


弗斯特
最近开始重新研究下已经“抛弃”一段时间的数据挖掘算法了,也重新回到了“抛弃”了快一年的博客,现在回头看一下感慨还是很多的,首先自己学到的很多新的想法还是要记录下来的,其次我们总是想着做某些事情的时候使用“单线程”,这本身没错可是却忽视了在社会上我们都不可能只擅长一件事情,我们还需要去拓展自己的多方面的能力。因此,这也是我重新开始机器学习步伐的原因,闲话少述,开始进入正题。
- 导论
决策树估计很多人都知道实现原理,网上分析的一大堆,可是自己仔细看过很多文章不是太简单就是太复杂,不是堆砌一堆公式就是一坨图片,本文是想从决策树的基本原理来切入。首先举个栗子:
我们在买西瓜的时候一般会通过一些依据来判断是否是好瓜,比如颜色、根蒂、色泽、敲击声音等,最后得出结论,决策过程如下图所示:
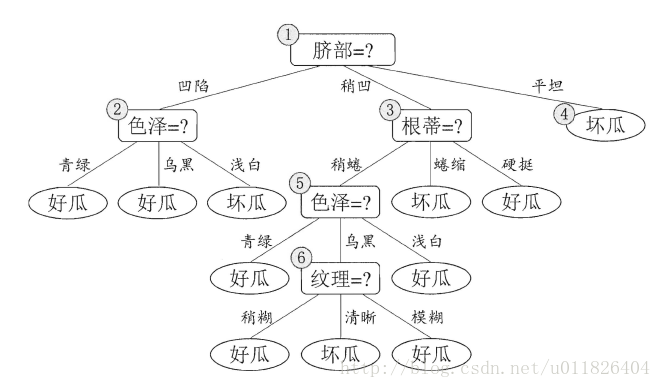
图一
决策的过程最终结论对应了我们的判定结果--是不是好瓜,决策过程中提出一个或者多个(通常是多个)的判断标准作为判定依据,这些判断标准(其实就是样本对象的属性)一般存在着“串行”的联系,从最后生成的“树”来分析的话树的每个节点(除了根节点和叶节点以外的)都属于样本对象的一个属性,而节点分布的上下顺序决定了属性的重要程度。
TreeGenerate(D,A): //构造决策树的函数
生成节点node //表示根节点
if D中样本全属于同一类别C: //样本属于一类的情况
将node标记为C类叶节点
return
end if
if 属性集A为空或者D的所有属性值均一样:
将node标记为最多类
return
end if
从A中选取最佳划分属性a* //决策树的属性选择顺序这里是疑点1
for a in a*:
为node生成一个分支,
令Dv表示D中在a*属性值为a*v的样本子集
if Dv为空:
continue;
else:
TreeGenerate(Dv,A\{a*})递归继续
end if
end for
图二
从以上伪代码我们可以得到以下几个结论以及疑点:1、决策树的生成是一个递归的过程;
2、决策树分类的过程中最佳属性的选取有何依据?
3、确定了属性在划分决策树的时候还面临着属性有不同取值的过程,单一属性不仅仅是是和否的方关系;
接下来我们将对以上的几个问题和结论一一分析。
- 主奏:决策树划分的几个准则(王朝最强的时候不是它处在盛世之时而是初期还处于上升的阶段)
图二伪代码我们标记的疑点一将是决策树使用过程中核心部分,决策最后属性的选取当然不是随机选择的,而是通过一系列的论证得出选择的属性最优的,首先我们介绍下信息增益的概念。
在信息论中有“信息熵”的概念,代表的衡量信息大小的一种量化标准,取代了我们常用的少、多、大量以及爆炸等口语化的量词。由此可知,在这里代表的是度量样本集合中纯度的一种指标,即样本集合中样本最终分为几个类(比如好瓜和坏瓜)以及每个类别中样本的数量的意思。在下面公式中样本D中k类样本所占的比例为pk,样本D的信息熵定义如下:
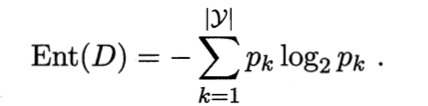
在公式中,多个类别的累加和,pk*log(2)(pk)中log(2)(pk)是递增的,pk是线性的,因此pk越大pk*log(2)(pk)越大,前面加减号代表取反,pk越大,-pk*log(2)(pk)越小,Ent(D)的值也就越小,某一类的概率大说明了纯度高,此时说明了D的纯度也高。
我们用于划分样本的某个属性可能分为多种情况比如以颜色区分瓜分为,青黑色,浅色,条纹色等,此时我们就以A代表西瓜的颜色属性,A1代表瓜为青黑色、A2代表瓜为浅色,A3代表瓜为条纹色,其中在瓜颜色属性的分支上会存在着三个分支,A1分支上代表着在颜色属性取值为青黑色的瓜,我们可以计算出在此分支上的信息熵,由此,我们可以得到颜色属性所有分支的信息熵,以上我们引出了一个新的概念--信息增益。
