

序列蒙特卡罗(Sequential Monte Carlo)
发现网上看到的序列蒙特卡罗的中文理解很少,就稍微整理一下自己看到的,欢迎讨论~
内容引入
许多现实世界的数据分析任务都涉及从一些给定的观察数据中估计预测未知的数据。大多数应用场景下可以使用一些先验知识来辅助建模,即贝叶斯模型【通过未知量的先验分布以及与这些量与观测值相关的似然函数得到后验分布来刻画和分析一些东西】。通常情况下,观测数据是按时间顺序记录的,这有助于执行在线推理,不断更新后验分布。使用雷达测量跟踪飞机、使用噪声测量估计数字通信信号、使用股票市场数据估计金融工具的波动性等都属于此类情况。
序列蒙特卡罗的另一种叫法是粒子滤波【利用粒子集来表示概率,通过寻找一组在状态空间中传播的随机样本来近似表示概率密度函数,用样本均值代替积分运算,获得系统状态的最小方差估计过程】。
不得不提的一个是卡尔曼滤波 -- 用线性高斯状态空间模型对数据进行建模,推导出精确的解析表达式来计算后验分布的演化序列。还有一个是隐马尔可夫模型HMM滤波器,将数据建模为部分观察的有限状态空间马尔可夫链,也有可能得到一个解析解。这两个滤波器在实际中是最为普遍和著名的,但在解决实际问题时,我们得到的数据通常涉及非高斯性、高维性和非线性因素,一般得不到解析解。这是一个渗透在大多数科学学科中的基础性的重要问题。根据感兴趣的领域,出现了许多不同的名称,包括贝叶斯过滤,最优(非线性)过滤,随机过滤和在线推理与学习。三十多年来,为了解决这一问题,人们提出了许多近似方案,如扩展卡尔曼滤波、高斯和逼近和基于网格的滤波器。前两种方法没有考虑到所考虑过程的所有显著统计特征,常常导致较差的结果。基于网格的过滤器。基于确定性数值积分的方法,可以得到精确的结果,但很难实现,计算代价太高,在高维中没有任何实际应用。
而序列蒙特卡罗 (Sequential Monte Carlo)是一种基于仿真的方法,为计算后验分布提供了便捷,不一定非要计算出显式结果。
模型描述
使用来描述信号,来描述观测值。我们的目的是在时间上递归估计后验分布及其相关特征(均值、方差、协方差等)。
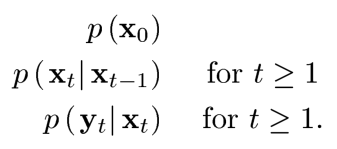
理论上带入贝叶斯公式,都可以计算和预测,具体公式如下:

由于上述常数、后验边缘等涉及高维积分,真的不好计算。大家想了很多办法来近似分布进行抽样估计,如重要性抽样、顺序重要性抽样等。
重要性采样(Importance Sampling)
在之前整理蒙特卡罗离线策略的时候有过汇总 ,这里就不详述啦(有想看的可以在之前发过的文章中看到)
一句话总结就是引入一个比较好产生的变量作为中间桥梁,来实现对另一个变量的采样来计算均值。
序列重要性采样(Sequential Importance Sampling)
在重要性采样的基础上对序列进行采样的方法。随着时间的增加,重要性权重变得越来越倾斜,最后可能退化为只有少数粒子具有非零权重。为了避免重要性权重的退化,引入了重采样步骤。
The Bootstrap filter
重采样是在每次权重更新之后,根据当前权重对所有粒子进行重采样,之后将所有权重设定为相同。使用粒子数量代替了粒子权重,避免了权重不均匀情况的出现。
示意图如下所示:
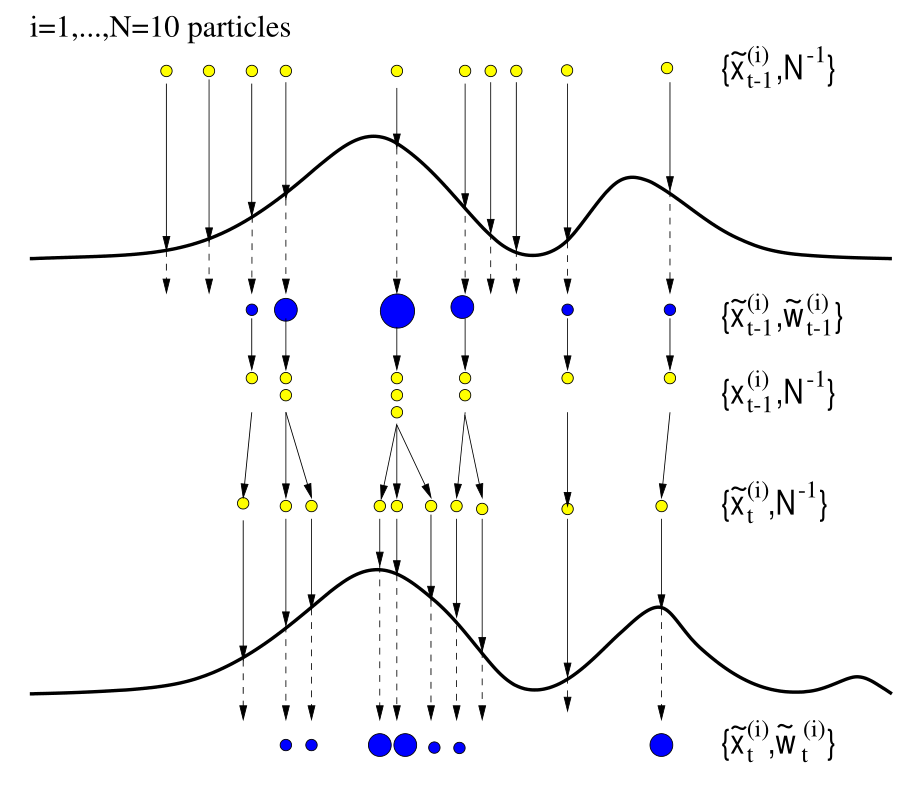
包含重采样的序列重要性采样
以下是算法流程图:

可以理解为是上边图的延伸,从一维扩展到高维即可。
总结
感觉讲的也不是很多,初步印象是从蒙特卡罗一组序列的转移中加深到了两组序列的关系,从一组已知的序列中转化到另一组中,中间用到了重要性采样和重采样的方法。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix