开发问题记录(这部分还是比较零碎)
本人才疏学浅,以下内容是个人查看各种文章以及搜索资料所写出来的,所以如以下内容有不合适的地方,请及时纠正我,不吝赐教,本人在这不胜感激
前言
没有总结过这块的知识,因为平时这块也是接触不是很深,所以基本就是用的时候在去搜查找资料,时间一长一些东西也就记不住了,在此将一些以前学过的以及现在在补充学习的内容写出来,也是为了翻一下自己的旧账,以及去思考自己下一步去做什么。
在此也要提前说明,以下出现的参考文章没有任何打广告的嫌疑,只不过是自己当时看的文章。
一、中间件
1.中间件是什么?
维基百科
中间件是一种计算机软件,它为软件应用程序提供超出操作系统可用服务的服务。可谓“软件胶水”。[1]
中间件使软件开发人员更容易实现通信和输入/输出,因此他们可以专注于其应用程序的特定目的。尽管该术语自 1968 年以来一直在使用,但它在 1980 年代作为解决如何将较新的应用程序链接到较旧的遗留系统的问题的解决方案而广受欢迎
该术语最常用于支持分布式应用程序中数据通信和管理的软件。2000 年的IETF研讨会将中间件定义为“在传输(即通过 TCP/IP)层服务集之上但在应用程序环境之下的那些服务”(即在应用程序级API之下)。[3]在这个更具体的意义上,中间件_可以被描述为client-server 中的破折号(“-”),或者-to-_ in peer-to-peer。中间件包括网络服务器、应用服务器、内容管理系统。,以及支持应用程序开发和交付的类似工具
ObjectWeb 将中间件定义为:“位于网络中分布式计算系统两侧的操作系统和应用程序之间的软件层。” [5]可被视为中间件的服务包括企业应用程序集成、数据集成、面向消息的中间件(MOM)、对象请求代理(ORB) 和企业服务总线(ESB)
中间件也指将两个或多个 API 分开并提供限速、身份验证和日志记录等服务的软件
广义和狭义
- 广义的说,所有不直接给客户直接提供业务价值的软件,都是中间件。举例说明,nginx和WebSphere App Server、MySQL都是中间件,而一个营销系统或者CRM系统、小额信贷系统,则不是中间件。
狭义上说,处于基础设施层的软件与业务系统软件中间这一层的一些软件或者库、框架,我们叫中间件,不一定是独立的程序。这样就把上面提到的类似DB和Web Server之类的软件划分到基础设施层了。狭义的中间件比如缓存中间件、数据库中间件、消息中间件、服务化中间件、交易中间件、调度中间件、集成中间件等等。现在互联网上说的一般是这几个
引自 [[https://zhuanlan.zhihu.com/p/97625832](https://zhuanlan.zhihu.com/p/97625832)]
2.解决了什么问题?
中间件它屏蔽了底层操作系统的复杂性,这样可以使程序员面对一个简单而统一的开发环境,减少程序设计的复杂性,专注于业务逻辑的开发,从而不必再为程序在不同系统软件上的移植而重复工作,大大减少了技术上的负担;而且提升了系统的稳定性,将一些风险转移到中间件上。
中间件解决的问题其实也挺多的,主要是现在个人认知不到位,所以如果想深入了解的其实可以自行查阅资料。
二、消息队列
1.什么是消息队列?
消息队列(Message Queue,简称MQ),指保存消息的一个容器,本质是个队列。
消息(Message)它是指在应用之间传送的数据,消息可以非常简单,比如只包含文本字符串,也可以更复杂,可能包含嵌入对象。
消息队列(Message Queue)是一种应用间的通信方式,消息发送后可以立即返回,有消息系统来确保信息的可靠专递,消息发布者只管把消息发布到MQ中而不管谁来取,消息使用者只管从MQ中取消息而不管谁发布的,这样发布者和使用者都不用知道对方的存在
2.为什么要有消息队列?
