有限马尔可夫决策过程(Markov Decision Process, MDP)-- 强化学习策略和值函数
马尔可夫决策过程特征
· 状态、行动、奖励都是有限数值。下一次的状态和奖励只依赖于上一时刻的状态和行动。
· 马尔可夫决策过程与随机过程中的马尔可夫过程类似,不同点在于马尔可夫过程只看重状态之间的转移,主要研究的是给定初始状态稳定之后会变成什么样。在马尔可夫决策过程中,增加了动作的概念,两个状态之间不仅有一条连线(也就是状态有限时,在原来的状态转移图上,不同动作可能会导致同样的状态转移情况)
· 在这种状态与动作关系十分明确的问题中,可以借鉴随机过程中平稳分布的求解思想,直接利用动作状态转移矩阵计算去找到最终的平稳分布【实际计算中可以自己设定收敛门限,小于某些阈值即可认为收敛】
概念理解
值函数
又称状态函数,估计在一个给定状态下的好坏程度。根据期望回报来判断。【价值函数是用来评估智能体在给定状态下有多好,这里的有多好是用未来预期的收益来定义的,准确来讲就是回报的期望值。智能体期望未来能得到的收益取决于智能体所选择的动作。奖励取决于智能体的行动,故值函数定义是和特定行动方式有关的】
策略
从状态到选择每种可能行动的概率的一种映射,映射意味着把两个东西联系起来,算是做决策的依据。
估计
\(v_\pi\)函数被称为采用策略\(\pi\)的状态值函数,\(v_\pi(s)\)表示从状态\(s\)出发遵循策略\(\pi\)所能得到的期望回报。
\(q_\pi (s,a)\)函数被称为在状态s下,采用策略\(\pi\),采取行动a的值函数,依然是这种情况下得到的期望回报。
上述两种函数可以从经验中估计。例如智能体采用策略\(\pi\),对于遇到的每种状态得到实际回报取平均值,可以得到\(v_\pi\);将这些平均值根据在每种状态下采取不同行动而分开,平均值会趋向于\(q_\pi (s,a)\)。这种方法称为蒙特卡罗模拟(MC),它平均很多实际回报的随机样本值。当有很多状态时,该方法不再使用,可以将这两个函数用有参数的方程表示,通过调整参数,求解方程。
贝尔曼方程
贝尔曼方程描述的是状态的值之间的关系(主要通过这一状态的预期回报与下一状态的预期回报之间的关系来体现)可以看做是在原来随机过程求解平稳分布的那个式子中加了一些别的权重之类的东西增强对问题描述的准确性。
\(v_{\pi}(s)=\sum\limits_a \pi(a|s)\sum\limits_{s',r}p(s',r|s,a)[r+\gamma v_\pi(s')]\)
- 要确定这一状态的预期回报,需要知道下一状态的预期回报加上这一次的回报即可。这样就构造了递推关系。(根据任务是否有明确的结束标志,回报也有不同的计算方法,为了统一引入折扣系数 就是公式中的\(\gamma\))
- 这一状态与下一状态转变的关键在于选择的动作,选择什么动作是由策略决定的。所以对动作进行全概率求和公式(概率就是策略);需要注意到相同动作可能会出现不同状态,即使转换到同一状态也有可能出现不同的reward,所以需要对状态和reward同时进行求和才算完善。
- 在写贝尔曼方程之前需要知道什么?
- 状态有哪些
- 每个状态下可选的动作有哪些?(依状态之间能选的动作是否相同而定)
- 在每个状态下选择动作的策略是什么?
- 给定动作后,新状态和reward的遍历及概率
最优策略和最优值函数
最优策略(对所有状态,预期回报大于或等于任何一个策略)共享一个最优状态值函数、一个最优行动值函数。【每次都选择最好的动作,最优状态值函数从最优行动值函数中进行选择】
最优状态值函数
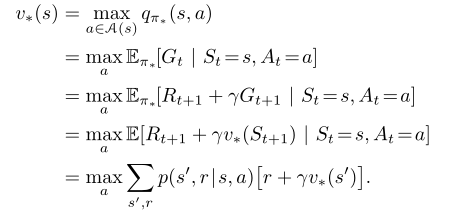
最优行动值函数

最优策略和最优值函数的回溯图
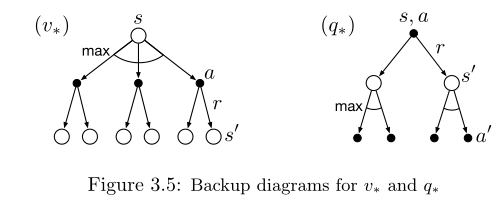
最优动作值函数:按照当前动作的选择造成的状态转移之后获得的最大期望回报(之后一直都选最好的动作)
上述回溯图在智能体的选择结点加入了弧线,表示找最大值而不是求期望。
常用例子:
回收机器人(状态:电量高低;动作:等待、充电、找垃圾;动作状态的转移关系:什么动作导致什么状态 得到什么奖励的转移关系)
Gridworld(跳方格 动作:上下左右,方格位置的转移关系,奖励设置)
