
MYSQL初级
整理!提出问题和解决问题。
数据库概述
DB:数据库(Database)即存储数据的“仓库”,其本质是一个文件系统。它保存了一系列有组织的数据。
DBMS:数据库管理系统(Database Management System)是一种操纵和管理数据库的大型软件,用于建立、使用和维护数据库,对数据库进行统一管理和控制。用户通过数据库管理系统访问数据库中表内的数据。
SQL:结构化查询语言(Structured Query Language)专门用来与数据库通信的语言。
关系型数据库和非关系型数据库
关系型数据库是以关系(表格)为基础的数据库,它采用了 SQL(Structured Query Language)作为数据操作语言,常见的关系型数据库包括 MySQL、Oracle、SQL Server 等。
非关系型数据库则是基于文档、键值、列族等方式存储数据的数据库,它通常没有固定的表结构,因此也被称为 NoSQL(Not Only SQL)数据库。常见的非关系型数据库包括 MongoDB、Redis、Cassandra 等。可看成传统关系型数据库的功能阉割版本,基于键值对存储数据,不需要经过SQL层的解析, 性能非常高。同时,通过减少不常用的功能,进一步提高性能。
键值型数据库通过Key-Value 键值的方式来存储数据,其中 Key 和 Value 可以是简单的对象,也可以是复杂的对象。Key 作为唯一的标识符,优点是查找速度快,在这方面明显优于关系型数据库,缺点是无法像关系型数据库一样使用条件过滤(比如 WHERE),如果你不知道去哪里找数据,就要遍历所有的键,这就会消耗大量的计算。键值型数据库典型的使用场景是作为内存缓存。Redis是最流行的键值型数据库。
表的关联关系
一对一关联:一个学生的信息分为常用信息和不常用信息(中间存在着唯一的对应关系)
一对多关联:客户表和订单表,分类表和商品表,部门表和员工表。
多对多关联:学生-课程,一个学生选多门课,一门课可被多个学生选择。
自我引用:员工编号和主管编号,自己的表里会存在自己。
数据库的卸载安装
使用命令行的语句等。
这里整理的都是参考B站尚硅谷康师傅的资料。
注意事项
一开始数据库的默认编码是latin,my.ini文件的配置修改。修改后重启服务,保证数据库支持UTF-8,创建数据库和表。
1.8之后默认是utf-8,不需要重新修改配置文件。
底层C++代码是开源的。
windows操作系统本身不区分大小写。
单行注释:#注释文字(MySQL特有的方式)
单行注释:-- 注释文字(--后面必须包含一个空格。)
多行注释:/* 注释文字 */ 多行注释不能嵌套
=就是等于,不是赋值。
数据导入
2.5 数据导入指令
在命令行客户端登录mysql,使用source指令导入
mysql> source d:\mysqldb.sql
SELECT

SELECT 1 + 1,3 * 2;
SELECT 1 + 1,3 * 2
FROM DUAL; #dual:伪表
# *:表中的所有的字段(或列)
SELECT * FROM employees;
SELECT employee_id,last_name,salary
FROM employees;
#6. 列的别名
# as:全称:alias(别名),可以省略
# 列的别名可以使用一对""引起来,不要使用''。
SELECT employee_id emp_id,last_name AS lname,department_id "部门id",salary * 12 AS "annual sal"
