决策树算法2-决策树分类原理2.4-基尼值和基尼指数
1 概念
- CART决策树使用"基尼指数" (Gini index)来选择划分属性,分类和回归任务都可用。
- 基尼值Gini(D):从数据集D中随机抽取两个样本,其类别标记不一致的概率
- Gini(D)值越小,数据集D的纯度越高。
2 计算
- 数据集 D 的纯度可用基尼值来度量:
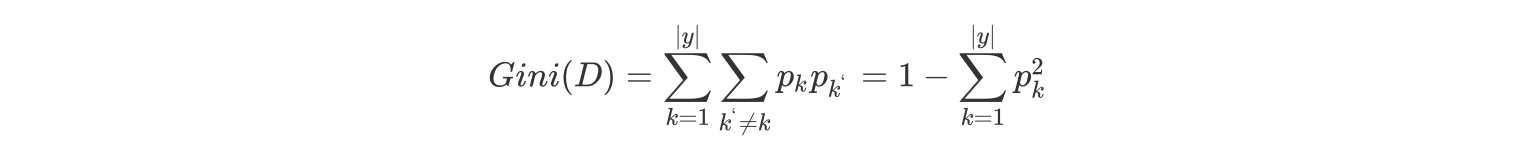
\(p_k=\frac{c^k}{D}\),D为样本的所有数量,\({c^k}\)为第k类样本的数量。
- 基尼指数Gini_index(D):一般,选择使划分后基尼系数最小的属性作为最优化分属性。
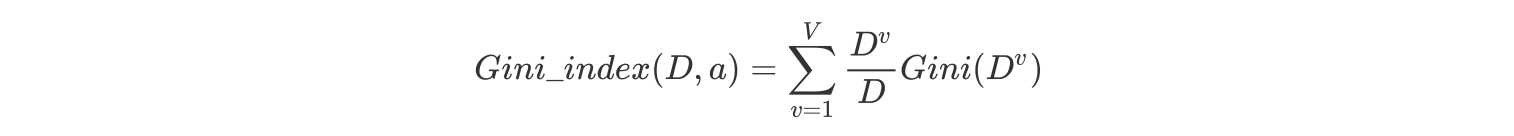
3 案例
请根据下图列表,按照基尼指数的划分依据,做出决策树。
| 序号 | 是否有房 | 婚姻状况 | 年收入 | 是否拖欠贷款 |
|---|---|---|---|---|
| 1 | yes | single | 125k | no |
| 2 | no | married | 100k | no |
| 3 | no | single | 70k | no |
| 4 | yes | married | 120k | no |
| 5 | no | divorced | 95k | yes |
