
使用卷积进行泛化 -- Pytorch深度学习实战 Chapter8
torchvision.transforms模块定义了一组可组合的、类似函数的对象,可作为参数传递到TorchVision模块的数据集,在数据加载之后,在 getitem()返回之前对数据进行变换。
个人整理并不完善,这一章看起来也有点费劲需要再多看几遍-_-
如果有人看到并且对此感兴趣的话,一定要去看原书啊!
卷积和池化
卷积为什么存在?
在最简单的神经网络里,就是类似线性方程组拟合参数,为了避免永远都是线性,引入了激活函数拟合非线性函数。以图片为例,里边的内容可能会不断平移,放大或缩小。拟合的网络泛化效果并不好,当然可以通过使用各种重新剪裁的图像强化训练数据,但参数太多的问题依然无法解决。
回到图片分类中,在分类中我们可能只关注某些部分,这些像素点的运算能够决定其最终的结局。那就只找离自己近的像素点部分进行加权!卷积就是这样,一种可以代替这种稠密的、全连接的仿射变换的线性操作。
其优点包括:邻域的局部操作,平移不变性,模型的参数大幅减少。
卷积等价于进行多重线性操作,它们的权重几乎在除个别像素外的任何地方都为0,并且在训练期间接收相同的更新。
卷积的构造
torch.nn模块提供一维、二维、三维的卷积,其中nn.Convld用于时间序列,nn.Conv2d用于图像,nn.Conv3d用于体数据和视频。
在实际使用过程中可以使用 unsqueeze()添加一个维度(来满足输入的维度要求),进行卷积时注意步长和边界,这决定着最后得到的张量大小是否会发生变化。
以下就是卷积学习的过程
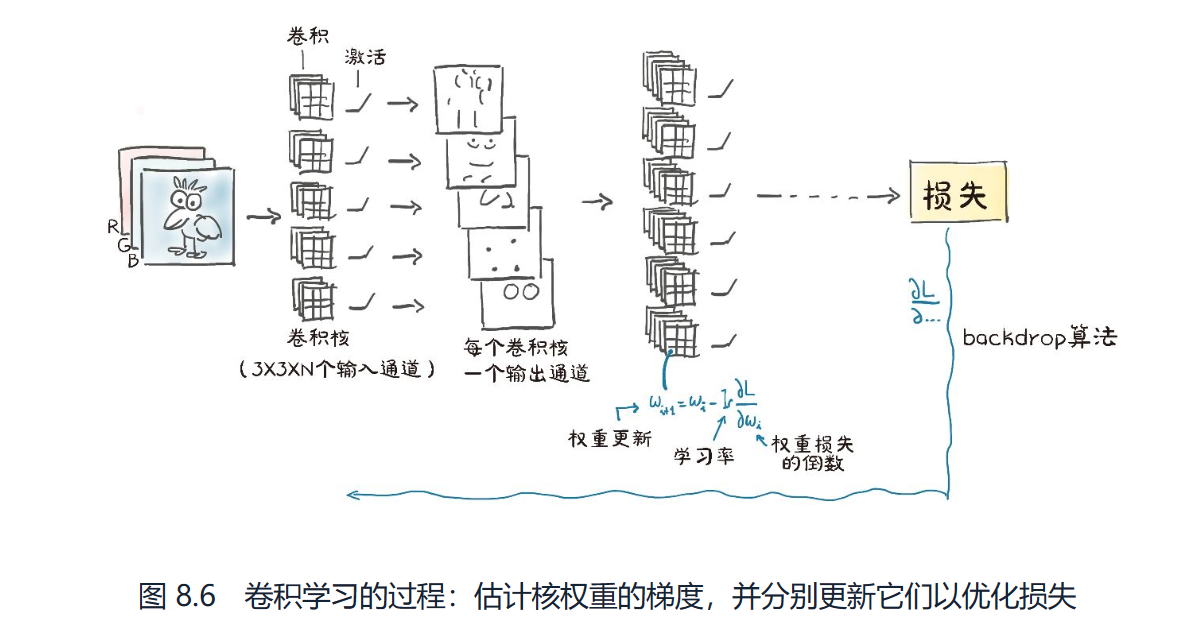
可以看出不同的卷积核有不同的特点,也会分析得到不同的特征(好像一个筛选器哦)
卷积之后
“筛选器”的效果乍一看很好,但是选用多大的孔来筛呢?如果数据的特征跨度很大,选用很大孔的筛子岂不是又返回到了全连接网络参数巨多的时代吗?
卷积神经网络中使用的另一种方法是在一个卷积之后堆叠另一个卷积,同时在连续卷积之间对图像进行下采样。原则上下采样可以不同的方式进行。将图像缩放一半相当于取4个相邻像素作为输入,产生一个像素作为输出。
