强化学习代码之Gridworld
前言
主要参考的是《Reinforcement Learning: An introduction Second Edition》这本书里的例子
英文版地址:http://incompleteideas.net/book/first/ebook/the-book.html
代码源文件可以参考这篇回答:https://zhuanlan.zhihu.com/p/79701922 采用Matlab实现【这个问题采用的是Python代码实现的 主要是用字典存储比较方便】
问题描述
该问题主要是对贝尔曼方程的应用,考量策略以及对环境的把握。
问题描述:有限MDP决策问题,实现方格跳转(上下左右);如果走到A处,会直接跳到A',奖励为10;如果走到B处,下一步会直接跳到B',奖励为5。走出整个方格,奖励为-1。否则,奖励为0。学习率\(\gamma\)为0.9。计算状态值函数\(v_{\pi}\)。
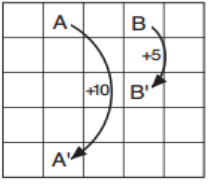
问题假设:问题简单,规则明了,无假设。
问题分析:状态(25个方格)、动作(上下左右)、转移规则(上下左右分别变化到了什么状态)
代码实现
代码思路:
- 找不同,状态之间的区别:边际与中心、A B点与其它点。特殊情况需要特殊对待。(心里先有个底)
- 初始化 网格尺寸、状态A和状态B的位置、学习率、状态值等。
- 每个状态都要设计自己的动作和策略。(注意存储 这里使用的是Python中的字典结构)动作集、动作概率 构造字典添加在每个状态网格中。
- 定义奖励,根据题目中给出的奖励内容进行设置即可。(状态转移规则 和 奖励规则)
- 贝尔曼方程估计值函数,计算最优值函数。(带入公式即可)
#######################################################################
# Copyright (C) #
# 2016 Shangtong Zhang(zhangshangtong.cpp@gmail.com) #
# 2016 Kenta Shimada(hyperkentakun@gmail.com) #
# Permission given to modify the code as long as you keep this #
# declaration at the top #
#######################################################################
from __future__ import print_function
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.table import Table
WORLD_SIZE = 5 #网格尺寸
A_POS = [0, 1] #状态A的位置
A_PRIME_POS = [4, 1] #状态A’的位置
B_POS = [0, 3] #状态B的位置
B_PRIME_POS = [2, 3] #状态B’的位置
discount = 0.9 #折扣率
world = np.zeros((WORLD_SIZE, WORLD_SIZE)) #值表格初始化为0
# left, up, right, down
actions = ['L', 'U', 'R', 'D'] #动作集
actionProb = [] #动作概率
for i in range(0, WORLD_SIZE):
actionProb.append([]) #产生新的一行,append()方法用于在列表末尾添加新的对象
for j in range(0, WORLD_SIZE):
actionProb[i].append(dict({'L':0.25, 'U':0.25, 'R':0.25, 'D':0.25}))#某一行中有WORLD_SIZE个字典
nextState = [] #下一个状态
actionReward = [] #奖赏值
##定义问题约束的奖赏值
for i in range(0, WORLD_SIZE):
nextState.append([])
actionReward.append([])
for j in range(0, WORLD_SIZE):
next = dict()
reward = dict()
if i == 0:
next['U'] = [i, j] #对于第0行的状态,采取“向上”动作后,留在原地,即下一状态=原状态
reward['U'] = -1.0 #得到奖赏值为-1
else:
next['U'] = [i - 1, j] #对于其他行的状态,采取“向上”动作后,下一状态为上一行,相同列的状态
reward['U'] = 0.0 #得到奖赏值为0
if i == WORLD_SIZE - 1:
next['D'] = [i, j] #对于第4行的状态,采取“向下”动作后,留在原地,即下一状态=原状态
reward['D'] = -1.0 #得到奖赏值为-1
else:
next['D'] = [i + 1, j] #对于其他行的状态,采取“向下”动作后,下一状态为下一行,相同列的状态
reward['D'] = 0.0 #得到奖赏值为0
if j == 0:
next['L'] = [i, j] #对于第0列的状态,采取“向左”动作后,留在原地,即下一状态=原状态
reward['L'] = -1.0 #得到奖赏值为-1
else:
next['L'] = [i, j - 1] #对于其他列的状态,采取“向左”动作后,下一状态为左一列,相同行的状态
reward['L'] = 0.0 #得到奖赏值为0
if j == WORLD_SIZE - 1:
next['R'] = [i, j] #对于第4列的状态,采取“向右”动作后,留在原地,即下一状态=原状态
