

05 2021 档案
摘要:前言 主要参考的是《Reinforcement Learning: An introduction Second Edition》这本书里的例子 英文版地址:http://incompleteideas.net/book/first/ebook/the-book.html 代码源文件可以参考这篇回答
阅读全文
摘要:前言 主要参考的是《Reinforcement Learning: An introduction Second Edition》这本书里的例子 英文版地址:http://incompleteideas.net/book/first/ebook/the-book.html 代码源文件可以参考这篇回答
阅读全文
摘要:### 前言 主要参考的是《Reinforcement Learning: An introduction Second Edition》这本书里的例子 英文版地址:http://incompleteideas.net/book/first/ebook/the-book.html 代码源文件可以参考
阅读全文
摘要: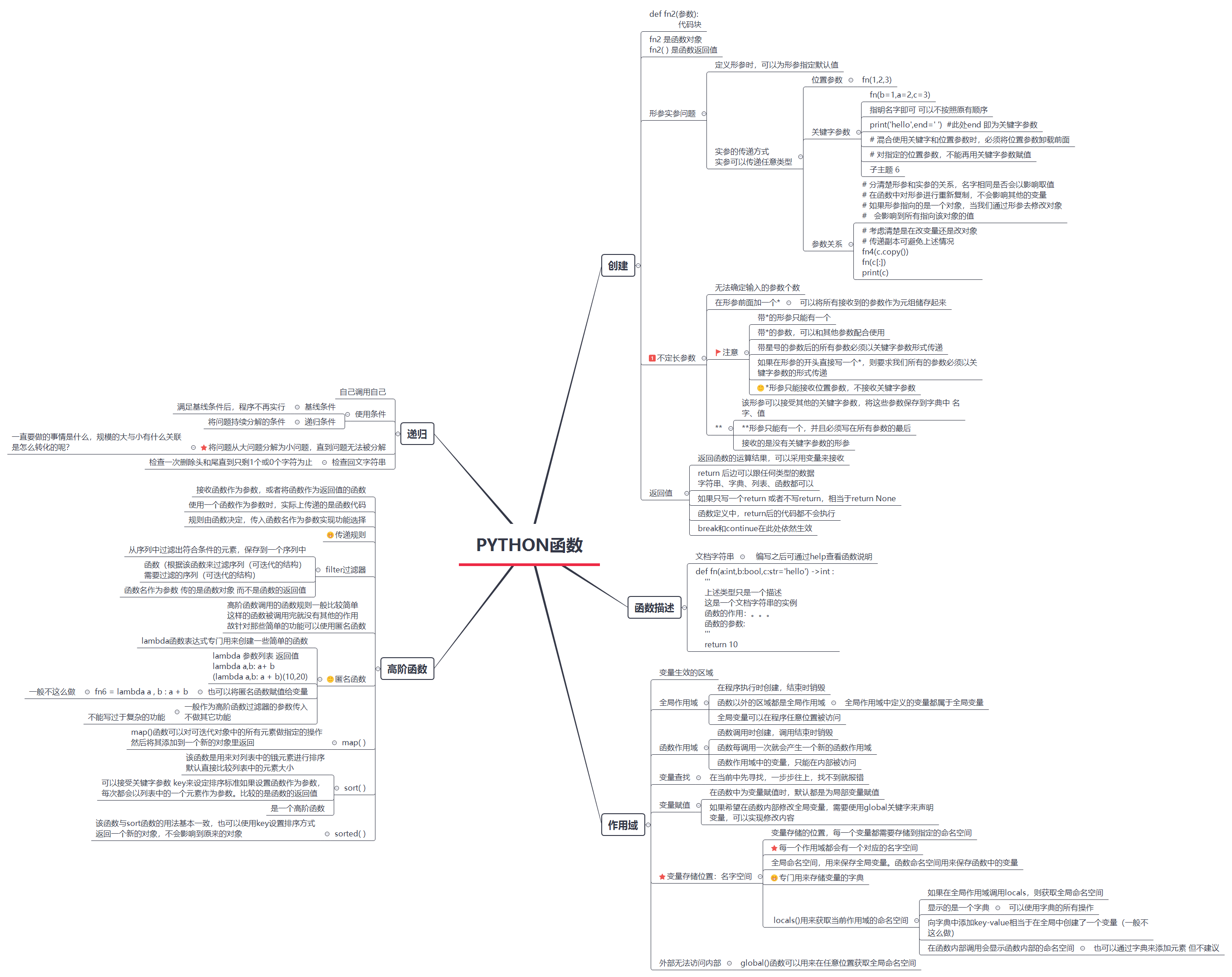
阅读全文
摘要:开始Python的复习!(以前学的忘了好多-_-) 主要参考的是Github上的一个项目:https://github.com/jackfrued/Python-100-Days 文章主要是对该项目中的内容进行学习 穿插一点自己的学习想法等内容~ 基本的那些变量类型、数据类型、循环等概念就不复习啦
阅读全文
摘要:n步时序差分方法是单独的蒙特卡罗和时序差分方法更一般的推广,性能通常优于那两种极端形式。 n步TD预测 MC使用完整奖赏序列 一步TD基于下一步奖赏,将一步后的状态值作为剩余奖赏的近似值进行引导更新 n步自举将MC与TD统一,灵活选择用未来n步的数据进行引导更新。更新是基于中间数量的奖赏值 n步Sa
阅读全文
摘要:蒙特卡罗方法在没有环境模型的基础上,直接从经验中学习,无需获知环境的全部信息。动态规划从其它的已经学习到的估计值去更新估计值。TD则结合了这两种方法的优点,且不需要等到片段结束。 对于控制问题,也就是寻找一个最优策略,DP、TD和蒙特卡罗方法都是用一些GPI的变量。不同之处在于它们对于预测问题的求解