如何根据输入值计算输出值取决于对应的设计:
取平均值(平均池化)现在已经不受欢迎了;
取最大值(最大池化)是目前最常用的方法之一,但有丢弃剩余数据的缺点;
使用带有步长的卷积,该方法只将每第 N 个像素纳入计算,依然包含着来自前一层所有像素的输入。文献显示了这种方法的前景,但还没有取代最大池化法。
最大池化由 nn.MaxPook2d 模块提供,与卷积一样也有一维和三维数据的版本。
感受野的感觉就像是这一个小数字承载了多少信息量(原来的多少小矩阵)
在构造对应的网络时,一定要对维度这些变换很熟悉,否则你也不知道到底是哪里出错了。因为在使用nn.Sequential时,没有以任何显式可见的方式展示每个模块的输出。
子类化 nn.Module
当我们想要构建模型来做更复杂的事情时,就需要自己造轮子,简单的nn.Sequential已经不能满足要求了。
PyTorch允许在模型中通过子类化nn.Module来进行任何运算。
为了子类化nn.Module,至少需要定义一个forward()方法,该方法接收模块的输入并返回输出。在PyTorch中,如果使用标准torch操作,自动求导将自动处理反向传播。事实上,一个nn.Module并不会自带backward()方法。
通常情况下运算将使用其他模块,例如内置的卷积或自定义的模块。为了包含这些子模块,通常在构造函数__init__()中定义它们,并将它们分配给self以便在forward()方法中使用。同时,它们将在模块的整个生命周期中保存它们的参数。注意在使用之前需要先调用super().init(),PyTorch也会进行提醒。
以下是一个具体的例子。
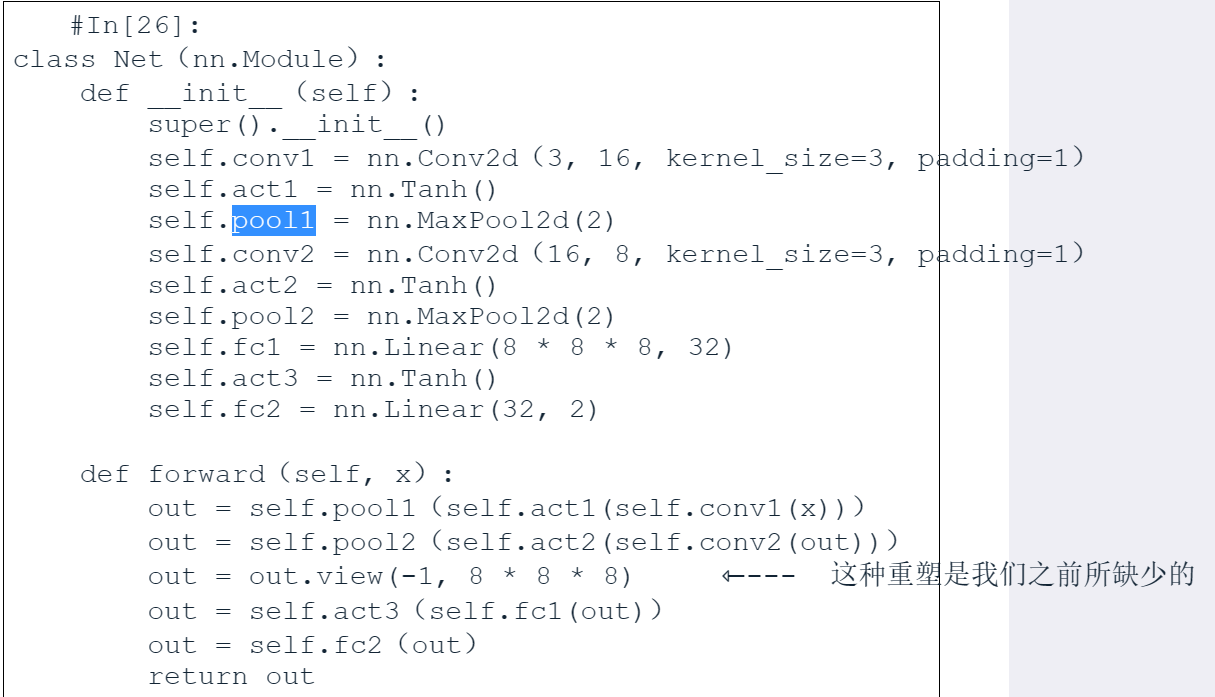
分类网络的目标通常是压缩信息,也可以说是从一个具有大量像素的图片开始,将其压缩到一个概率向量中。不同的收缩方式会有不同的优缺点和适用范围,在具体做选择时要想好。
函数式API和模块化API的区别,一个像函数一样输入什么输出什么是由代码决定的,一个进行了封装具备了一定功能。
需要依据不同的应用场景进行选择。

