


re正则表达式
正则表达式
re regular expression ,regex,RE
正则表达式是用来简洁表达一组字符串的表达式,正则表达式是一种针对字符串表达“简洁”和“特征”的工具。
用途:
- 表达文本类型的特征
- 同时查找或替换一组字符串
- 匹配字符串的全部或部分 最主要应用于字符串的匹配
Python导入re库
import re
正则表达式的使用,需要编译
编译:将符合正则表达式语法的字符串转换成正则表达式特征
re.compile()
常用表达式
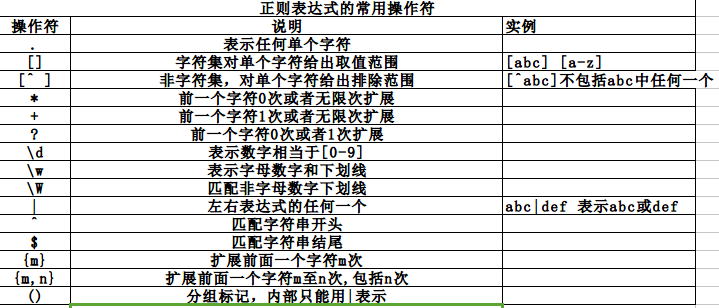
re库的使用
re库使用raw string(原生字符串)来表示正则表达式,表示为:
r'text'
原生字符串:不包含对转义符再次转义的字符串
re库的主要功能函数
re.search() 返回match对象
re.match ,从字符串开头进行匹配,返回match对象
re.findall 返回列表对象,返回全部符合匹配的子串
re.finditer 返回一个匹配结果的迭代类型,每一个迭代类型都是一个match对象
re.split() 将一个字符串按照正则表达式匹配结果进行分割,返回列表类型
re.search(pattern,string,flags=0)
pattern:正则表达式的字符串或者原生字符串表示
string:待匹配的字符串
flags:正则表达式的使用的控制标记 re.I :忽视大小写 re.M :吧字符串的每一行当做开头进行匹配 re.S 操作符匹配所有字符,默认匹配除换行符之外的所有字符。
re库的另一种等价用法:
regex=re.compile(r'[1-9]\d{5}')
regex.search('BIT 100081')
等价于
rst=re.search(r'[1-9]\d{5}','BIT 100081')
分组()
?P<> 给分组起名字
?: 取消分组的优先级


import re print(re.findall("<(?P<tag_name>\w+)>\w+</(?P=tag_name)>","<h1>hello</h1>")) print(re.search("<(?P<tag_name>\w+)>\w+</(?P=tag_name)>","<h1>hello</h1>")) r=re.findall(r"<(?:\w+)>\w+</\w+>","<h1>hello</h1>") print(r) 》》》['h1'] 》》》<_sre.SRE_Match object; span=(0, 14), match='<h1>hello</h1>'> 》》》['<h1>hello</h1>']
