
离线强化学习 Offline Reinforcement Learning 之 BEAR 算法
BEAR Bootstrapping Error Accumulation Reduction
时间:2019 NIPS Conference and Workshop on Neural Information Processing System
题目:Stabilizing Off-policy Q-Learning via Bootstrapping Error Reduction
作者:Arival Kumar等
本文主要是记录一些自己在读上述论文时的笔记~
Motivation
众所周知强化学习 on-policy 水到渠成,学到什么策略就去试探然后改进,最后得到最优策略。为了提高样本利用率,我可以来学习你的经验这就是 off-policy。所有的经验都可以实时获取实时改变,这就是 online。你只有你现在有的,这就是 offline。从一些不是你的东西的东西中学到属于你的东西必然是提升样本效率的一大利器,所以 offline RL 这么火也是必然的(毕竟还是要落地的)。
off-policy数据不更新不就是offline吗,所以本文提出的方法也属于offline RL。

贝尔曼算子积累的bootstrapping error 是本文思路的切入点。
主要思路
当我们将话题转向数据不更新的 off-policy 强化学习时,(限定下讨论范围为 value-based)问题自然转向为什么有些动作状态对的值会估计不准确。这正是由于数据不更新,如果本来就没有这个 只靠你自己拟合出来的值函数泛化,自然就容易出问题(你也不一定能猜对啊),即为 out-of-distribution inputs。本文就是针对该情况形式化并分析了从非策略数据学习时不稳定和性能差的原因。并表明通过仔细的动作选择,可以减轻通过Q函数的错误传播。具体提出的方法就是基于支撑集概念的BEAR算法。“Our approach is motivated as reducing the rate of propagation of error propagation between states.”
论文试验表明该方法在连续控制MuJoCo任务上的有效性,包括各种非策略数据集:由随机、次优或最优策略生成。BEAR对训练数据集始终具有鲁棒性,在所有情况下都匹配或超过最新技术,而现有算法仅对特定数据集表现良好。
误差分析
background 部分 属于强化学习常规知识介绍,在此不做赘述。
重点分析下误差的产生,文中给出了贝尔曼误差和第\(k\)次迭代的总误差之间的关系

根据之前的描述,在那些 OOD 状态和动作上,他们的贝尔曼误差自然就大(因为没有出现 所以从未优化过)
为了减轻自举错误,可以限制策略确保它输出支持训练分布的操作。这与BCQ不同,后者隐式地限制学习策略的分布,使其接近行为策略,类似于行为克隆。虽然这足以确保动作以高概率出现在训练集中,但限制性太强。例如,如果行为策略接近统一,则学习的策略随机性较强导致性能不佳,即使数据足以学习强策略。
受上述情境的影响,我们可以限制动作,但不限制其值与行为策略得到的一致。【这样就可以从大部分次优动作少部分最优动作中也能选出好的动作,而不局限于和行为策略一样,不知道这么理解对不对,有想法的朋友可以多多提出建议互相讨论一下。】当然,一些很稀有的动作弄出来还是不太好拟合,所以就引入支撑集的概念,筛去那些很少见的动作。
我们希望的不是学到的policy与数据集中的behavior policy越像越好,而是policy在behavior policy的支撑集的范围内进行优化。所以本文的思想转化为把对policy的constraint变成让policy保持在behavior policy的支撑集内。
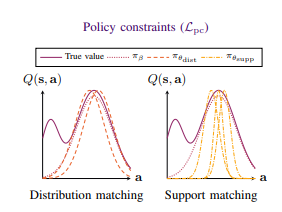
算法理论
Distribution-Constrained Backups
(Define and analyze a backup operator that restricts the set of policies used in the maximization of the Q-function.)
Distribution-constrained operators
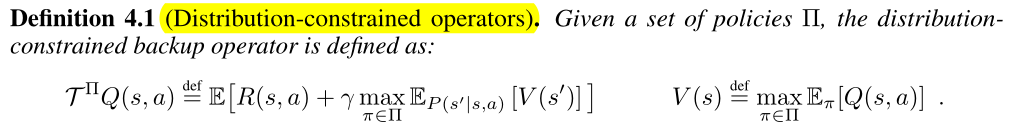
【解决策略集定义及收敛】在给定的策略集上定义了一个新算子,该算子满足标准贝尔曼算子的属性(收敛到不动点)。为了分析在近似误差(approximation error)下执行该备份的(次)最优性,量化了两个误差源:suboptimality bias 和 suboptimality constant。
- 最优策略可能位于策略约束集之外,此时找到的是次优解。
- 次优常数用来衡量最终解中的次优性。
【为什么是这两个部分?】
suboptimal constant
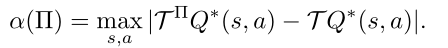
concentrability coefficient
量化 ∏ 策略生成的访问分布与训练数据分布的距离。该常数表示状态和动作OOD的程度。

这里的定义还需要分析一下
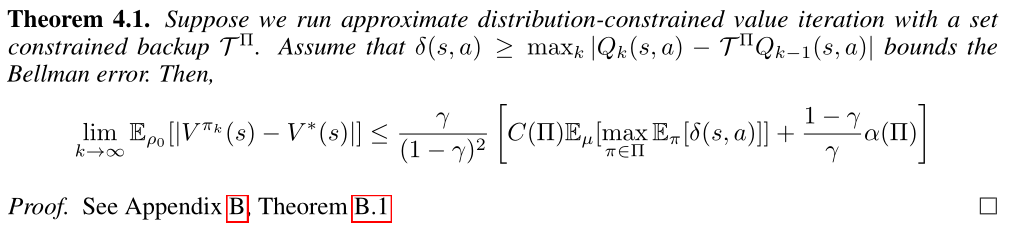
定理 4.1 对新算子对应的值函数误差上界进行刻画:既要将更新期间选择的策略保持在接近数据的位置,还要保持策略集足够大以得到性能良好的策略。
上述主要介绍的是策略集下的算子和其误差的分析,那么该如何构造策略集呢?这就引出了支撑集的概念

在这种定义下就可以对concentrability coefficient 的范围进行限制,有以下定理。

这类方法的好处在下边这段进行了阐述。

算法介绍
思路
需要注意的一点是该算法是在SAC框架上进行修改的,在这一小节第一段就点明了该算法具体的改进环节在 AC 的哪个部分。

如上所述,主要通过 K 个 Q 函数和寻找策略集的约束来实现 SAC 中的策略改进步骤。
· 策略的更新目标也定义为在约束集上的(K个Q函数中最小的)中的最大的动作状态值函数

· 在对策略集进行约束时,采用MMD距离来实现。

归纳
最终,结合上述两个组成部分就将问题转化为以下式子。

最终算法流程如下

对算法的解读方面,参考链接1比较全面。
“
- line5 更新Q函数时使用的是各个Q函数的凸组合
- line8 更新policy时使用的是equation1中带约束的梯度策略
- 基于AC框架,使用梯度下降更新可以解决连续空间问题(当然本身是Q-learning,自然可以解决离散空间)
4.5. 这两条暂时还没有看懂
”
参考链接
- 【论文笔记】BEAR: 通过减小Bootstrapping Error来进行离线RL学习 - Eric Liu的文章 - 知乎 https://zhuanlan.zhihu.com/p/250498558
- 【论文笔记 6】BEAR - Tairan He的文章 - 知乎 https://zhuanlan.zhihu.com/p/266707283
- 【离线强化学习(Offline RL)系列3: (算法篇)策略约束- BEAR算法原理详解与实现 - 旺仔搬砖记的文章 - 知乎https://zhuanlan.zhihu.com/p/493490905