MQ(Message Queue)消息队列,是一种跨进程的通信机制,用于上下游传递信息;作为一个队列,其主要的功能就是排队积压。面对高并发任务时,由于来不及同步处理,请求往往会发生堵塞,表现最为明显的就是对数据库的操作,如大量的insert、update之类的请求同时到达数据库,直接导致无数的行锁表锁,甚至最后请求会堆积过多,从而触发too many connections错误。
此外,当上游服务处理能力远大于下游的情况时,若上游服务直接调用下游服务,由于下游服务处理能力远跟不上上游服务,因此明显的后果就是下游服务因处理压力而导致崩溃.
因此,MQ提出之初就是为了削峰限流,通过异步处理请求,减少请求相应时间和逻辑及物理上的解耦,从而缓解系统的压力,轻松应对高并发的情况
上游和下游
Definition 1: The direction of action
Upstream: receiving requests from.
Myupstreamservice is calling me.
Downstream: making requests to.
I am calling my downstream service
定义1:动作方向
上游:接收来自。我的上游业务在召唤我。
下游:向……提出请求。我要呼叫下游服务
Definition 2: The direction of dependency
Upstream: making requests to (and receiving responses from).
I am calling myupstreamservice.
Downstream: receiving requests from (and sending responses to).
My downstream service is calling me.
定义2:依赖的方向
上游:向上游发出请求(并从上游接收响应)。我在呼叫上游业务。
下游:接收请求(并向请求发送响应)。我的下游服务呼叫我。
So,
There are resources on the internet which support both of these definitions. Maybe we will resolve this question one day, but for now the answer is: it's either.
所以,互联网上有支持这两种定义的资源。也许有一天我们会解决这个问题,但目前的答案是:两者皆有
引自——What is Upstream and Downstream services in a Micro-service based architecture?
3.谈一下消息队列?
消息队列的话,因为传统应⽤是从⼀个应⽤程序发送消息直接到另⼀个应⽤程序,但是如果发送⼤量消息的话,⽽且当⼀台服务机已经挂掉时,另⼀台的上的程序功能就⽆法实现,也就是出现了服务异常,这样对⽤户的体验感是⽐较差的,所以在两者中间加⼀个消息队列,也就是其实说的就和兵来将挡⽔来⼟掩这句话⼀样,为的是当⼀⽅服务挂掉时,另⼀⽅服务还可以正常运⾏;但此时就需要考虑消息队列中的问题,⽐如就是当消息队列服务挂掉怎么办,还有是否重复消息,消息是否正确处理等问题;通过消息队列就可以降低系统耦合性。
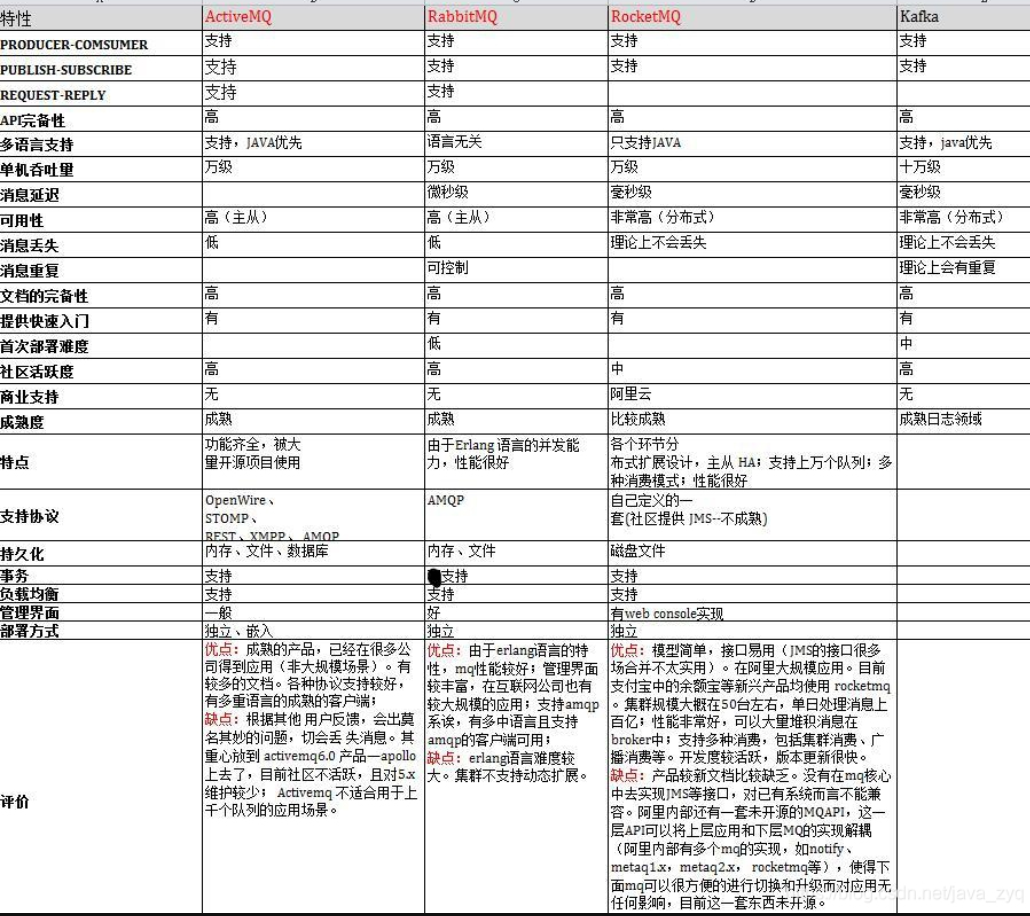
