第1章 Hive基本概念
1.1 什么是Hive
- hive简介
- Hive:由facebook开源用于解决海量结构化日志的数据统计工具。
- Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类SQL的查询功能。
2) Hive本质:将HQL转化成MapReduce程序。
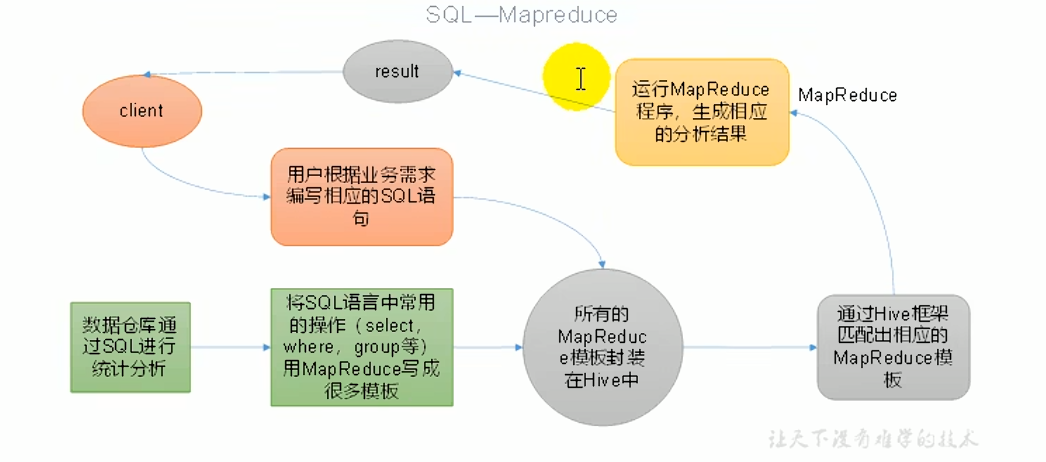
3) Hive的三个要点:
- Hive处理的数据存储在HDFS
- Hive分析数据底层的实现是MapReduce
- 执行程序运行在Yarn上
1.2 Hive优缺点
1.2.1 优点
- 操作接口采用类SQL,快速开发。
- Hive的执行延迟比较高,常用于数据分析,对实时性要求不高。
- Hive用于处理大数据,对小数据没有优势。
- Hive支持用户自定义函数。
1.2.2 缺点
(1)Hive的HQL表达能力有限
- 迭代式算法无法表达
- 数据挖掘方面不擅长,由于MapReduce数据处理流程的限制,无法实现效率更高的算法。
(2)Hive的效率比较低 - Hive自动生成的MapReduce作业,通常不够智能化
- Hive调优比较困难
1.3 Hive架构原理(重点:4个器)
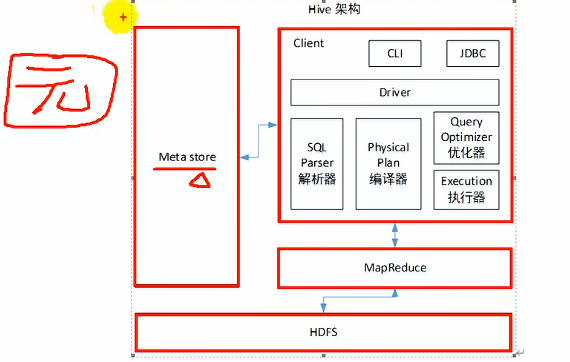
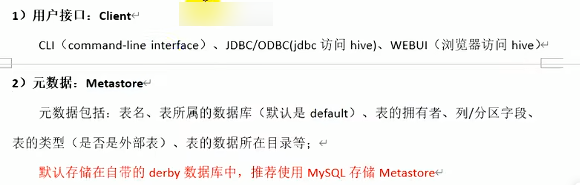
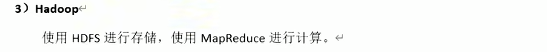

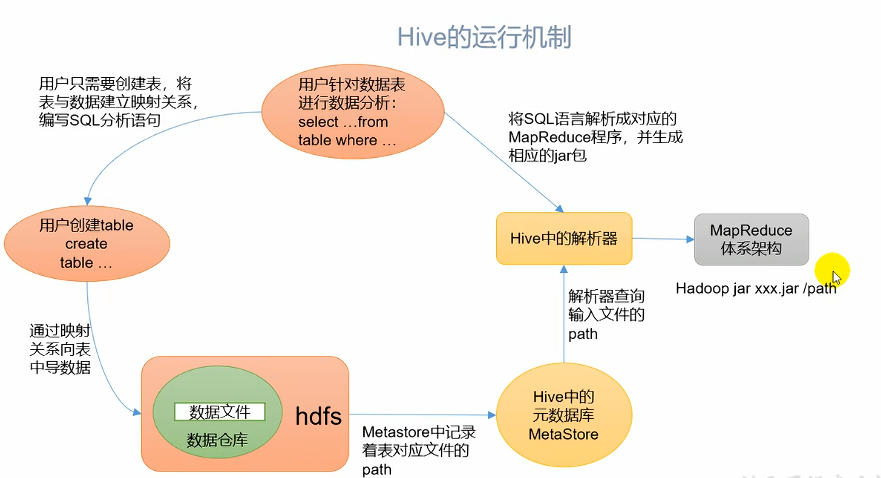
1.4 Hive和数据库比较
1.4.1 查询语言
- HQL
1.4.2 数据更新
- 数据仓库的内容式读多写少的
- 不建议对数据的改写,所有的数据都是在加载的时候确定好的
- 更改数据采用以下命令
- INAERT INTO...VALUES...
- UPDATE...SET...
1.4.3 执行延迟

1.4.4 数据规模
- Hive建立在集群上并可以利用MapReduce进行并行计算,因此可以支持很大规模的数据,对应的,数据库可以支持的数据规模较小。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号