阅读全文
摘要:概念解释 同轨(on policy)策略: 用于生成采样数据序列的策略和用于实际决策的待评估和改进的策略是一样的。在同轨策略方法中,策略一般是软性的(选中任何一个动作的概率大于某个值),会逐渐逼近一个确定性策略。 【同轨策略算法的蒙特卡罗控制的总体思想依然是GPI,采用首次访问型MC算法来估计当前策
阅读全文
摘要:前言 在不了解环境动态特性或已知动态特性有时求解不同状态的概率也很困难的情况下使用MC方法更加合理。 蒙特卡罗算法通过平均样本的回报来解决强化学习问题。它主要利用的是经验,从真实的环境交互或环境交互的仿真中得到一个采样队列(状态、动作和奖励)【这决定了该方法主要针对分幕式任务,即任务在有限步内完成。
阅读全文
摘要:在阅读Offline Reinforcement Learning的相关文章时有文章根据动态规划和策略梯度进行分类,在此加上进行一些简单的总结。主要参考了参考链接中的内容 前言 强化学习研究从总体思路上可以分为两个大方向,一种是通过值函数近似来得到策略 称其为动态规划;另一种是策略梯度,讲究直接用函
阅读全文
摘要:马尔可夫决策过程特征 · 状态、行动、奖励都是有限数值。下一次的状态和奖励只依赖于上一时刻的状态和行动。 · 马尔可夫决策过程与随机过程中的马尔可夫过程类似,不同点在于马尔可夫过程只看重状态之间的转移,主要研究的是给定初始状态稳定之后会变成什么样。在马尔可夫决策过程中,增加了动作的概念,两个状态之间
阅读全文
摘要:K臂赌博机问题描述: 重复在K个动作中选择,每次做出选择后都会得到一定数值的收益,收益由选择的动作决定的平稳概率分布产生,目标是在某一段时间内最大化总收益的期望。 问题解决思路: 选择收益(价值)最大的动作。知道价值则直接选择,不知道价值就通过多次试验估计价值。 动作值估计 大数定律(多次尝试这个动
阅读全文
摘要:强化学习理解 强化学习是智能体与环境的交互(探索和试错),通过交互信息来感知环境,从而调整自己的行为,选择出最好的结果。 强化学习更加侧重于从互动中进行目标导向的学习。 【将情境映射到行动,以便最大化数值奖赏信号。通俗理解为对人学习过程的简单模拟,相当于人做了多次的探索,把最后的劳动成果以状态值函数
阅读全文