⽽Rabbit和阿⾥的Rocket还有Apache的Kafka、Active都是为了实现消息机制,⽽Rabbit的话是万级的吞吐量,Kafka是百万级的;⽽且Rabbit的性能较⾼,⼀般⽤于主从架构中,⽽Kafka天⽣分布式,性能也⽐较好,⼀般⽤于⼤数据领域,⽐较依赖zookeeper。
Rabbit⼯作模式的话,有简单、⼯作、发布订阅、路由、主题五种,⽽其中简单和⼯作模式基本是模拟了⽣产者消费者的问题,发布和订阅为了满⾜资源共享即消息的共享,每个消费者都有⾃⼰的消息队列,⽽每个消息队列都得去绑定交换机,消息通过交换机再通过队列再到消费者。路由模式是为了消费者可以有选择的去消费消息,主题模式的话,类似正则表达式给交换机添加匹配机制,匹配到相应队列,然后队列中的监听消费者接收消息进⾏消费。什么要⽤它,是因为在分布式结构中,模块和模块之间需要相互协同,所以选择了异步并且多线程Rabbit,这样可以使处理数据变得⾼校和稳定以及主要的解耦提升⽹站性能。为什么⽤它,是因为其他MQ的开源社区都没有个开源社区⽕,⽽且这个教程⽐较全,所以选择了这个。Kafka其实⼀种分布式流式系统,侧重点不⼀样,rabbit更适合⼀些项⽬的开发吧。
当然这只是我看到的一些内容,因为个人也是没有接触过这类项目的开发,没有体验过。
如果还需要认识,可以参考以下文章(并无任何打广告的意图,全是网上搜的看的资料)
************************************************************************************************
面试连环炮系列(五):你们的项目为什么要用RabbitMQ
别纠结了,教你如何做 ------消息中间件选型分析
为什么使用Kafka、ActiveMQ、RabbitMQ、RocketMQ 消息队列?
************************************************************************************************
三、ElasticSearch技术
1.全文搜索、倒排索引?
通常,在“精度”和“召回”之间存在权衡。 高精度意味着呈现较少的不相关结果(无误报),而高召回率意味着丢失较少的相关结果(无误报)。 使用 LIKE 运算符可以为您提供 100% 的精确度,而不会在召回方面做出让步。 全文搜索工具为您提供了很大的灵活性来调低精度以获得更好的召回率。
大多数全文搜索实现使用“倒排索引”。 这是一个索引,其中键是单个术语,关联的值是包含该术语的记录集。 全文搜索被优化以计算这些记录集的交集、并集等,并且通常提供排名算法来量化给定记录与搜索关键字匹配的强度。
SQL LIKE 运算符可能非常低效。 如果将其应用于未编入索引的列,则将使用完整扫描来查找匹配项(就像对未编入索引的字段的任何查询一样)。 如果该列已编入索引,则可以针对索引键执行匹配,但效率远低于大多数索引查找。 在最坏的情况下,LIKE 模式将具有需要检查每个索引键的前导通配符。 相比之下,许多信息检索系统可以通过在选定字段中预编译后缀树来支持前导通配符。
全文搜索的其他典型特征是
词法分析或标记化——将非结构化文本块分解为单独的单词、短语和特殊标记
形态分析或词干提取——将给定词的变体合并为一个索引词; 例如,将“小鼠”和“鼠标”,或“电气化”和“电动”视为同一个词
排名——测量匹配记录与查询字符串的相似度
可以通过这篇博文认识一下:什么是倒排索引?
