强化学习之基于表格型方法的规划和学习(一)-- 学习和规划
注:本节内容是对Sutton的《Reinforcement Learning:An introduction》第八章的理解整理~ 这里是前两节
如何从统一视角来考虑一系列强化学习方法?
稍微整理一下之前分享整理的强化学习思路:
- 具备完整的环境模型,我们使用贝尔曼方程(解方程或仿真求解)得到状态函数,与之对应就知道了最佳动作。【基于模型的强化学习方法】
- 不具备好表述的环境模型,我们使用蒙特卡罗模拟、TD(1步 n步等)来对这一过程进行模拟,计算动作状态对的值,从而选择出最优策略。【无模型的强化学习方法】
划重点:基于模型的方法将规划作为其主要组成部分,无模型的方法主要依赖于学习。接下来的所有都将围绕这句话进行阐释。
什么是环境模型?
既称之为模型,那一定是在模拟刻画一些东西衍生出来的。环境模型就是模拟环境对智能体的动作做出反应。这种反应就包括两种:分布模型(相当于站在上帝视角,把所有可能的结果和概率进行呈现 并从中随机选取)和样本模型(站在智能体的角度,做了这件事情产生了什么结果?只有当下的结果 不可能了解全局。当然 次数足够多另当别论)
给定一个初始状态和一个策略,一个样本模型可以生成整幕事件,一个分布模型可以生成所有可能的事件幕和它们发生的概率。
什么是规划?
来个百度解释:个人或组织制定的比较全面长远的发展计划,是对未来整体性、长期性、基本型问题的思考和考量,设计未来整套行动的方案。规划是融合多要素、多人士看法的某一特定领域的发展愿景。
一句话解释:用现有信息做出尽可能好的决策。【规划指的是基于当前已有的信息作出最好的选择,学习是在与环境交互从中找到最好的】
那么在我们这个领域中,主要使用术语来代表任何以环境模型为输入,并生成或改进与它交互的策略的计算过程。重点放在生成与改进策略上。
在人工智能中的分类
- 状态空间规划:可将其视为一种搜索方法,在状态空间中寻找最优策略或实现目标的最优决策路径。每个动作都会引发状态之间的转移,价值函数的定义和计算都是基于状态的。
- 方案空间规划:规划在方案空间中进行。方案空间的规划包括进化算法和“偏序规划”。很难有效应用于随机性序列决策问题中,不太适合解决强化学习中的问题。
在这里我们需要达成一个共识:所有的状态空间规划算法都有一个通用的结构。它们之间的不同主要在于所作的回溯操作、执行操作的顺序以及回溯的信息被保留的时间长短上有所不同。
【所有的状态空间规划算法都会利用计算价值函数作为改善策略的关键中间步骤;它们通过基于仿真经验的回溯操作来计算价值函数】

学习和规划之间的关系
学习方法和规划方法的核心是通过回溯操作来评估价值函数。不同之处在于,规划方法利用模拟仿真试验产生的经验,学习方法使用环境产生的真实经验。这种差异导致了评估性能、产生丰富经验等方面会有所不同,但通用的结构则说明许多思想和方法可以在规划和学习之间迁移。
【下面这个例子是基于单步骤表格型的Q学习和样本模型的随机采样方法,被称为随机采样单步表格型Q规划算法】

Q-planning与Q-learning之间的区别在于规划是利用采样模型和环境交互而不是直接和环境交互。
Dyna:集成在一起的规划、动作和学习
实现 在线规划
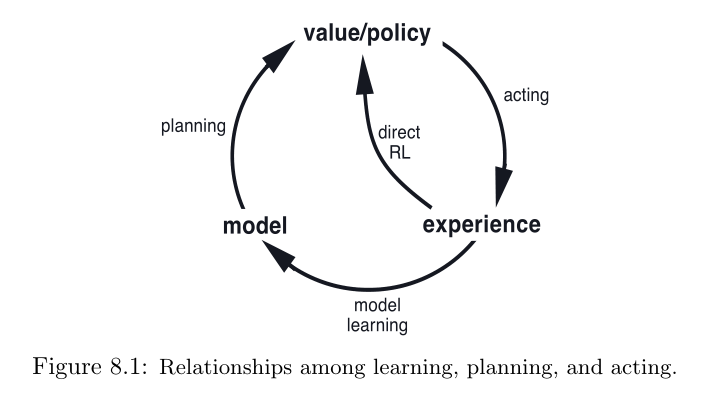
一句话简述就是:在线交互即智能体与环境交互。从交互中获得的新信息可能会改变模型,从而在规划过程中产生相互作用。
在上图中出现了模型学习(大圈)和直接强化学习(小圈)
【这里提到的模型学习方法也是基于表格的。每一次转移发生后,模型在自己的表格中记录状态和转移结果。实际上可以理解为历史数据?】
表格型Dyna-Q算法

该算法中前四步是学习,第五步是模型学习,第六步是在规划。可以并行学习,无本质区别。
