数据中台体系搭建及技术选型
使用的技术栈

一、中台的前世今生
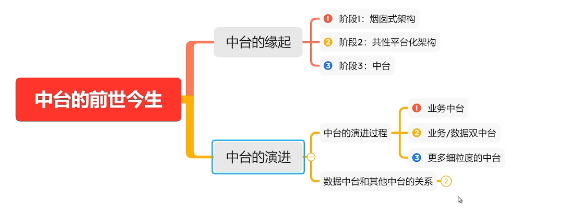
1. 中台的缘起
1.1 烟囱式架构
- 架构图及特点
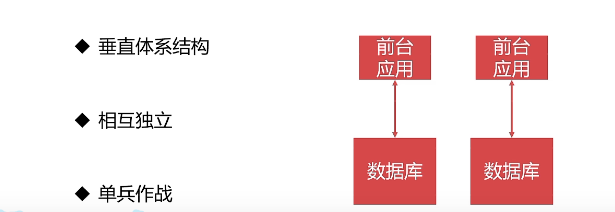
- 缺点

- 适用场景
业务简单、业务线较少的场景使用
1.2 共性平台化
- 架构图及特点
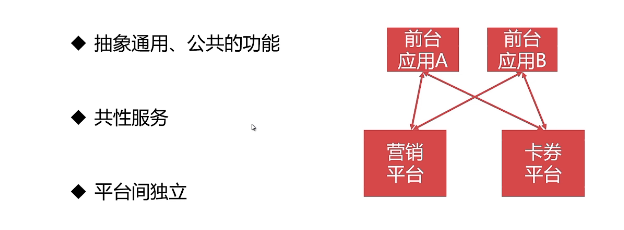
- 缺点