2.ElasticSearch技术?
Lucene
Apache Lucene是一个免费的开源搜索引擎软件库,最初由Doug Cutting完全用Java编写。它由Apache 软件基金会支持,并根据Apache 软件许可证发布。Lucene 被广泛使用,是非研究搜索应用程序的标准基础
Lucene可以看作一个jar包,它封装好了一些复杂的API以及包含了倒排索引,数据存储到磁盘。
也就是说lucene是一种采取了倒排索引的方式进行高效率搜索的框架。但是它api复杂,且不支持集群。
引入 lucene 依赖,基于它的 api 进行开发就行了,用了 lucene,我们就可以基于已有的数据建立倒排索引。而Elasticsearch完美解决了lucene的这些缺点,它天然支持集群,api相对简单,开箱即用。底层还是封装的lucene。
ES本身底层是基于搜索引擎去做的,所以更擅⻓去做⼀些全⽂匹配,复杂的⼀些搜索或索引,因为
它⾥⾯是有倒排索引的⼀些机制,分词能⼒⽐较强,但是它对写⼊和写出的⽀持不是很好;⽽
MongoDB的话,虽然是⼀种⽂档型的数据库,但底层数据结构还是B树实现的,⽽且⽀持事务,打算是
替换mysql,所以两者定位也不同。
维基百科
Elasticsearch 是一个基于** Lucene** 库的搜索引擎。 它提供了一个分布式的、支持多租户的全文搜索引擎,带有一个 HTTP Web 界面和无模式的 JSON 文档。 Elasticsearch 是用 Java 开发的,在源代码可用的服务器端公共许可证和弹性许可证下获得双重许可,[3] 而其他部分 [4] 属于专有(源代码可用)弹性许可证。 官方客户端支持 Java、.NET (C#)、PHP、Python、Apache Groovy、Ruby 和许多其他语言。 [5] 根据 DB-Engines 排名,Elasticsearch 是最受欢迎的企业搜索引擎
Elasticsearch 可用于搜索各种文档。 它提供可扩展的搜索,具有近乎实时的搜索,并支持多租户。 [5] “Elasticsearch 是分布式的,这意味着索引可以分为多个分片,每个分片可以有零个或多个副本。每个节点托管一个或多个分片,并充当协调器,将操作委托给正确的分片。重新平衡和 路由是自动完成的”。[5] 相关数据通常存储在同一个索引中,该索引由一个或多个主分片和零个或多个副本分片组成。 一旦创建了索引,就不能更改主分片的数量。 [25]
Elasticsearch 与名为 Logstash 的数据收集和日志解析引擎、名为 Kibana 的分析和可视化平台以及轻量级数据传送器的集合 Beats 一起开发。 这四种产品旨在用作集成解决方案,称为“Elastic Stack”(以前称为“ELK stack”)。[26]
Elasticsearch 使用 Lucene 并尝试通过 JSON 和 Java API 使其所有功能可用。 它支持分面和渗透,[27] [28] 这对于通知新文档是否与注册查询匹配很有用。 另一个功能称为“网关”,处理索引的长期持久性;[29] 例如,可以在服务器崩溃时从网关恢复索引。 Elasticsearch 支持实时 GET 请求,这使得它适合作为 NoSQL 数据存储,[30] 但它缺乏分布式事务
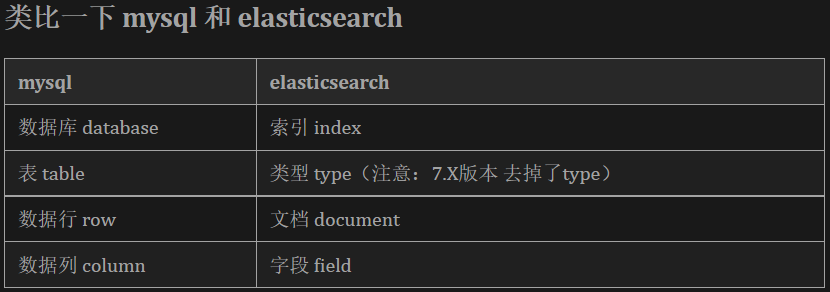
看张图——来自B站UP主“不高兴就喝水”
