n步自举法
n步时序差分方法是单独的蒙特卡罗和时序差分方法更一般的推广,性能通常优于那两种极端形式。
n步TD预测
MC使用完整奖赏序列
一步TD基于下一步奖赏,将一步后的状态值作为剩余奖赏的近似值进行引导更新
n步自举将MC与TD统一,灵活选择用未来n步的数据进行引导更新。更新是基于中间数量的奖赏值

n步Sarsa
利用n步方法进行控制,主要思想是将状态值函数换成状态-动作值函数,然后使用一个\(\varepsilon-greedy\)策略
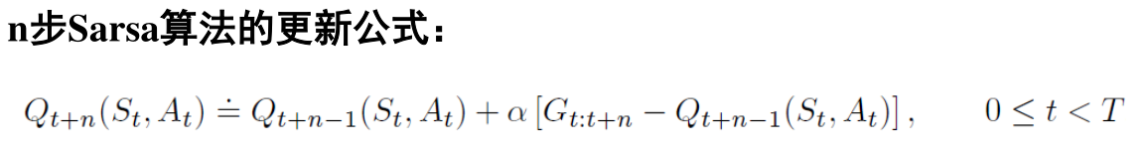
一步法只强化导致高回报的动作序列的最后一个动作,而n步法加强序列的最后n个动作,因此能从一个片段中学到更多。
n步期望Sarsa
与一步类似只是G不同

利用重要性采样进行n步异策略学习
【为了能够使用从b获得的数据,我们必须考虑两个策略之间的差异,这种差异用采取被采用动作的相对概率表示(重要性采样系数)】
只是多加了一个系数,表示的是样本序列产生的概率(条件概率套出来的)