FROM employees;
在SELECT语句中使用关键字DISTINCT去除重复行,是对后面所有列名的组合进行去重
SELECT DISTINCT department_id
FROM employees;
在 MySQL 里面,空值不等于空字符串。一个空字符串的长度是0,而一个空值的长度是空。在 MySQL 里面,空值是占用空间的。
需要保证表中的字段、表名等没有和保留字、数据库系统或常用方法冲突。如果相同,需要在SQL语句中使用一对``(着重号)引起来。
SELECT 查询还可以对常数进行查询。就是在 SELECT 查询结果中增加一列固定的常数列。这列的取值是我们指定的,而不是从数据表中动态取出的。
使用WHERE 子句,将不满足条件的行过滤掉,WHERE子句紧随 FROM子句。
运算符
加减乘除取模
-
-
- / %
在MySQL中 + 只表示数值相加。如果遇到非数值类型,先尝试转成数值,如果转失败,就按0计算(补充:MySQL中字符串拼接要使用字符串函数CONCAT()实现);
一个数除以整数后,不管是否能除尽,结果都为一个浮点数;
在MySQL中,一个数除以0为NULL。
- / %
-
比较运算符
比较的结果为真则返回1,比较的结果为假则返回0,其他情况则返回NULL。
等号运算符(=)判断等号两边的值、字符串或表达式是否相等,如果相等则返回1,不相等则返回0。
在使用等号运算符时,遵循如下规则:
如果等号两边的值、字符串或表达式都为字符串,则MySQL会按照字符串进行比较,其比较的
是每个字符串中字符的ANSI编码是否相等。
如果等号两边的值都是整数,则MySQL会按照整数来比较两个值的大小。
如果等号两边的值一个是整数,另一个是字符串,则MySQL会将字符串转化为数字进行比较。
如果等号两边的值、字符串或表达式中有一个为NULL,则比较结果为NULL。
对比:SQL中赋值符号使用 :=
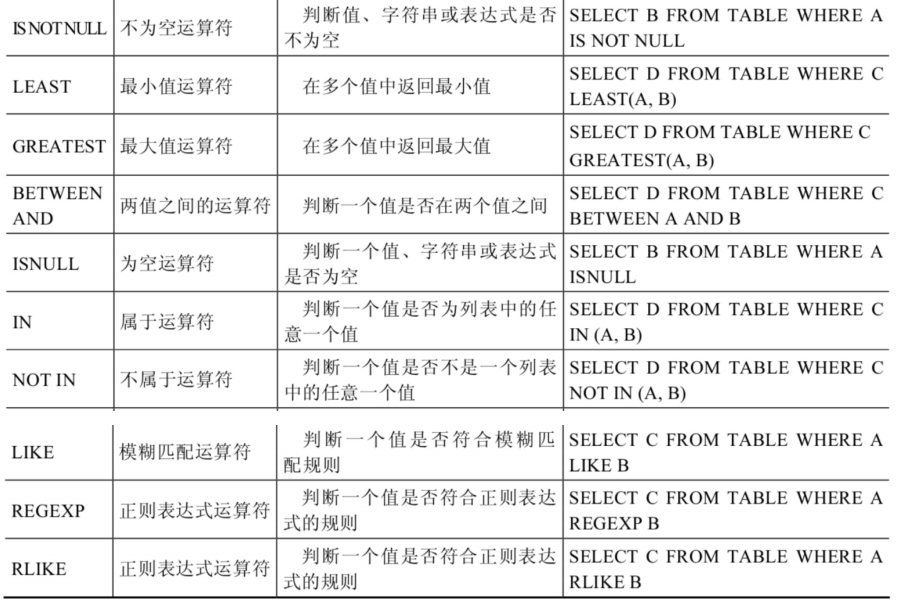
like运算符:%匹配0个或多个字符。_只能匹配一个字符。
逻辑运算符
NOT AND OR
排序与分页
SELECT first_name, salary
FROM employees
WHERE salary NOT BETWEEN 8000 and 17000
ORDER BY salary DESC
LIMIT 20, 20;
多表查询
多表查询 -- 分表的目的是防止冗余,提升查询效率。(有效性 冗余 维护 使用场景 等多个角度)
出现笛卡尔积的错误,没有链接条件,A中的a会和B中的每一个b都匹配。
多表查询的正确方式:需要有连接条件【笛卡尔积造出了平面,增加条件寻找里边的曲线】
SELECT employee_id,department_name
FROM employees,departments
# 两个表的连接条件
WHERE employees.`department_id` = departments.department_id;
# 如果查询语句中出现了多个表中都存在的字段,则必须指明此字段所在的表。从优化的角度,建议多表查询值每个字段前都指明所在的表。
# 可以在from处给表起别名,在select和where中必须使用别名,不能使用别名(别名覆盖了 所以找到之后再筛选就找不到了)。
SELECT employees.employee_id,departments.department_name,employees.department_id