3.关于ElasticSearch的一些问题
ElasticSearch, Sphinx, Lucene, Solr, Xapian。哪种适合哪种用途
作为 ElasticSearch 的创建者,也许我可以给你一些关于我为什么继续并首先创建它的推理:)。
使用纯 Lucene 具有挑战性。 如果您希望它真正运行良好,您需要注意很多事情,而且,它是一个库,因此没有分布式支持,它只是一个您需要维护的嵌入式 Java 库。
就 Lucene 的可用性而言,早在(现在将近 6 年),我创建了 Compass。 它的目标是简化 Lucene 的使用并使日常 Lucene 更简单。 我一次又一次遇到的是能够分发 Compass 的要求。 我开始在 Compass 内部进行研究,通过与 GigaSpaces、Coherence 和 Terracotta 等数据网格解决方案集成,但这还不够。
就其核心而言,需要对分布式 Lucene 解决方案进行分片。 此外,随着 HTTP 和 JSON 作为无处不在的 API 的进步,这意味着可以轻松使用具有不同语言的许多不同系统的解决方案。
这就是我继续创建 ElasticSearch 的原因。 它具有非常先进的分布式模型,原生支持 JSON,并公开了许多高级搜索功能,所有这些功能都通过 JSON DSL 无缝表达。
Solr 也是一个通过 HTTP 公开索引/搜索服务器的解决方案,但我认为 ElasticSearch 提供了一个非常优越的分布式模型和易用性(尽管目前缺乏一些搜索功能,但不会太久,并且在任何 在这种情况下,计划是将所有 Compass 功能放入 ElasticSearch 中)。 当然,我是有偏见的,因为我创建了 ElasticSearch,所以你可能需要自己检查。
至于Sphinx,我没用过,不便评论。 我可以向您推荐的是 Sphinx 论坛上的这个帖子,我认为它证明了 ElasticSearch 的卓越分布式模型。
当然,ElasticSearch 的功能远不止分布式。 它实际上是在考虑到云的情况下构建的。 您可以查看网站上的功能列表
为什么要使用 NoSQL(MongoDB、Cassandra、CouchDB 等)而不是 Lucene(或 Solr)作为“数据库”
我(我相信其他人)在答案中寻找的是对它们的一些深入比较。 让我们一起跳过关系数据库的讨论,因为它们用于不同的目的。
Lucene 提供了一些重要的优势,例如强大的搜索和权重系统。 更不用说 Solr 中的方面(Solr 很快就会被集成到 Lucene 中,是的!)。 您可以使用 Lucene 文档来存储 ID,并像 MongoDB 一样访问这些文档。 将它与 Solr 混合使用,您现在可以获得基于 WebService 的负载平衡解决方案。
在谈论 MongoDB 的类似数据存储和可扩展性时,您甚至可以比较 Velocity 或 MemCached 等进程外缓存提供程序。
MongoDB 的限制让我想起了使用 MemCached,但我可以使用 Microsoft 的 Velocity,并且比 MongoDB 拥有更多的分组和列表收集能力(我认为)。 没有比在内存中缓存数据更快或可扩展的了。 甚至 Lucene 也有内存提供者。
MongoDB(和其他)确实有一些优势,例如其 API 的易用性。 新建一个文档,创建一个 id 并存储它。 完毕。 好,容易.
