强化学习之基于表格型方法的规划和学习(二)-- 环境改变
注:本节内容是对Sutton的《Reinforcement Learning:An Introduction》第八章的理解整理~ 这里是第三节
上一节讲到使用Dyna算法将学习和规划结合到一起,实现在线规划:一边与环境交互积攒经验,一边利用经验对当前情况进行总结寻找下一次与环境交互的合适动作。填充的都是完全正确的信息。
那么当环境发生变化,新的动态特性未被观察到或模型是通过泛化能力较差的函数来近似等情况发生时,规划过程可能会计算出次优的策略。
根据环境的变化情况,我们可以分为环境变得更恶劣,环境变得更乐观。
这里的环境变得更乐观可以理解为出现了新的最优解,原来的解依然可以成立,规划次数过多则很难找到新路。恶劣反之,原来的路行不通就可以放弃规划好的路线重新开始探索。
When the Model Is Wrong
屏障迷宫(恶劣)
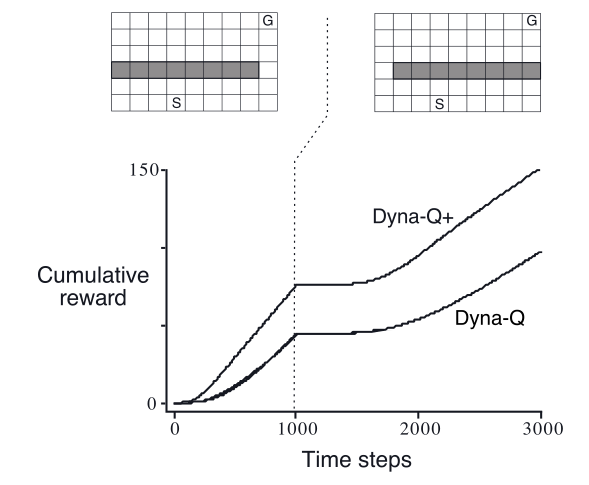
从图中可以看出在前一段时间迷宫处于一种状态,过一段时间环境发生变化,曲线代表了智能体的累积奖励。
在这种情况下,前一段时间计算出来的最优策略(从右边走)在后一段时间内并不适用。智能体按照这个策略走的时候会发现这些机会根本不存在,所以会感知到模型错误,进而修正。
捷径迷宫(乐观)
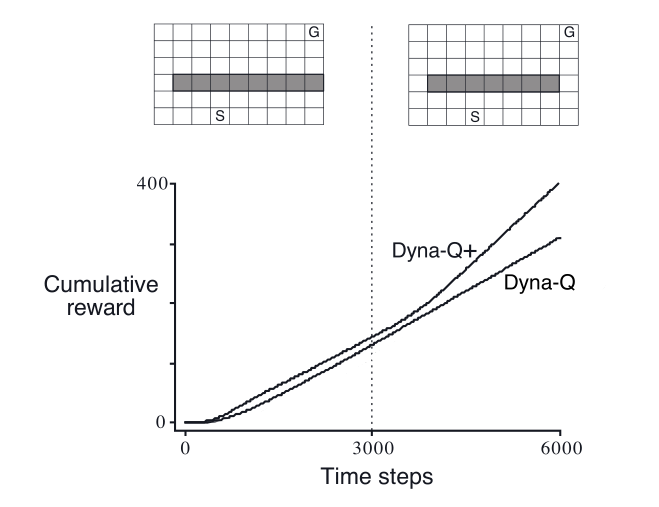
当环境变得比以前更好(出现了更好的路),但以前的正确策略并没有反应出这些改善时,学习会遇到很大困难(根本就不会过去试探)。在这类情况下,建模错误可能在很长一段时间都不会被检测到。
说到底还是试探与开发之间的矛盾。在“规划”意义下,“试探”意为着尝试那些改善模型的动作,而“开发”意味着以当前模型的最优方式来执行动作。
所以书中提到了一种解决方法就是在Dyna+的基础上增加了额外的试探收益来鼓励试探性动作。
改进方式如下:

补充:启发式方法
启发式方法是指人在解决问题时所采取的一种根据经验规则进行发现的方法。其特点是在解决问题时,利用过去的经验,选择已经行之有效的方法,而不是系统地、以确定的步骤去寻找答案。
启发式(需要灵机一动的感觉)
它解决问题的方法与算法相对立。算法是把所有可能性都尝试一次,最终能找到问题的答案。需要在很大的解空间中寻找最优解,花费大量的时间和精力。启发式方法是在有限的搜索空间内,大大减少尝试的数量,迅速解决问题。