1.3 中台
-
架构图及特点

-
中台的核心能力

2. 中台的演进
2.1 中台的演进过程
- 业务中台:抽象业务流程的通用的业务能力
- 业务/数据双中台:打通各业务数据,汇聚多业务系统数据
- 中台细分(技术中台、安全中台、物联网中台、算法中台):灵活支撑更细粒度的业务线
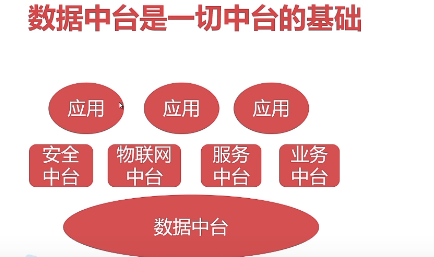
2.2 数据中台与其他中台的关系
- 数据中台与其他中台是相互配合、相互补充、相辅相成的关系。
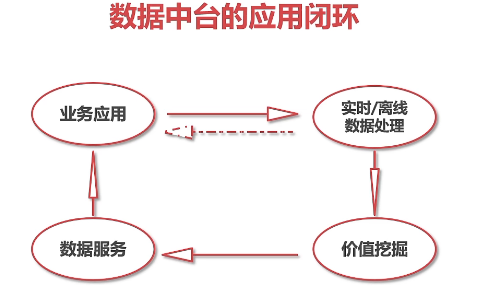
二、数据中台体系
1. 数据应用的发展阶段
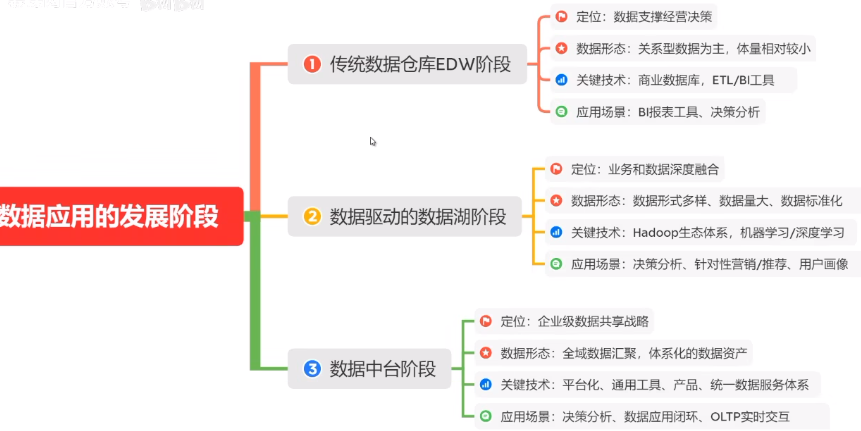
1.1 传统数据仓库EDW阶段
- 定位:数据支撑经营决策(决策者)
- 数据形态:关系型数据为主,体量相对较小
- 关键技术:商用数据库,小型机,ETL工具,BI套件
- 应用场景:BI报表工具,决策分析
1.2 数据驱动的数据湖阶段
数据驱动:不再是人工干预 数据湖:数据海量且数据形式不限
- 定位:业务和数据深度融合
- 数据形态:数据标准化
- 关键技术:Hadoop生态体系;机器学习/深度学习
- 应用场景:决策分析、针对性营销/推荐、用户画像
1.3 数据中台阶段
- 定位:企业级数据共享平台
- 数据形态:体系化的数据资产
- 关键技术:平台化、通用工具、产品、统一数据服务体系
- 应用场景:决策分析、营销/推荐、OLTP实时交互
2. 成熟的数据中台具备的能力
- 汇聚全域数据(采购食材)
- 数据资产体系能力 (洗,切)
- 资产管理能力 :元数据、数据血缘、数据质量、生命周期 (菜品、质量)
- 工具/组件平台化
- 流程可视化
- 系统架构与组织架构匹配(工种)
3. 数据中台架构
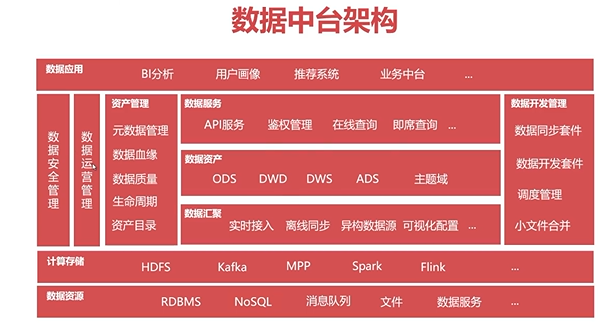
- 数据资源层:内部或者外部未经加工过的数据。
RDBMS:关系型数据库
- 计算存储层:数据中台的核心组件
HDFS:分布式文件系统;kafka:消息队列;MPP:数据库;Spark、Flink:计算引擎
- 数据汇聚层:将不同网络、不同数据库的各种异构的数据源通过离线或者实时的方式采集至数据中台进行集中存储,从物理上打破数据孤岛。