Solr 与 ElasticSearch
回答一:
更新
既然问题范围已经更正,我也可以在这方面添加一些内容:
Apache Solr和ElasticSearch之间有很多比较可用,因此我将参考我自己认为最有用的那些,即涵盖最重要的方面:
- Bob Yoplait 已经将 kimchy 的答案与ElasticSearch、Sphinx、Lucene、Solr、Xapian 联系起来。哪个适合哪个用途?,总结了他_继续创建 ElasticSearch_的原因,在他看来,与 Solr 相比,ElasticSearch提供了更优越的分布式模型和易用性。
- Ryan Sonnek 的实时搜索:Solr 与 Elasticsearch提供了一个有见地的分析/比较,并解释了为什么他从 Solr 切换到 ElasticSeach,尽管他已经是一个快乐的 Solr 用户 - 他总结如下:在构建标准搜索应用程序时,Solr可能是首选武器,但Elasticsearch将其提升到一个新的水平,其架构用于创建现代实时搜索应用程序。Percolation 是一项令人兴奋的创新功能,可单枪匹马地将 Solr 吹出水面。Elasticsearch 具有可扩展性、快速性,并且是与.Adios Solr,很高兴认识你。[强调我的]
- 维基百科上关于 ElasticSearch 的文章引用了著名的德国 iX 杂志的比较,列出了优点和缺点,这几乎总结了上面已经说过的内容:优点:缺点:
- ElasticSearch 是分布式的。不需要单独的项目。副本也接近实时,这被称为“推送复制”。
- ElasticSearch 完全支持 Apache Lucene 的近实时搜索。
- 处理多租户不是一种特殊的配置,使用 Solr 需要更高级的设置。
- ElasticSearch 引入了网关的概念,使完整备份更容易。
- 只有一个主要开发人员_[根据当前的_Elasticsearch GitHub 组织不再适用,除了首先拥有非常活跃的提交者基础之外]
- 没有自动预热功能 [根据新的索引预热 API不再适用]
初步答复
它们是针对完全不同用例的完全不同的技术,因此根本无法以任何有意义的方式进行比较:
- Apache Solr - Apache Solr 在易于使用、快速的搜索服务器中提供 Lucene 的功能,并具有分面、可扩展性等附加功能
- Amazon ElastiCache - Amazon ElastiCache 是一项 Web 服务,可让您轻松在云中部署、操作和扩展内存缓存。
[强调我的]
也许这已经以某种方式与以下两种相关技术混淆了:
- ElasticSearch -它是一个基于 Apache Lucene 构建的开源 (Apache 2)、分布式、RESTful、搜索引擎。
- Amazon CloudSearch - Amazon CloudSearch 是一项完全托管的云端搜索服务,让客户能够轻松地将快速且高度可扩展的搜索功能集成到他们的应用程序中。
该_Solr的_和_ElasticSearch_产品听起来一见钟情惊人地相似,都使用同样的后端搜索引擎,即Apache的Lucene的。
虽然_Solr_较旧、用途广泛且成熟并相应地被广泛使用,但_ElasticSearch_已专门开发用于解决_Solr_在现代云环境中具有可扩展性要求的缺点,这些缺点很难(呃)用_Solr 解决_。
因此,将_ElasticSearch_与最近推出的_Amazon CloudSearch_进行比较可能是最有用的(请参阅介绍性文章开始以低于 100 美元/月的价格进行一小时搜索),因为两者都声称原则上涵盖了相同的用例.