| 6 | no | married | 60k | no |
| 7 | yes | divorced | 220k | no |
| 8 | no | single | 85k | yes |
| 9 | no | married | 75k | no |
| 10 | No | Single | 90k | Yes |
1、对数据集非序列标号属性{是否有房,婚姻状况,年收入}分别计算它们的Gini指数,取Gini指数最小的属性作为决策树的根节点属性。
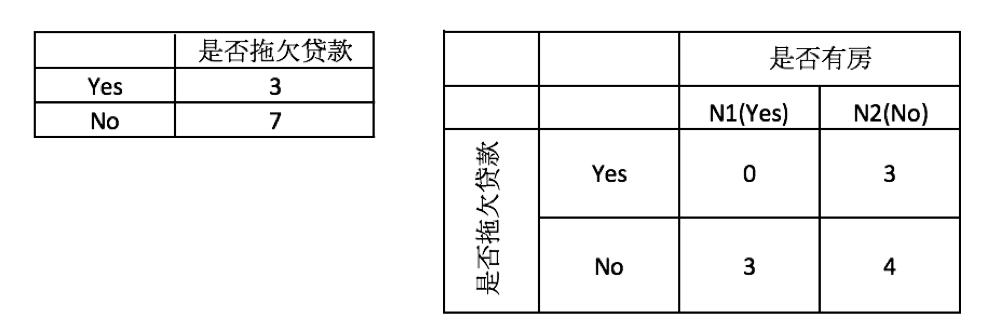
2、根节点的Gini值为:
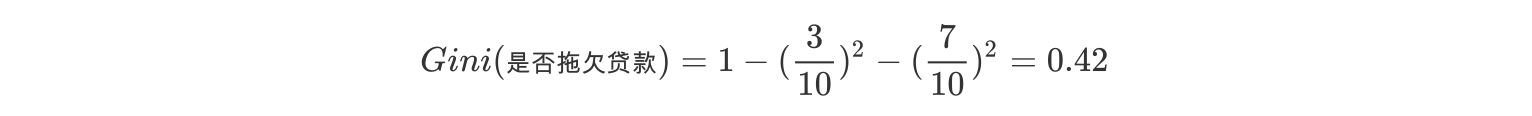
3、当根据是否有房来进行划分时,Gini指数计算过程为:

4、若按婚姻状况属性来划分,属性婚姻状况有三个可能的取值{married,single,divorced},分别计算划分后的Gini系数增益。

对比计算结果,根据婚姻状况属性来划分根节点时取Gini指数最小的分组作为划分结果{married} | {single,divorced}。
5、同理可得年收入Gini:
对于年收入属性为数值型属性,首先需要对数据按升序排序,然后从小到大依次用相邻值的中间值作为分隔将样本划分为两组。例如当面对年收入为60和70这两个值时,我们算得其中间值为65。以中间值65作为分割点求出Gini指数。