FROM employees,departments
WHERE employees.`department_id` = departments.department_id;
如果有n个表实现多表的查询,则需要至少n-1个连接条件
连接方式
等值连接和非等值连接
两个表之间的桥梁是一样的为等值连接
两个表之间的桥梁是一个范围等需要进行别的判断,不是单纯的值相等,称为非值连接。
自连接和非自连接
自引用,寻找的也在自己的群体里,此时思路一定要清楚逻辑上还是从两个表中寻找。
内连接和外连接
内连接:合并具有同一列的两个以上的表的行, 结果集中不包含一个表与另一个表不匹配的行。
外连接:合并具有同一列的两个以上的表的行, 结果集中除了包含一个表与另一个表匹配的行之外,还查询到了左表或右表中不匹配的行。
集合中只取交集,加上左边特有的,加上右边特有的。
左外连接:两个表在连接过程中除了返回满足连接条件的行以外还返回左表中不满足条件的行,这种连接称为左外连接。
右外连接:两个表在连接过程中除了返回满足连接条件的行以外还返回右表中不满足条件的行,这种连接称为右外连接。
出现所有字样的一定是外连接。
MYSQL不支持SQL92中的外连接语法(+)
SQL99语法中使用 JOIN ...ON 的方式实现多表的查询。这种方式也能解决外连接的问题。MySQL支持此种方式。
SELECT last_name,department_name
FROM employees e INNER JOIN departments d
ON e.`department_id` = d.`department_id`;
SELECT last_name,department_name,city
FROM employees e JOIN departments d
ON e.`department_id` = d.`department_id`
JOIN locations l
ON d.`location_id` = l.`location_id`;
LEFT JOIN
RIGHT JOIN
MySQL不支持 FULL OUTER JOIN,
UNION:会执行去重操作
UNION ALL:不会执行去重操作
如果明确知道合并数据后的结果数据不存在重复数据,或者不需要去除重复的数据,则尽量使用UNION ALL语句,以提高数据查询的效率。
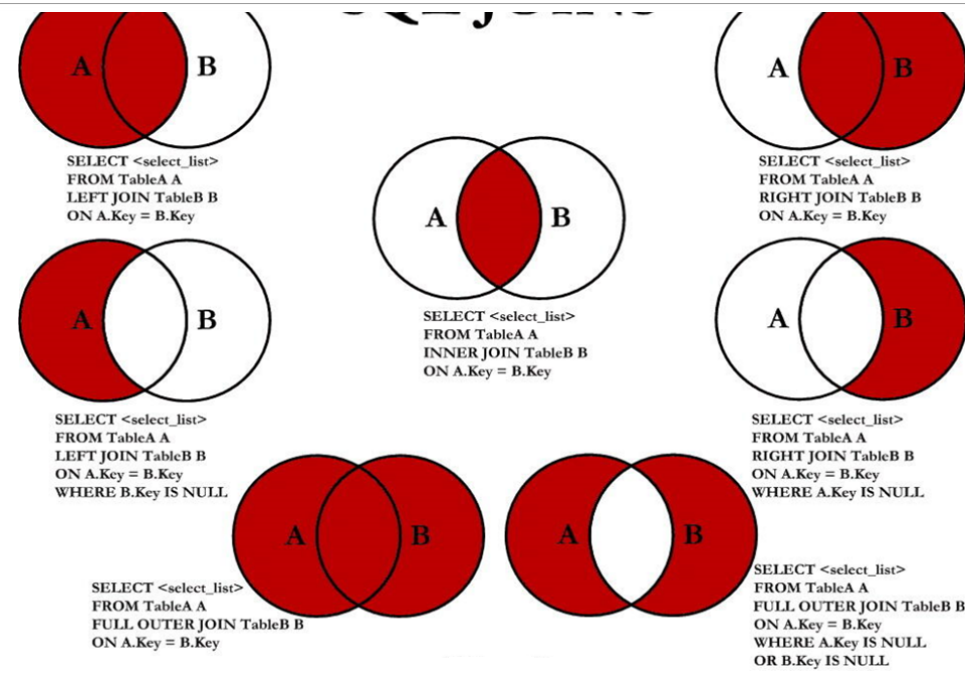
SELECT employee_id,department_name
FROM employees e LEFT JOIN departments d
ON e.`department_id` = d.`department_id`
WHERE d.`department_id` IS NULL
UNION ALL
SELECT employee_id,department_name
FROM employees e RIGHT JOIN departments d
ON e.`department_id` = d.`department_id`
WHERE e.`department_id` IS NULL;
函数
不同的DBMS支持的函数区别比较大,使用时要非常注意。
MySQL提供的内置函数从 实现的功能角度 可以分为数值函数、字符串函数、日期和时间函数、流程控制函数、加密与解密函数、获取MySQL信息函数、聚合函数等。