模型训练
模型训练包括以下基本步骤:
- 通过模型提供输入(正向传播)
- 计算损失(也是正向传播的一部分)
- 将任何老的梯度归零
- 调用loss.backward0来计算损失相对所有参数的梯度(反向传播)
- 让优化器朝着更低的损失迈进。

测试模型时,在测试集上进行测试。

模型保存
主要保存的是网络参数

调用

在GPU上训练
nn.Module模块实现了一个将模型所有参数移动到GPU上的to()方法,传递一个dtype参数时使用该方法还可以强制转换类型。
Module.to和Tensor.to之间的区别在于模块实例是否被修改。
Module.to:模块的实例会被修改,
而Tensor.to会返回一个新的张量。
其中一种比较好的做法是将参数移动到适当的设备之后再创建优化器。
如果GPU可用的话,把一切移到GPU上是一种很好的方式。
一个好的模式是根据torch.cuda.is available来设置一个变量device的值。然后可以通过Tensor.to()方法把数据加载器得到的张量移动到GPU上来修正训练循环。
模型修正(宽度)
为每一层指定的通道和特征的数量与模型中参数的数量直接相关,在其他条件相同的情况下,二者是正相关的关系。
模型容量越大,模型输入的可变性就越大,过拟合的可能性也越大(模型可以使用更多的参数来记忆输出中不重要的方面,颇有大材小用之感)
对抗过拟合的最好方法是增加样本数量,或者在没有新数据的情况下,通过人工修改相同的数据来增加现有数据。
此外,还可在模型级别上使用其他技巧控制过拟合。
训练模型涉及2个关键步骤:一是优化,当我们需要减少训练集上的损失时;二是泛化,当模型不仅要处理训练集,还要处理以前没有见过的数据,如验证集时。旨在简化这2个步骤的数学工具有时被归入正则化的标签之下。
正则化 -- 稳定泛化
添加正则化项是为了减小模型本身的权重,从而限制训练对它们增长的影响。即对较大权重的惩罚。这使得损失更平滑,并且从拟合单个样本中获得的
收益相对较少。较流行的正则化项是L2正则化,它是模型中所有权重的平方和,而L1正则化是模型中所有权重的绝对值之和9。它们都通过一个(小)因子进行缩放,这个因子是在训练前设置的超参数。
Dropout -- 不太依赖于单一输入
Dropout背后的思想:将网络每轮训练迭代中的神经元随机部分清零。

在训练过程中使用Dropout,而在生产过程中评估一个训练模型时,会绕过Dropout,.或者等效地给其分配一个等于0的概率。这是通过Dropout模块的train属性来控制的。回想一下,PyTorch允许我们在任意nn.Model子类上通过调用model..train(或model.eval0来实现2种模式的切换。调用将自动复制到子模块上,这样如果其中有Dropout,,它将在随后的前向和后向传递中表现出相应的行为。
批量归一化 (Batch Normalization) -- 保持激活检查
神经网络批量归一化(Batch Normalization,简称BN)是一种在深度神经网络中常用的技术,它的主要目的是加速训练、减少过拟合以及提高泛化性能。BN的基本思想是对每一层的输入进行归一化,使得每个特征的均值和方差都接近于0和1。在神经网络中,BN通常被插入在非线性变换(如ReLU)之后、卷积层和全连接层之前。
BN的操作步骤如下:
-
对于一批训练数据中的一个小批量,计算其每个特征的均值和标准差。
-
使用这个小批量的均值和标准差对该批次数据进行归一化操作。
-
将归一化后的数据进行缩放和平移,使其能够适应网络中后续层的非线性变换。
-
最后,将缩放和平移的结果作为该层的输出。
BN的优点是能够使得网络对输入数据的分布变化更加鲁棒,从而加速网络的收敛速度、降低过拟合的风险、提高网络的泛化能力。同时,BN的操作简单,容易集成到各种类型的神经网络中。
模型修正(深度)
宽度是使模型更大、在某种程度上更有能力的第一个维度。深度则是第二个维度,随着深度的增加,网络能近似的函数的复杂性也会增加。在计算机视觉中,较浅的网络可以识别照片中一个人的形状,而较深的网络则可以识别这个人,甚至一个人上半身的脸以及租宝。当我们需要理解上下文以便对某个输入进行说明时,深度允许模型处理层次信息。
跳跃连接
神经网络中的跳跃连接(Skip Connection)是一种用于连接不同层的网络结构,其背后的思想是将低层的信息传递到高层,以便于网络在训练中更好地学习特征。
传统的神经网络模型是通过层层叠加来逐渐提取特征的,但是在一些深层次的模型中,由于信息在层与层之间的流动过程中可能会被逐渐稀释和丢失,因此导致训练变得更加困难,容易出现梯度消失和梯度爆炸等问题。
跳跃连接通过将底层的信息直接传递到高层中,可以有效地增加信息流动的路径,从而提高模型的表现力和鲁棒性。在跳跃连接的结构中,底层的特征图被简单地与上层特征图相加,然后送入激活函数进行非线性变换。
跳跃连接的应用可以减少网络的层数,提高网络的效率,并且在许多计算机视觉任务中都有很好的表现,如图像分类、目标检测、图像分割等。另外,跳跃连接也被广泛应用于各种深度学习框架中,如ResNet、DenseNet等。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人