强化学习之基于函数逼近的同轨策略预测(二)-- 随机梯度和半梯度方法
注:本节内容是对Sutton的《Reinforcement Learning:An Introduction》第九章的理解整理~ 这里是第三节
回顾之前所说,我们希望能够找到比较好的函数参数使得逼近效果尽可能地好(给出了状态重要性分布),接下来这一节讨论的是可以使用什么方法来逼近呢?
一定要记住一点:函数逼近改变的自变量是权重\(w\),因变量是我们设置的衡量标准。优化问题转化为找到比较好的权重\(w\)使得“损失函数”达到最小。【这就和最优化梯度法里的搜索方向啊、最优步长之类的联系到了一起】
当然,面对这种无约束优化问题,最简单的莫过于最速下降法、牛顿迭代法之类的梯度方法。书中介绍的是随机梯度法。
随机梯度和半梯度方法
在一系列的离散时刻对权重\(w\)进行更新,定义符号\(w_t\)为每个时刻的权重向量。每一步都有可能得到新样本(可能是随机选择的状态以及在给定策略下的真实价值)。采用随机梯度下降法对上述问题进行求解。\(w_t\)迭代公式如下:
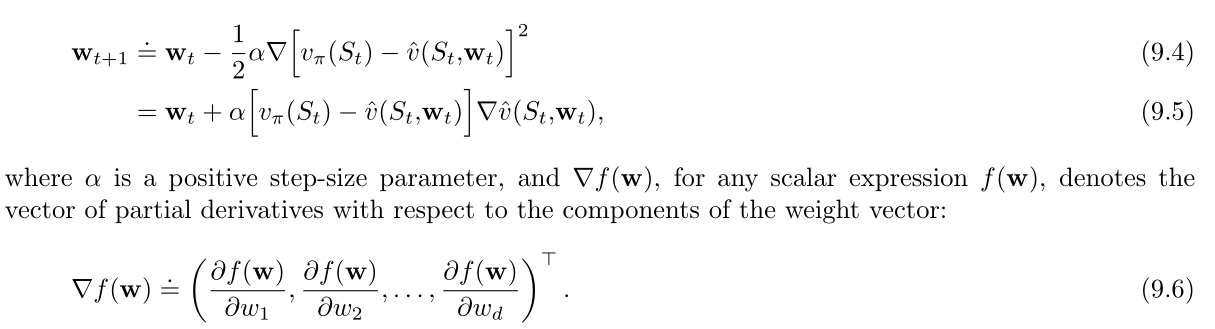
之所以被称之为随机体现在更新仅仅依赖于一个样本来完成,而且该样本很有可能是随机选择的。
针对上述问题,如果所有的数据都是真实的,那么对梯度做一定的要求,采用随机梯度下降法一定可以找到局部最优解。但事实并不总是这样。
如果第\(t\)个训练样本\(S_t→U_t\)的目标输出\(U_t\)不是真实的价值\(v_{\pi}(S_t)\),而是它的一个随机近似。在这种情况下,由于\(v_{\pi}(S_t)\)未知,不能使用上述的更新公式进行更新,但可以用\(U_t\)近似取代\(v_{\pi}(S_t)\),我们可以有以下公式:
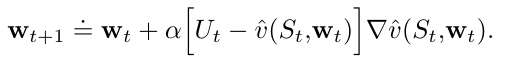
-
如果使用蒙特卡罗中的\(G_t\)来近似表示\(v_{\pi}(S_t)\),是一个无偏估计。那么蒙特卡洛状态价值函数预测的梯度下降版本可以保证找到一个局部最优解。具体步骤如下:

-
如果使用\(v_{\pi}(S_t)\)的自举估计值作为目标的\(U_t\),就无法得到同样的最优性条件保证。自举目标每一次的值取决于权值向量当前的值,这样的估计是诱骗的,无法实现真正的梯度下降法。【这一步的关键取决于那个函数求导的等号是否成立?】在实际应用中,只考虑了改变全职向量\(w_t\)对估计的影响,忽略了对目标的影响。由于只包含了一部分梯度,该方法被称之为半梯度。
以下是对半梯度方法的优缺点分析和半梯度TD(0)的算法步骤


状态聚合
字面意思上理解,状态聚合的意思是将一些相似的状态放在一起方便讨论,降低问题求解复杂度。可以看做是一种简单形式的泛化函数逼近。
在这里使用的估计函数为\(v(S_t. w_t) = w_i\) 相当于将前边的计算过程进行简化。【每个组对应一个估计值(对应权值向量w的一个维度分量),状态的价值估计就是所在组对应的分量。当状态被更新时,只有这个对应分量被单独更新】
只是人为制造的一个特殊函数!