回答二:
我看到上面的一些答案现在有点过时了。从我的角度来看,我每天都使用 Solr(云和非云)和 ElasticSearch,这里有一些有趣的区别:
- 社区:Solr 拥有更大、更成熟的用户、开发者和贡献者社区。ES 拥有较小但活跃的用户社区和不断增长的贡献者社区
- 成熟度:Solr 更成熟,但 ES 增长很快,我认为它很稳定
- 性能:难以判断。我/我们没有做过直接的性能基准测试。LinkedIn 的一个人曾经比较过 Solr、ES 和 Sensei,但最初的结果应该被忽略,因为他们对 Solr 和 ES 都使用了非专家设置。
- 设计:人们喜欢 Solr。Java API 有点冗长,但人们喜欢它的组合方式。不幸的是,Solr 代码并不总是很漂亮。此外,ES 内置了分片、实时复制、文档和路由。虽然其中一些也存在于 Solr 中,但感觉有点像事后的想法。
- 支持:有些公司为 Solr 和 ElasticSearch 提供技术和咨询支持。我认为唯一为两者提供支持的公司是 Sematext(披露:我是 Sematext 创始人)
- 可扩展性:两者都可以扩展到非常大的集群。ES 比 Solr 之前的 Solr 4.0 版本更容易扩展,但在 Solr 4.0 中则不再如此。
如需更全面地了解 Solr 与 ElasticSearch 主题,请查看https://sematext.com/blog/solr-vs-elasticsearch-part-1-overview/。这是 Sematext 对 Solr 与 ElasticSearch 进行直接和中立比较的系列文章中的第一篇文章。披露:我在 Sematext 工作
可以参考以下博文
《Elasticsearch 快速开始》《老婆问我ES是谁?》《用最简单的话告诉你什么是ElasticSearch》
四、分布式与微服务
1.什么是分布式与微服务?
分布式的话,其实也去查过以及去看过⽹上的⼀些解释,然后分布式它其实也并不是某⼀⻔具体的
技术,也不是什么具体的框架,简单的理解就是它是通过计算能⼒和数据存储能⼒分布到不同的服务器
上,也就可以理解为解决⼀种问题的⽅案吧,⽽这个微服务的话就是在垂直⽅向上做了⼀个细拆分,将
服务不断的细化,这样可以提⾼系统的可⽤性和容错⼒、并发性等等,相关实现技术的话现在⽐较流⾏
的Springcloud和重阿⾥重启的DubboRPC框架(RPC是远程过程调⽤,是定义的⼀种计算机通信协议
即规则,即它实现了⼀台计算机上的程序可以调⽤另⼀个计算机上的程序,也就是实现了两个物理地址
之间的通信)+zookeeper实现微服务⽅案。既然⼀个系统是微服务架构的话,那它也是⼀个分布式系
统。
维基百科
分布式计算是研究分布式系统的计算机科学领域。 分布式系统是一种系统,其组件位于不同的联网计算机上,它们通过从任何系统向彼此传递消息来通信和协调它们的动作。 组件彼此交互以实现共同目标。 分布式系统的三个显着特征是:组件的并发性、缺少全局时钟和组件的独立故障。 分布式系统的示例多种多样,从基于SOA 的系统到大型多人在线游戏,再到点对点应用程序。在分布式系统中运行的计算机程序称为分布式程序(分布式编程就是编写此类程序的过程)。 消息传递机制有许多不同类型的实现,包括纯 HTTP、类似 RPC 的连接器和消息队列。分布式计算也指使用分布式系统来解决计算问题。 在分布式计算中,一个问题被分成许多任务,每个任务由一台或多台计算机解决,它们通过消息传递相互通信
可参考博文:《三分钟读懂TT猫分布式、微服务和集群之路》《「和耳朵」聊聊微服务与分布式系统》
《什么是分布式系统,如何学习分布式系统》
五、Docker技术
维基百科
Docker 可以将应用程序及其依赖项打包到可以在任何 Linux、Windows 或 macOS 计算机上运行的虚拟容器中。这使应用程序能够在各种位置运行,例如本地、公共云和/或私有云。[11]在 Linux 上运行时,Docker 使用Linux 内核的资源隔离功能(例如cgroups和内核命名空间)和具有联合功能的文件系统(例如OverlayFS)[12]允许容器在单个 Linux 中运行例如,避免启动和维护的开销虚拟机。[13]macOS 上的Docker使用 Linux虚拟机来运行容器。[14]
由于 Docker 容器是轻量级的,单个服务器或虚拟机可以同时运行多个容器。[15] 2018 年的一项分析发现,典型的 Docker 用例涉及每台主机运行 8 个容器,而四分之一的分析组织在每台主机上运行 18 个或更多。[16]