reward['R'] = -1.0 #得到奖赏值为-1
else:
next['R'] = [i, j + 1] #对于其他列的状态,采取“向右”动作后,下一状态为右一列,相同行的状态
reward['R'] = 0.0 #得到奖赏值为0
if [i, j] == A_POS:
next['L'] = next['R'] = next['D'] = next['U'] = A_PRIME_POS #对于状态A,下一状态为A'
reward['L'] = reward['R'] = reward['D'] = reward['U'] = 10.0 #奖赏值为10
if [i, j] == B_POS:
next['L'] = next['R'] = next['D'] = next['U'] = B_PRIME_POS #对于状态B,下一状态为B'
reward['L'] = reward['R'] = reward['D'] = reward['U'] = 5.0 #奖赏值为5
nextState[i].append(next)
actionReward[i].append(reward)
def draw_image(image):
fig, ax = plt.subplots()
ax.set_axis_off()
tb = Table(ax, bbox=[0,0,1,1])
nrows, ncols = image.shape
width, height = 1.0 / ncols, 1.0 / nrows
# Add cells
for (i,j), val in np.ndenumerate(image):
# Index either the first or second item of bkg_colors based on
# a checker board pattern
idx = [j % 2, (j + 1) % 2][i % 2]
color = 'white'
tb.add_cell(i, j, width, height, text=val,
loc='center', facecolor=color)
# Row Labels...
for i, label in enumerate(range(len(image))):
tb.add_cell(i, -1, width, height, text=label+1, loc='right',
edgecolor='none', facecolor='none')
# Column Labels...
for j, label in enumerate(range(len(image))):
tb.add_cell(-1, j, width, height/2, text=label+1, loc='center',
edgecolor='none', facecolor='none')
ax.add_table(tb)
plt.show()
# for figure 3.5 贝尔曼方程估计等概率随机策略的值函数
while True:
# keep iteration until convergence
newWorld = np.zeros((WORLD_SIZE, WORLD_SIZE))
for i in range(0, WORLD_SIZE):
for j in range(0, WORLD_SIZE):
for action in actions:
newPosition = nextState[i][j][action] #获取下一个状态的位置
# bellman equation 贝尔曼方程
newWorld[i, j] += actionProb[i][j][action] * (actionReward[i][j][action] + discount * world[newPosition[0], newPosition[1]]) #+=实现对所有动作求和
if np.sum(np.abs(world - newWorld)) < 1e-4: #满足收敛条件,则终止迭代,输出结果
print('Random Policy')
draw_image(np.round(newWorld, decimals=1))
break
world = newWorld
# for figure 3.8 %利用最优贝尔曼方程计算最优值函数
world = np.zeros((WORLD_SIZE, WORLD_SIZE))
while True:
# keep iteration until convergence
newWorld = np.zeros((WORLD_SIZE, WORLD_SIZE))
for i in range(0, WORLD_SIZE):
for j in range(0, WORLD_SIZE):
values = [] #记录各动作所对应的项
for action in actions:
newPosition = nextState[i][j][action]
# 在这个例子中环境是确定的,所以p(s',r|s,a)=1,只有一项,无需求和
values.append(actionReward[i][j][action] + discount * world[newPosition[0], newPosition[1]])
newWorld[i][j] = np.max(values)
if np.sum(np.abs(world - newWorld)) < 1e-4:
print('Optimal Policy')
draw_image(np.round(newWorld, decimals=1))
break
world = newWorld

 浙公网安备 33010602011771号
浙公网安备 33010602011771号