- 数据资产层:该部分是数据中台建设的核心内容,能够更好的支撑数据的应用。
ODS:原始数据层,该层尽可能保留和原始业务流程数据一致;DWD:明细数据层,该层主要进行数据清洗;DWS:服务数据层;
ADS:应用数据层,该层主要提供给数据产品和数据分析使用的数据。
- 数据服务层:利用数据提供一些服务。
- 资产管理:提升数据的应用,使得数据增值。
- 数据运行管理
- 数据安全管理
- 数据开发管理:贯穿数据中台的始终,提供各类数据的套件。
- 数据应用:对各类数据进行
4. 技术选型
4.1 数据采集汇聚
- 日志实时采集:Filebeat、Flume等
- 数据库实时同步:MaxWell、Canal、OGG
- 离线数据交换:Sqoop、DataX、自研产品
4.2 数据存储
- HDFS:分布式文件系统;Kafka:消息队列;Hbase/Phoenix:海量数据查询;Elasticsearch:搜索引擎;ClickHouse:联机分析的列式数据库管理系统(DBMS)
4.3 计算引擎
- 离线计算:Spark、Hive(早期)
- 实时计算:Spark(Structured) Streaming、Flink
4.4 即席查询
- 用于分析型的查询
- 分类:
- ROLAP(Relational OLAP):Presto、ClickHouse、Doris
ROLAP: 即查即用,不需要预聚合的。-- 是未来的趋势
- MOLAP(Multidimensional OLAP):Kylin,Druid
MOLAP: 将细节的数据和聚合的数据保存在立方体中,用空间来换效率。
4.5 在线查询
- 在线查询:Elasticsearch(数据检索),Redis(满足响应要求高的数据),MySQL,TiDB,Hbase(后三个是满足响应要求正常的)
4.6 数据调度
- Azkaban,Airflow,DolphinScheduler
三、基于Spark源异构数据同步套件
1. 数据采集、汇聚的技术架构
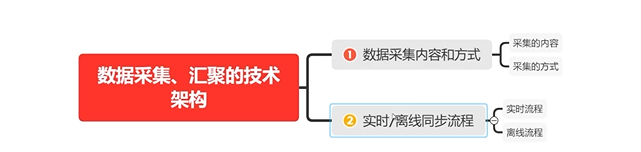
1.1 数据采集内容和方式
-
采集的内容
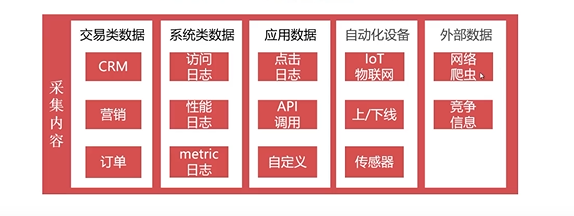
-
采集的方式

