强化学习之基于表格型方法的规划和学习(三)-- 期望更新与采样更新
注:本节内容是对Sutton的《Reinforcement Learning:An Introduction》第八章的理解整理~ 这里是第四、五节
在这一章的脉络中,首先将有模型和无模型的方法联系起来,平衡了真实经验和模拟经验,给出了使用表格型方法求解的基本模型,对环境进行统一。然后讨论了环境发生变化时模型的改进方法。
通过以上思路可以基本解决大部分问题。
那么在可以解决问题的基础上,我们就开始思考如何能让问题求解得更快的问题:模拟转移和状态更新集中在某些特定“状态-动作”二元组上,规划是否会更有效?
以下介绍(经验)优先遍历的相关情况:
优先遍历
之前介绍的Dyna智能体,模拟转移是从之前经历过的状态中随机挑选,均匀采样。但均匀采样不一定是最好的,尤其是面对稀疏奖励,随机采样可能会更新很多无效状态,在达到一个有效更新之前将进行很多次无效更新。所以算法在此基础上可以进行一定的改良:如果可以集中在某些特定的二元组上,效率可能会更加高效。【有聚焦的感觉了】
反向聚焦
这个名字很有从终点目标工作进行反向工作的意味。但思想不应仅仅局限在这里,目标状态只是一种特殊情况,便于启发思考。A影响B,从B的变动对A进行推断,就算是一种反向,有由果溯因的感觉了。
说到底就是衡量哪个状态更新能够更快收敛。根据某种更新迫切性的度量对更新进行优先级排序是很自然的。这就是优先级遍历背后的基本思想。
例如:如果某个二元组在更新之后的价值变化是不可忽略的,就可以将它放入优先队列进行维护,这个队列是按照价值改变的大小来进行优先级排序的。
前向聚焦
同样,聚焦 从前 从后 从所有你认为重要的地方都可以开始。这些思想可以看做是加快收敛的一些小技巧。
期望更新与采样更新的对比
解决了模型更新如何跳转的问题后,我们将问题聚焦于状态的更新方式。经过之前的总结,有期望更新和采样更新两种方式。
期望更新会考虑所有可能发生的转移,采样更新则仅仅考虑采样得到的单个转移样本。
【要是把这两种更新结合到一起会怎么样?】
对价值函数的更新方式可以从以下几个维度进行划分:更新状态价值还是动作价值?所估计的价值对应的是最优策略还是任意给定策略?采用期望更新还是采样更新?
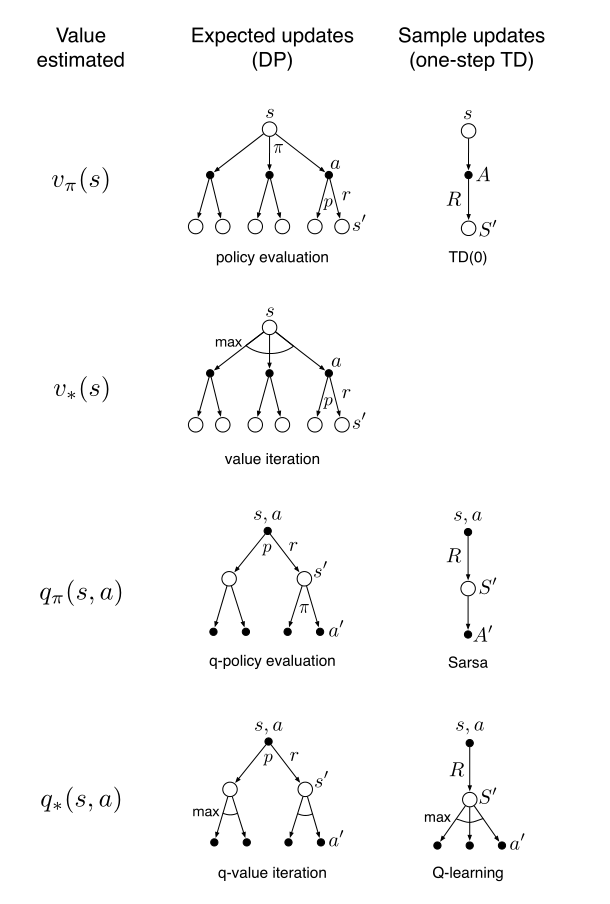
优缺点分析
我们知道,所有事情知道的信息越全面,做出的决策和估计就在一定程度上越准确。在算力允许的情况下,自然是期望更新优于采样更新。采样更新状态的正确性只决定于后继状态的正确性。采样更新除此之外还会受到其它错误的影响。
但是对于拥有很大的随机分支因子并要求对大量状态价值准确求解的问题,采样更新可能比期望更新要好。
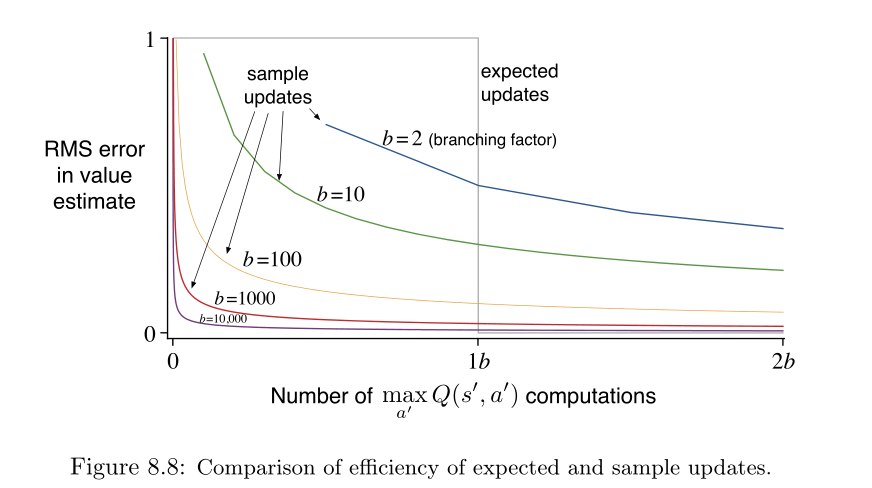
上图展示的是不同的分支因子\(b\)下,采用采样更新和期望更新估计准确率统计。其中灰色线是期望更新的计算次数,可以看出不管什么情况都是b次。
采样跟新则随着分支因子的变化出现一定的变化,这论证了之前的说明。