Linux 内核对命名空间的支持主要[17]隔离了应用程序对操作环境的看法,包括进程树、网络、用户 ID 和挂载的文件系统,而内核的 cgroup 为内存和 CPU 提供资源限制。[18]从 0.9 版本开始,除了通过libvirt、LXC和systemd-nspawn使用抽象的虚拟化接口外,Docker 还包含自己的组件(称为“ libcontainer ”)以使用 Linux 内核直接提供的虚拟化工具。[19][10][11][20]
Docker 实现了一个高级API来提供隔离运行进程的轻量级容器。[21] Docker 容器是标准进程,可以使用内核特性来监控它们的执行,包括。使用 strace 来观察和调解系统调用。
可参考文章:《Docker 容器入门》、《两小时入门Docker》、《Java后端学习路线》
六、阿里云第三方技术
这块其实也是简单的进行应用,并没有深入的去了解。2020年的疫情那段期间因为阿里云有活动所以就搞了一台2G的服务器,系统是centos7,也运行不了太多东西。当时主要就用了一下对象存储OSS、视频点播、短信服务,要注意的是短信服务好像是在2020年12月份不允许随便申请了,也就是如果没有一些重要认证的话基本不会给你用。
对象存储和视频点播这些第三方功能,阿里云是直接有API文档可以看的,而且比较全面。
阿里云开源镜像站:https://developer.aliyun.com/mirror/
存储产品文档:https://www.aliyun.com/help/docs/storage?spm=5176.12672711.help.40.4e661fa3JVBpDX
帮助文档:https://help.aliyun.com/?spm=5176.7991389.J_9220772140.6.11d347ealWa1tH
(虽然在网上看到阿里风评不是很好,而且再加上最近闹得这事,但一码归一码,技术这块是真的做的很不错的)
七、JWT
jwt它也是json的⼀套标准吧,可以通过声明信息去获取服务器资源,可被加密,去做认证等;项⽬
中主要是做⼀个认证,因为传统的通过redis实现的集中式session管理(因为session中的数据类似map
结构,⽽redis也⽀持hash数据类型,所以⽤redis⽐较好),也是基于http协议,⽽这个协议是⽆状态
的,所以每次当有⽤户进⾏认证的时候,⼀般就需要在内存中产⽣新的session,⽽如果⽤户增多,是对
服务器这块有压⼒,⽽且不利于分布式应⽤的开发,因为认证信息保留在内存中的话,下⼀次认证就还
需要去这台服务器。⽽且因为是基于cookie进⾏识别,所以就会产⽣csrf跨站请求攻击,这是不好的;
⽽token虽然也是基于http协议,但不需要在服务端保留⽤户的认证信息或会话信息,基本流程的话就
是,⽤户输⼊⽤户名和密码请求服务器,服务器进⾏验证⽤户信息,然后通过验证后给⽤户发⼀个
token,然后客户端存储这个token,然后每次发送请求的时候都会带上token,服务端再验证token并返
回数据,要把token放请求头中,服务器这边要⽀持跨域请求cors,具体⽅式的话可以在java中添加跨
域注解或者采⽤⽹关的⽅式去实现;jwt主要有头部信息、有效信息、签证信息这三个部分。
参考文章:《傻傻分不清之 Cookie、Session、Token、JWT》、《认识JWT》、《基于jwt的token验证》
最后
今天是8月15日,伟大的中华人民共和国经历14年的时间打败了日本帝国主义侵略者,76年前的今天也就是1945年8月15日正午,日本无条件投降,日本裕仁天皇向全日本广播,接受波茨坦公告、实行无条件投降,结束战争。1945年8月21日今井武夫飞抵芷江洽降。 [1] 1945年9月2日上午9时,标志着二战结束的日本投降签字仪式,在停泊在东京湾的密苏里号主甲板上举行。
维基百科:《日本投降》https://zh.wikipedia.org/wiki/%E6%97%A5%E6%9C%AC%E6%8A%95%E9%99%8D
铭记历史 勿忘国耻 吾辈自强


警言: 无论人生上到哪一层台阶,阶下有人在仰望你,阶上亦有人在俯视你。你抬头自卑,低头自得,唯有平视,才能看见真实的自己。
转载请注明原文链接:https://www.cnblogs.com/yuyueq/p/15143973.html
如果觉得这篇文章对你有小小的帮助的话,记得在右下角点个“推荐”哦,博主在此感谢你的支持!