1.2 实时/离线同步流程
- 实时流程:分为数据库信息和日志信息的实时同步。
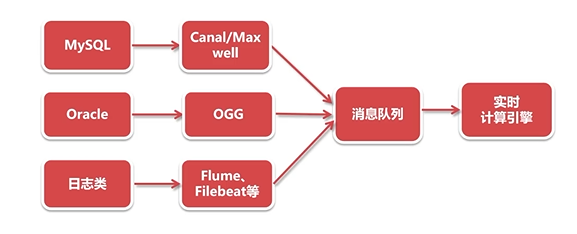

canal/Max well,OGG都是日志信息,因为不能直接获取数据库,通过增量日志的方式来捕获数据的变化
- 离线流程:用于大批量数据迁移,保证数据安全可靠,通过周期性的离线任务进行调度。
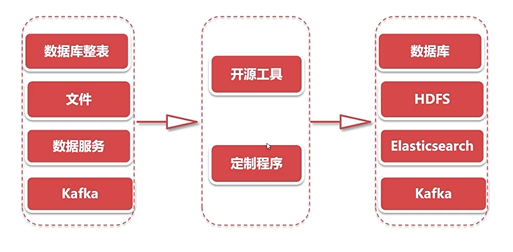

2. 构建异构数据源的同步套件
2.1 开源工具同步问题分析
- Sqoop:批量迁移数据的工具;Sql+Hadoop,效率低、不支持实时、功能扩展受到限制。
- DataX:单机多线程(对内存要求比较高)、不支持非结构化的数据同步、不支持实时、性能扩展性受到很大限制
- Canal、Maxwell等:数据源支持的不多、同步链路比较长,单线程存储,性能不高。
2.2 定制同步程序问题分析
- 为每类同步逻辑定制程序
- 业务逻辑改动需同步调整程序
- 维护复杂
- 功能重用度低
2.3 异构数据同步套件
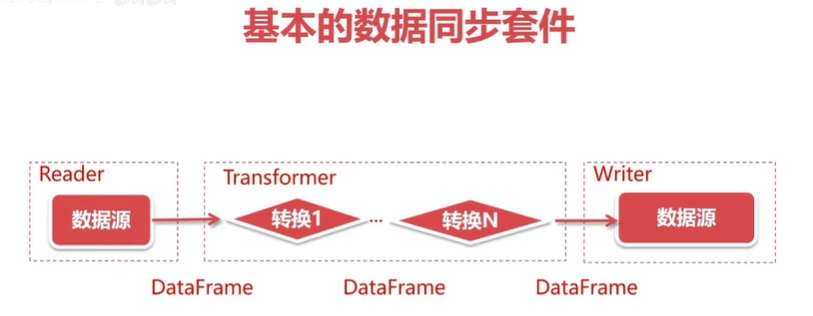
- 数据的读取、数据的转换、数据的写入三个模块
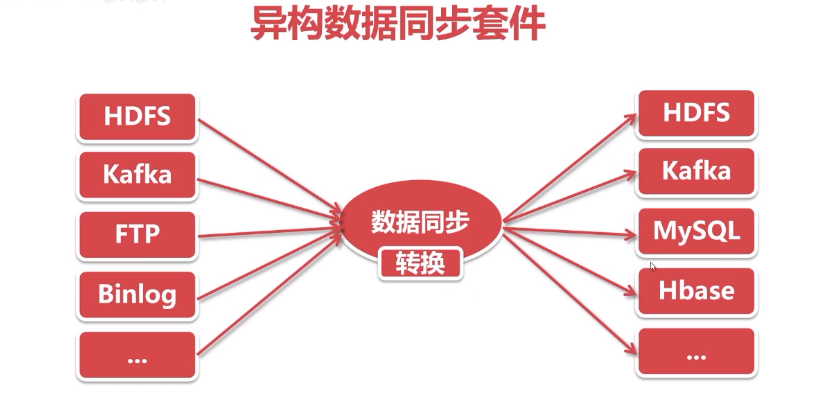
2.4 异构数据同步套件具备的功能
- 统一的配置或可视化的操作界面来屏蔽底层的复杂性
- 异构数据源的统一管理:快速实现不同数据源之间的交换
- 基于分布式或是多通道的数据同步,充分运用主机的资源,并解决性能的扩大问题。
- 健壮的容错机制
- 插件化的管理,抽象为数据的读取、数据的转换、数据的写入三个过程。
- 支持完善的离线和实时的策略
2.5 数据同步套件
-
基本形式
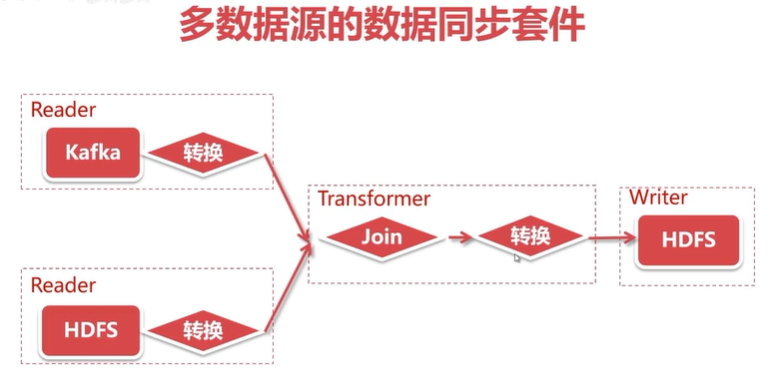
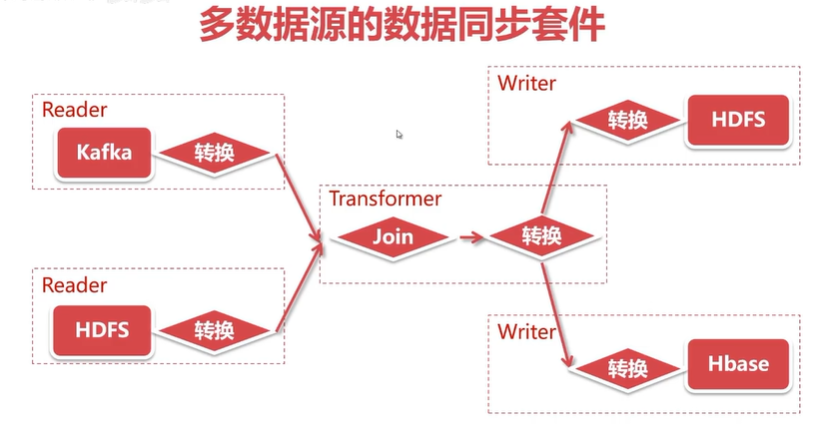
-
多数据源的形式

 浙公网安备 33010602011771号
浙公网安备 33010602011771号