决策树算法2-决策树分类原理2.1-信息熵
熵
1 概念
1.1 起源
- 物理学上,熵 Entropy是“混乱”程度的量度。系统越有序,熵值越低;系统越混乱或者分散,熵值越高。
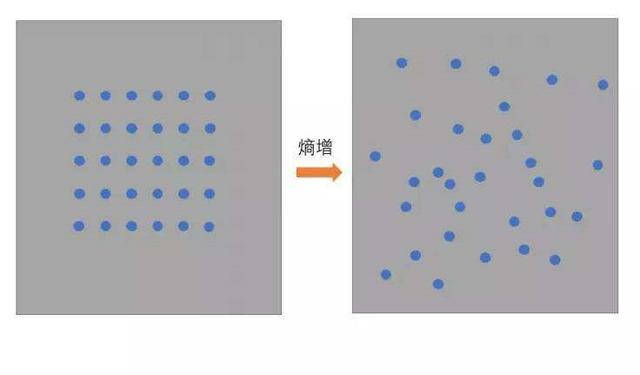
- 1948年香农提出了信息熵(Entropy)的概念。
1.2 信息理论
- 从信息的完整性上描述:系统的有序状态一致时,数据越集中的地方熵值越小,数据越分散的地方熵值越大。
- 从信息的有序性上描述:数据量一致时,系统越有序,熵值越低;系统越混乱或者分散,熵值越高。
1.3 信息熵定义
- "信息熵" (information entropy)是度量样本集合纯度最常用的一种指标。
- 假定当前样本集合 D 中第 k 类样本所占的比例为, D为样本的所有数量,为第k类样本的数量。则D的信息熵定义为(log是以2为底,lg是以10为底):
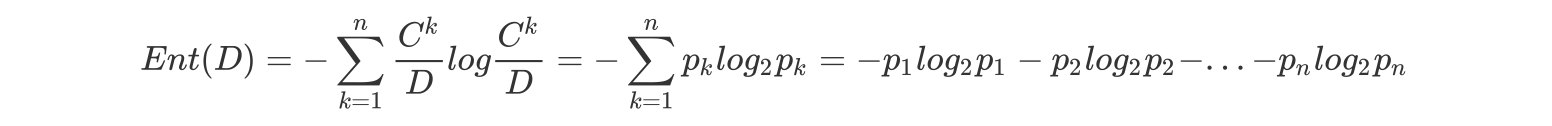
其中:Ent(D) 的值越小,则 D 的纯度越高.
2 案例
课堂案例:
假设我们没有看世界杯的比赛,但是想知道哪支球队会是冠军,
我们只能猜测某支球队是或不是冠军,然后观众用对或不对来回答,
我们想要猜测次数尽可能少,你会用什么方法?
答案:
二分法:
假如有 16 支球队,分别编号,先问是否在 1-8 之间,如果是就继续问是否在 1-4 之间,
以此类推,直到最后判断出冠军球队是哪支。
如果球队数量是 16,我们需要问 4 次来得到最后的答案。那么世界冠军这条消息的信息熵就是 4。
那么信息熵等于4,是如何进行计算的呢?
Ent(D) = -(p1 * logp1 + p2 * logp2 + ... + p16 * logp16),
其中 p1, ..., p16 分别是这 16 支球队夺冠的概率。
当每支球队夺冠概率相等都是 1/16 的时:Ent(D) = -(16 * 1/16 * log1/16) = 4
每个事件概率相同时,熵最大,这件事越不确定。
练习:
篮球比赛里,有4个球队 {A,B,C,D} ,获胜概率分别为{1/2, 1/4, 1/8, 1/8}
求Ent(D)
答案:
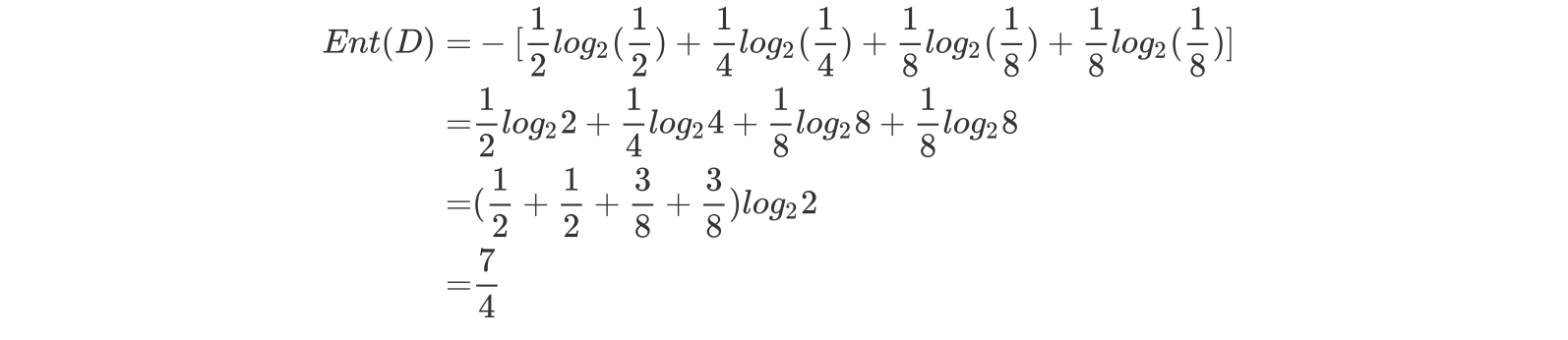
分类:
数据分析方法 / 决策树
标签:
机器学习


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix