动态规划(Dynamic Programming, DP)
在阅读Offline Reinforcement Learning的相关文章时有文章根据动态规划和策略梯度进行分类,在此加上进行一些简单的总结。主要参考了参考链接中的内容
前言
强化学习研究从总体思路上可以分为两个大方向,一种是通过值函数近似来得到策略 称其为动态规划;另一种是策略梯度,讲究直接用函数来逼近策略。
什么是动态规划?
是指可以用于在给定完整的环境模型作为马尔可夫决策过程(MDP)的情况下计算最优策略的算法集合。就是一个多阶段决策问题,每一阶段都需要做出决策,但选取不能随意确定,既依赖于当前的状态,又影响以后的发展。一个决策序列就是在变化的状态中产生出来的,故含有动态的含义,称解决多阶段决策最优化的过程就叫做动态优化方法。多阶段的决策,互相依赖
核心思想是利用价值函数来结构化地组织对最优策略的搜索。在强化学习中,DP算法就是将贝尔曼方程转化为近似逼近理想价值函数的递归更新公式的过程。
【事实上,所有其它方法都是对DP的一种近似,只不过降低了计算复杂度以及减弱了对环境模型完备性的假设】
策略评估(又称预测问题)
对任意给定的策略\(\pi\),计算其状态价值函数。
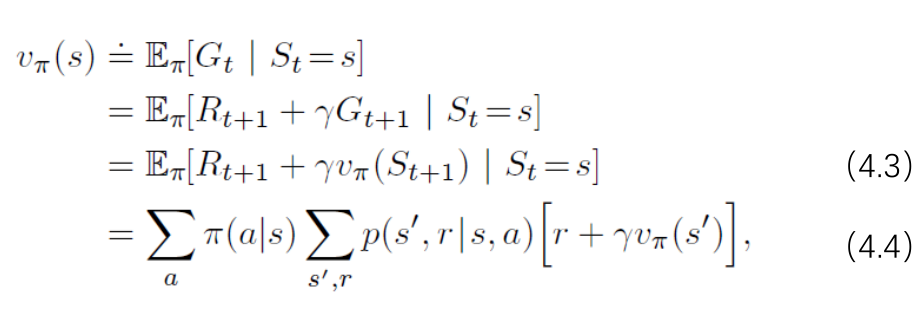
状态值函数更新方式:双矩阵迭代策略评估(遍历一遍状态,得到对应的值函数,所有的状态值函数更新一次)和原位更新迭代策略评估(每一个状态值函数在更新时会直接应用于其他状态值函数的计算)
策略改进
计算策略值函数的目的是找到更好的策略。知道了任意确定性策略的值函数\(v_\pi\)。如果想要知道在某状态下,改变策略选择某动作是更好还是更坏?
采用动作状态值函数来对动作之间进行对比即可知道当前的选择是好还是坏?【在该状态下采取动作a,之后仍采取已有策略来计算其值函数,选择出最大的动作 状态值函数】
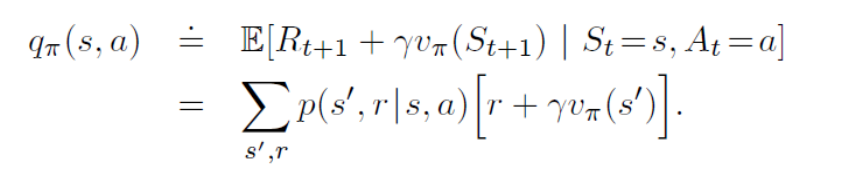
新的贪婪策略
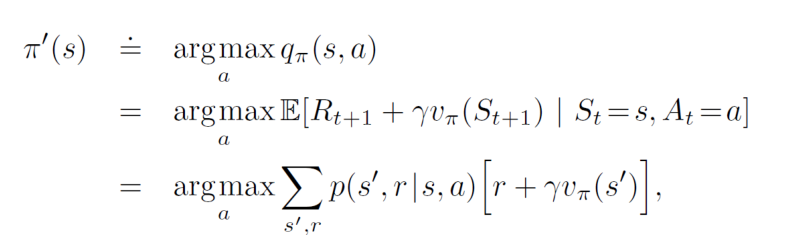
策略迭代
评估一次 改进一次,每一个策略都比前一个策略更优。由于一个有限MDP必然只有有限种策略,所以在有限次迭代后,这种方法一定收敛到一个最优的策略与最优值函数。
值迭代
策略迭代的缺点是每一次迭代都设计了策略评估,本身是一个需要多次遍历状态集合的迭代过程。有些问题收敛很快,我们可以提前截断策略评估过程。值迭代中,每次策略评估只涉及到一次值函数的更新,可以写成一个比较简单的更新操作,结合了策略改进和阶段的策略评估步骤。
其中一种特殊的情况是,在一次遍历后即刻停止策略评估(对每一个状态进行一次更新)。
值迭代的另一种理解方式是:仅仅是将贝尔曼最优方程变为一条更新规则。
对上述值函数、策略改进、值迭代的理解方式可以结合回溯图:
- 状态值函数是从当前状态开始加动作向下方延伸,递推涉及了策略选择的不同动作带来的不同后果。
- 动作-状态值函数是从当前状态下选择的动作之后开始延伸(相当于上述状态值函数的一小枝进行估计)
- 策略改进是每次都选择最好的动作状态值函数对应的动作(可视为对每一小只做了简单估计,然后选择好的)
- 值迭代是在动作状态值函数的基础上,每次都选择最好的动作去做。结合了评估和改进,只估计一次就改进一次。
异步动态规划
异步DP算法是一类就地迭代的DP算法,不以系统遍历状态集的形式来组织算法。这些算法使用任意可用的状态值,以任意顺序来更新状态值。【重要状态优先更新】在某些状态的值更新之前,另一些状态的值可能已经更新了好几次。为了正确收敛,异步DP算法必须要不断地更新所有状态的值。在某个计算节点后,它不能忽略任何一个状态。
广义策略迭代(GPI)
用GPI指代让策略评估和策略改进相互作用的一般思路,与这两个流程的粒度与其他细节无关。是让策略评估和策略改进过程交互的一般概念,不依赖于两个过程的间隔尺寸和其它细节。
控制
控制就是在前面的状态、动作等都已知,策略位置的情况下,计算出最优的值函数,并借此计算出最优的策略。
注:适用于动态规划的问题,一般状态转移矩阵都是已知的。【即环境模型已知,可以看作planning问题】
参考链接
- 强化学习之动态规划算法 - ZyBird的文章 - 知乎 https://zhuanlan.zhihu.com/p/265865395
- Offline RL 教程 - 施靖的文章 - 知乎 https://zhuanlan.zhihu.com/p/341502874
- 强化学习中的动态规划 https://wenku.baidu.com/view/4dee37ac6b0203d8ce2f0066f5335a8102d2667f.html
- 强化学习 - 动态规划(Dynamic Programming) - 掀桌喵的文章 - 知乎 https://zhuanlan.zhihu.com/p/72360992
