随笔分类 - 蚂蚁学python-推荐系列
https://space.bilibili.com/61036655/search/video?keyword=%E6%8E%A8%E8%8D%90
摘要:业务数据库->模型训练 前端埋点日志->模型预估 外部数据->统计报表输出 归一化:变换到0-1之间 分箱处理:分为不同阶段 one-hot:用于简单词语的分类 0,1分别对应nannv tf-idf:用于关键词对应 行为的id列表:embedding向量化
阅读全文
摘要:1. windows安装faiss 只能安装cpu版本 conda install faiss-cpu -c pytorch 安装不上就换源 找到这个文件.condarc 替换为以下代码 channels: - https://mirrors.tuna.tsinghua.edu.cn/anacond
阅读全文
摘要: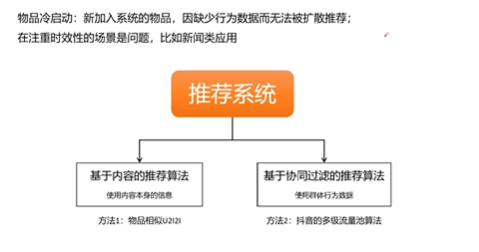   
阅读全文
摘要:u2i由用户向量*物品向量得到 i2i由物品向量*物品向量得到
阅读全文
摘要:内容获取(存储MySQL)-进行分词(TF-IDF)-语义拓展-生成每篇文章的向量(出现对应的词及拓展的词就是1)-每篇文章最相似的topN的文章-缓存-提供服务 看github案例 中文的词库:ai.tencent.com/ailab/nlp/embedding.html 数据量小用提取关键词后可
阅读全文
摘要: 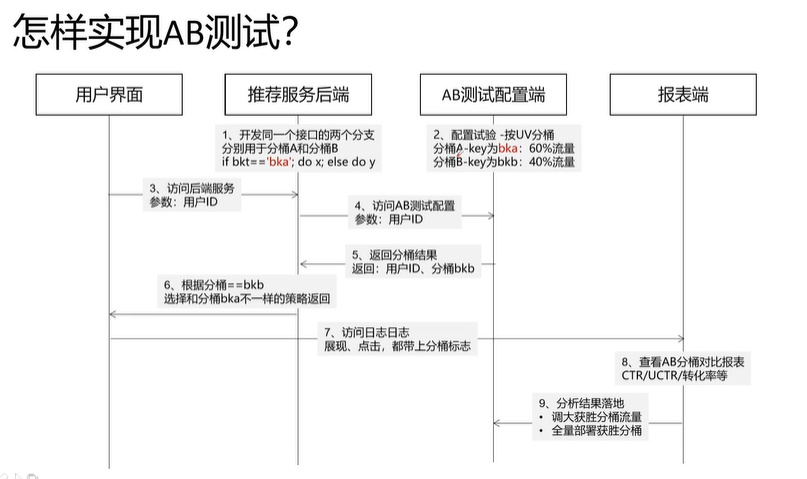 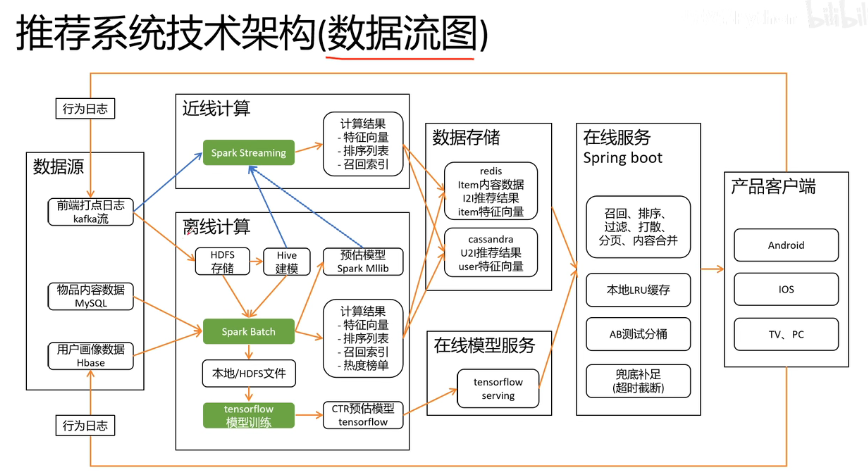
阅读全文
摘要:
阅读全文
摘要:U tag I 都表示结点,2表示边 i2i: 一个物品和另一个物品的相似度 内容相似:取标题的关键字的相似度,推荐标题相似的文章 基于行为->协同过滤、关联规则:发现ItemX和ItemY经常一起看,看过ItemX就推荐ItemY u2i:用户的直接行为推荐 u2i2i:两种方式结合 u2u2i:
阅读全文
摘要:召回: 降低数量级、选取与用户直接相关/间接相关的粗略相关的内容 排序:喜欢/不喜欢对应二分类的问题,按照概率进行排列,已经是精确的个性化了 调整:进一步细节优化 数据量不多的话,可以直接抛给排序阶段对数据进行排序,效果也不错
阅读全文
摘要:一、推荐系统是什么 定义:根据用户的历史信息和行为,向用户推荐他感兴趣的内容 方法: 用户1喜欢钢铁侠,绿巨人与钢铁侠近,推荐绿巨人 用户1与用户3相近,将用户3喜欢的蝙蝠侠推荐给用户1 根据用户看过的内容,依据内容的标签,推荐具有相同内容标签的电影和课程 推荐系统解决了什么问题
阅读全文
 浙公网安备 33010602011771号
浙公网安备 33010602011771号