间(min) |
|---|---|---|
| 计划 | 30 | 40 |
| 结对成员认识 | 10 | 8 |
| 任务分工及初步讨论 | 20 | 32 |
| 开发(预计三天完成) | 490 | 590 |
| 图形用户界面设计 | 30 | 30 |
| 数据库设计 | 60 | 60 |
| 实验二代码修改 | 130 | 140 |
| 代码更改 | 120 | 170 |
| 遗产算法(查看资料) | 60 | 60 |
| 遗传算法传算法(伪代码编写) | 90 | 130 |
| 报告 | 155 | 230 |
| 阅读《构建之法》 | 80 | 100 |
| 博客园编写 | 60 | 100 |
| 反思及总结 | 15 | 30 |
任务4:完成结对项目报告博文作业
-
博客编写
![]()

总结
-
相对于实验2的个人项目,我更喜欢实验3的结对编程,不是为了偷懒而是在合作中学到更多的知识,发现自己的问题,看到对方的优点。这次实验的结对对象为:熊文婷,我们的合作已经不是第一次,从第一次合作都现在,她都给我一种靠谱的感觉,面对问题不搞定不罢休。在此次实验中我们确实也遇见了很多问题,想我们不熟悉的遗传算法和之前没有学会的GUI界面(主要是使用Python并连接数据库)等等,不过我们已经分析问题、分工合作完成本次实验,下面将给出我们的结对学习过程:
-
分工合作表
成员姓名 讨论日期 所做内容 熊文婷 2021.4.9 通过中国知网、万方等网站查找关于遗传算法资料 于泽浩 2021.4.10 设计GUI界面 熊文婷 2021.4.10 修改实验二代码,在此基础上为创建图形用户界面、连接数据库做准备 于泽浩 2021.4.11 设计遗传算法伪代码 熊文婷、于泽浩 2021.4.12 积极讨论在单人工作期间遇到的问题,展示这段时间的实验成果并且共同解决 熊文婷、于泽浩 2021.4.13 同上 注:在单人工作时会遇到很多意外,比如数据库软件下载有问题、数据库连接不上、设计的界面没有达到预期的目标等等,但是当两人见面后将彼此的问题告诉对方时,不仅仅可以获得建议还能互相学习,共同进步。
-
合作过程照片
-
设计页面(手绘初版)
![img]()
![]()
-
界面设计(编码实现)
![img]()
-
界面设计讨论过程
![img]()
![img]()
-
遗传算法学习过程
![img]()
![img]()
-
-





感悟:“1+1=2”是数学上的结果,而合作却可以实现“1+1>2”的成果。学习的过程是思想的火花不断碰撞的过程,在这次活动中我们收获的不仅是一个实验所需学习的知识内容,更多的是为以后学习生活在不断打下基础,未来我们会遇见更多的问题需要更多的人来合作完成,而现在的过程就是提升自己IQ和EQ的过程,相互监督共同进步。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号