单行函数:输入一个输出一个,单行函数可以嵌套。
多行函数:输入多个输出一个
基本函数
#基本的操作
SELECT ABS(-123),ABS(32),SIGN(-23),SIGN(43),PI(),CEIL(32.32),CEILING(-43.23),FLOOR(32.32),
FLOOR(-43.23),MOD(12,5),12 MOD 5,12 % 5
FROM DUAL;
#取随机数
SELECT RAND(),RAND(),RAND(10),RAND(10),RAND(-1),RAND(-1)
FROM DUAL;
#四舍五入,截断操作
SELECT ROUND(123.556),ROUND(123.456,0),ROUND(123.456,1),ROUND(123.456,2),
ROUND(123.456,-1),ROUND(153.456,-2)
FROM DUAL;
SELECT TRUNCATE(123.456,0),TRUNCATE(123.496,1),TRUNCATE(129.45,-1)
FROM DUAL;
三角函数使用的是弧度值,所以要有弧度和角度的转换函数。
字符串函数
PAD是填充的意思,trim去除首尾空格的意思。
时间函数
涉及到对应操作去翻老师的课件。
流程控制函数
加密与解密的函数
PASSWORD()在mysql 8.0中弃用。
MD5和SHA是不可逆的,不能反推。实际使用的时候是直接带入MYSQL去带入比对。
#5. 加密与解密的函数
# PASSWORD()在mysql 8.0中弃用。
# MD5和SHA是不可逆的,不能反推。实际使用的时候是直接带入MYSQL去带入比对。
SELECT
MD5('mysql'),
SHA('mysql'),
MD5(MD5('mysql'))
FROM
DUAL;
MySQL信息函数
SELECT
VERSION(),
CONNECTION_ID(),
DATABASE (),
SCHEMA (),
USER (),
CURRENT_USER (),
CHARSET('尚硅谷'),
COLLATION ('尚硅谷')
FROM
DUAL;
聚合函数
输入多个,输出一个,类似统计函数。最大最小平均值求和(分清楚什么时候可以有字符串,字符串不能做加运算,但可以比大小)
然后是分组 GROUP BY函数
HEAVING 的使用
HAVING 必须声明在 GROUP BY 的后面,先分组后筛选。开发中,HAVING一般是依托于 GROUP BY的。
SELECT ....,....,....(存在聚合函数)
FROM ... (LEFT / RIGHT)JOIN ....ON 多表的连接条件
(LEFT / RIGHT)JOIN ... ON ....
WHERE 不包含聚合函数的过滤条件
GROUP BY ...,....
HAVING 包含聚合函数的过滤条件
ORDER BY ....,...(ASC / DESC )
LIMIT ...,....
SQL语句的执行过程:
FROM ...,...-> ON -> (LEFT/RIGNT JOIN) -> WHERE -> GROUP BY -> HAVING -> SELECT -> DISTINCT ->
ORDER BY -> LIMIT



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)