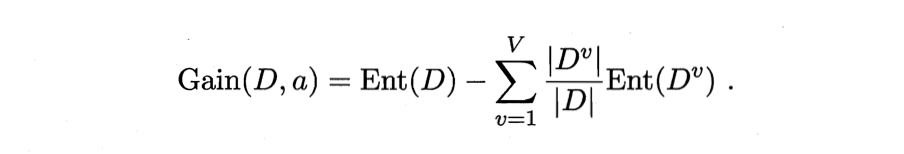
上式中Ent(D)代表整体信息上,后面的累加代表的是属性a上的所有的分支的信息熵的和。这里感觉讲的很繁琐,接下来我将以一个例子讲解,这里明白了决策树算法基本就没有什么难点,因为所谓的ID3也好,C4.5也好都是基于这个原理或是改进得到的。
我们还是以西瓜的颜色来作为实例讲解以上公式,例如西瓜的色泽取值为{青绿,乌黑,浅白},A1{色泽=青绿},A2{色泽:浅白},A3{色泽:乌黑},属性色泽有以下三个分支,同时总共有18个西瓜,总共6个好的西瓜,12个坏的西瓜,按照属性色泽划分如下:A1{1,2,3,4,5,6},A2{7,8,9,10,11,12},A3{13,14,15,16,17,18},A1的分支中有1个西瓜是好瓜,5个坏的;A2中2个好瓜,4个坏的;A3中3个好的,3个坏的。so~ ,我们可以得到信息增益计算如下:
Ent(D) = -(6/18 * log(2)(6/18) + 12/18*log(2)(12/18) )
Ent(A1) = -(1/6 * log(2)(1/6) + 5/6*log(2)(5/6) )
Ent(A2) = -(2/6 * log(2)(2/6) + 4/6*log(2)(4/6) )
Ent(A3) = -(3/6 * log(2)(3/6) + 3/6*log(2)(3/6) )
接下来我们引入第三个概念信息增益比,由上我们可以看出信息增益对可取值数目较多的属性是有所偏好的。选择一个唯一对应一个样本的属性进行分类,每一类都是唯一的,信息增益也是最大的,然而这样的划分是不具备泛化能力的(其实大家看到这里也明白了,信息上就是看当前属性的信息量的多寡,信息增益就是某属性的信息纯度,信息增益比是针对属性取值唯一时候的改进)。基于此,著名的C4.5决策树算法不直接使用信息增益,而是使用“增益率”来选择最优划分属性,直接上公式:
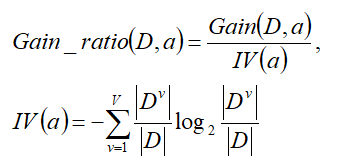
- 决策树的剪枝概念
剪枝简单理解就是我们的模型不可能完美无缺的,以防树结构的过拟合啊或者样本本身的噪声问题影响模型训练,因此加入剪枝操作,这里大家具体了解可以去网上查一下相关资料,具体参考文后链接1,这里我简单写一下减脂操作的数学原理:
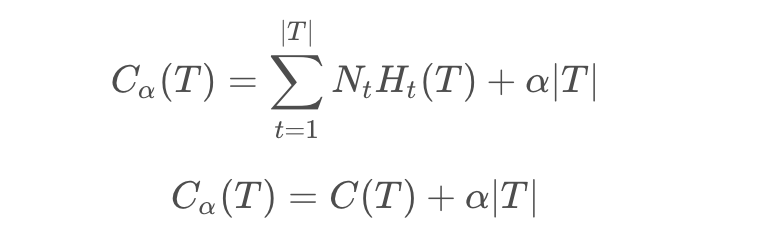
ps:C(T)代表的是损失函数,a|T|代表的是多叶子节点的约束。
- classification and regression tree(CART树,重要!)
1、回归树模型可表示为:
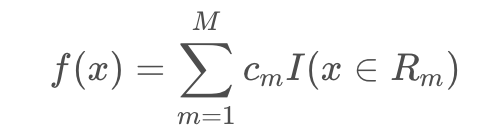
用平方误差作为回归树对训练数据的预测误差:
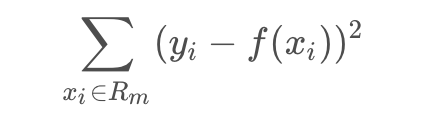
切分点(切分点即为决策树分裂点)确定:
遍历切分点(j, s),最优化:
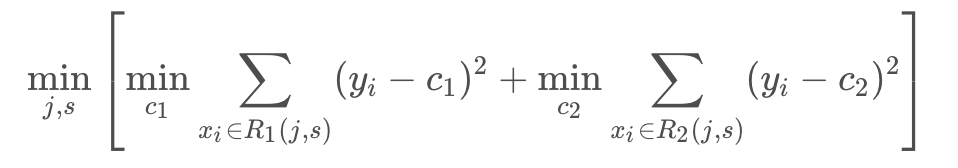
ps:其实回归树就是连续值,所谓的分割点就是对连续值的某一个值一刀切,大于他的和小于他的分到不同的两边。
2、分类树采用基尼系数划分:
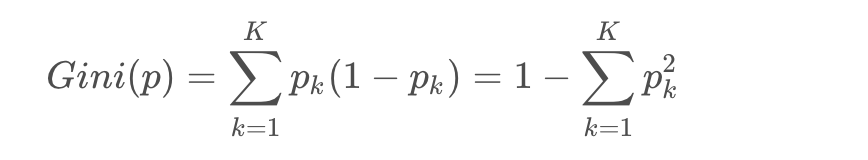
仍然是每一特征切为二类,寻找最优切分点:
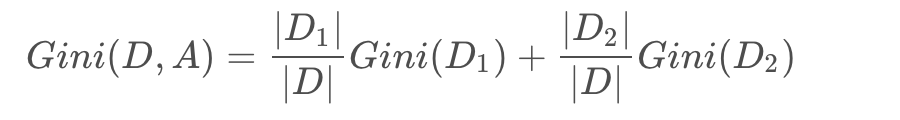
- 目前业内最流行的树模型算法-xgboost原理(待续)
- 参考
1、决策树剪枝原理
2、决策树剪枝介绍
3、cart树原理