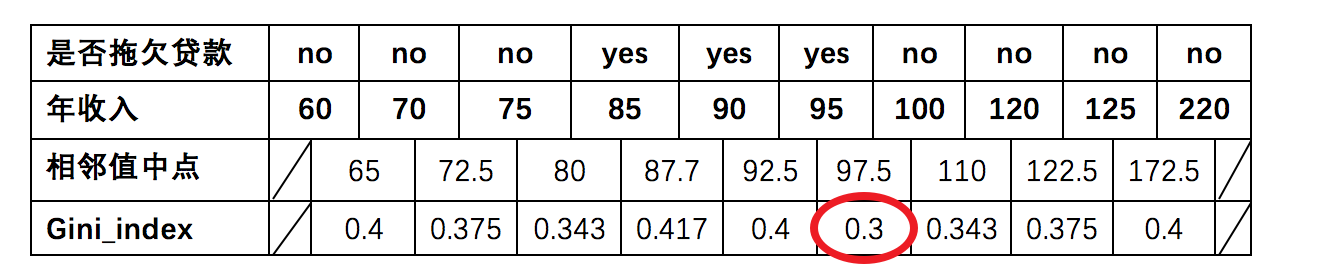
根据计算知道,三个属性划分根节点的指数最小的有两个:年收入属性和婚姻状况,他们的指数都为0.3。此时,选取首先出现的属性【married】作为第一次划分。
6、接下来,采用同样的方法,分别计算剩下属性,其中根节点的Gini系数为(此时是否拖欠贷款的各有3个records)
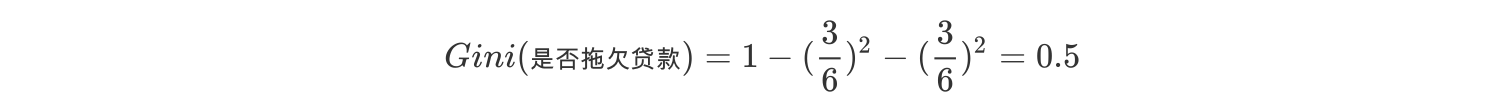
7、接下来,采用同样的方法,分别计算剩下属性,其中根节点的Gini系数为(此时是否拖欠贷款的各有3个records)
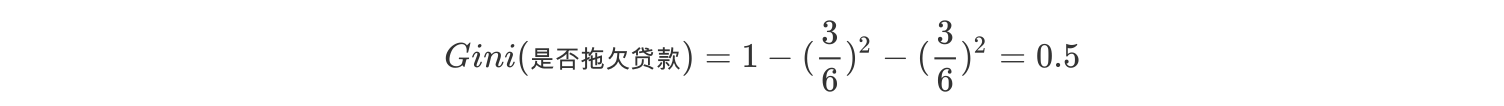
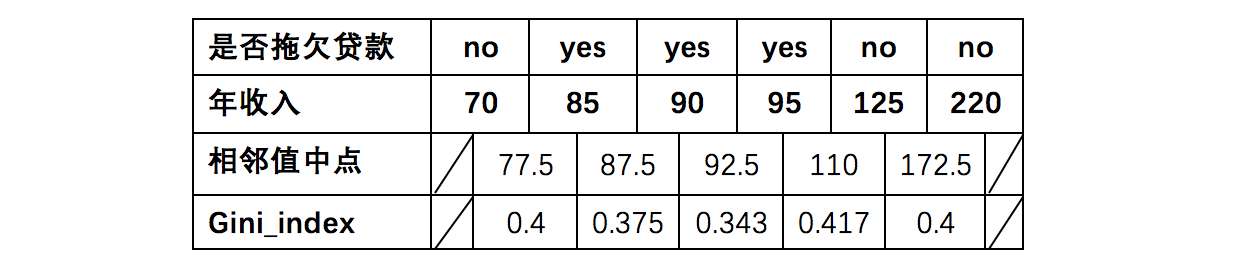
8、对于年收入属性则有:
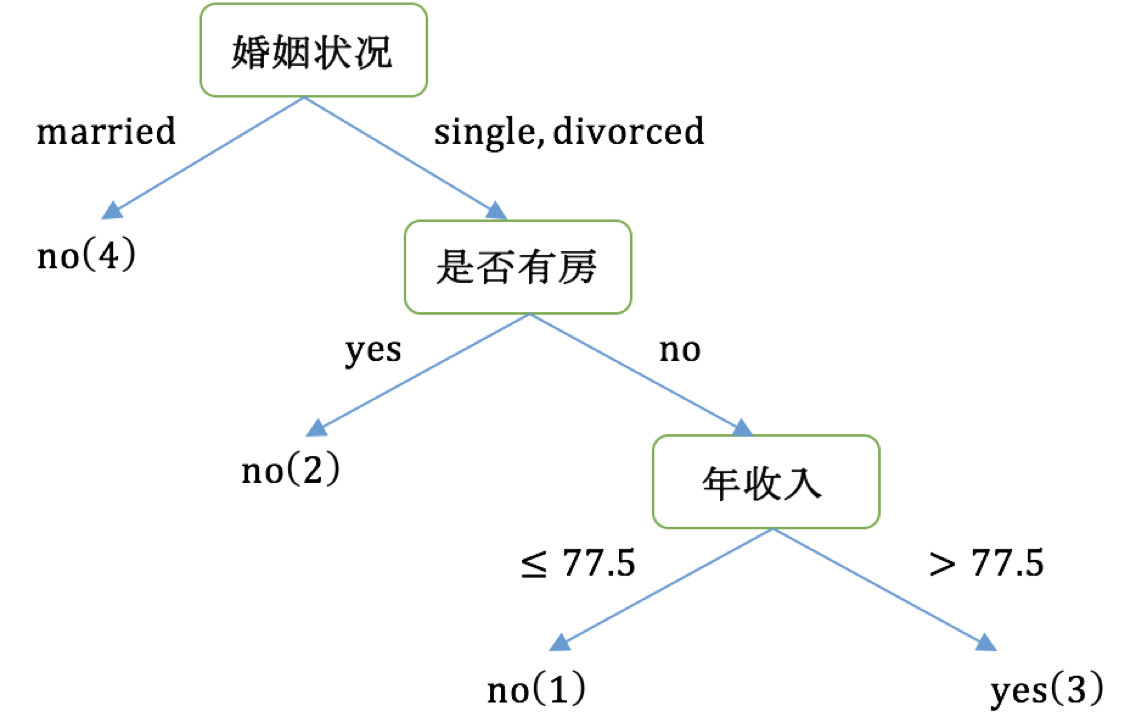
经过如上流程,构建的决策树,如下图:
4 CART算法流程
while(当前节点"不纯"):
1.遍历每个变量的每一种分割方式,找到最好的分割点
2.分割成两个节点N1和N2
end while
每个节点足够“纯”为止

 浙公网安备 33010602011771号
浙公网安备 33010602011771号