
老白聊数据-关于销售预测的那些事
小白混迹了几年,现在是个老白了,看似啥玩意都懂点,啥玩意也都不精通,今天和大家说的是关于销售预测的那些事,因为最近看了JDD大赛,也和几个参赛队员交流,有些有意思的想法,和大家分享一下。
最近在关注京东金融举办的JDD大赛,这个比赛比较有意思。大赛也是分了几道赛题,比如猪脸识别,信贷需求预测,店铺销售预测,登录行为识别,总的而言,比较贴近业务实际使用场景。比赛也是分了算法组和商业组,算法组是纯粹的PK算法的效果,而商业组,除了完成算法的构建和评分排名,进入决赛的队伍还要写作BP,构建一个基于赛题基础的商业模型。总体说,从京东金融的业务需要出发,本身题目具备商业价值,具体赛题信息如下图:

今天就花点时间说说个人对其中店铺销售预测这道赛题的一些理解和认识。
在商业组中,官方如是描述赛题:对店铺销量进行预测是“京小贷”业务信用评估的关键环节之一,只有准确的预估店铺未来的销量,才能合理的设定贷款额度,提高资金利用率。
具体的赛题内容是:对店铺开展贷款业务需要定期测量和跟踪经营状况,对店铺销量进行预测是其中的关键环节之一,只有准确的预估店铺未来的销量,才能准确的评估其资金需求并设定合理的贷款额度。本题目希望参赛者通过竞赛数据中店铺过往的销售记录,商品信息,商品评价,以及广告费用等信息来建立预测模型,预测店铺未来90天内的销售额。赛题数据为业务情景竞赛数据,所有数据均已进行了采样和脱敏处理,字段取值与分布均与真实业务数据不同。
简单说,通过精准预测销售,掌握未来店铺的业务情况,基于此,进行业务授信,发放贷款。这也就是说,当预测越精准,那么业务评估能力就越强,可以合理开展业务。
而京东给到的赛题数据具体如下:
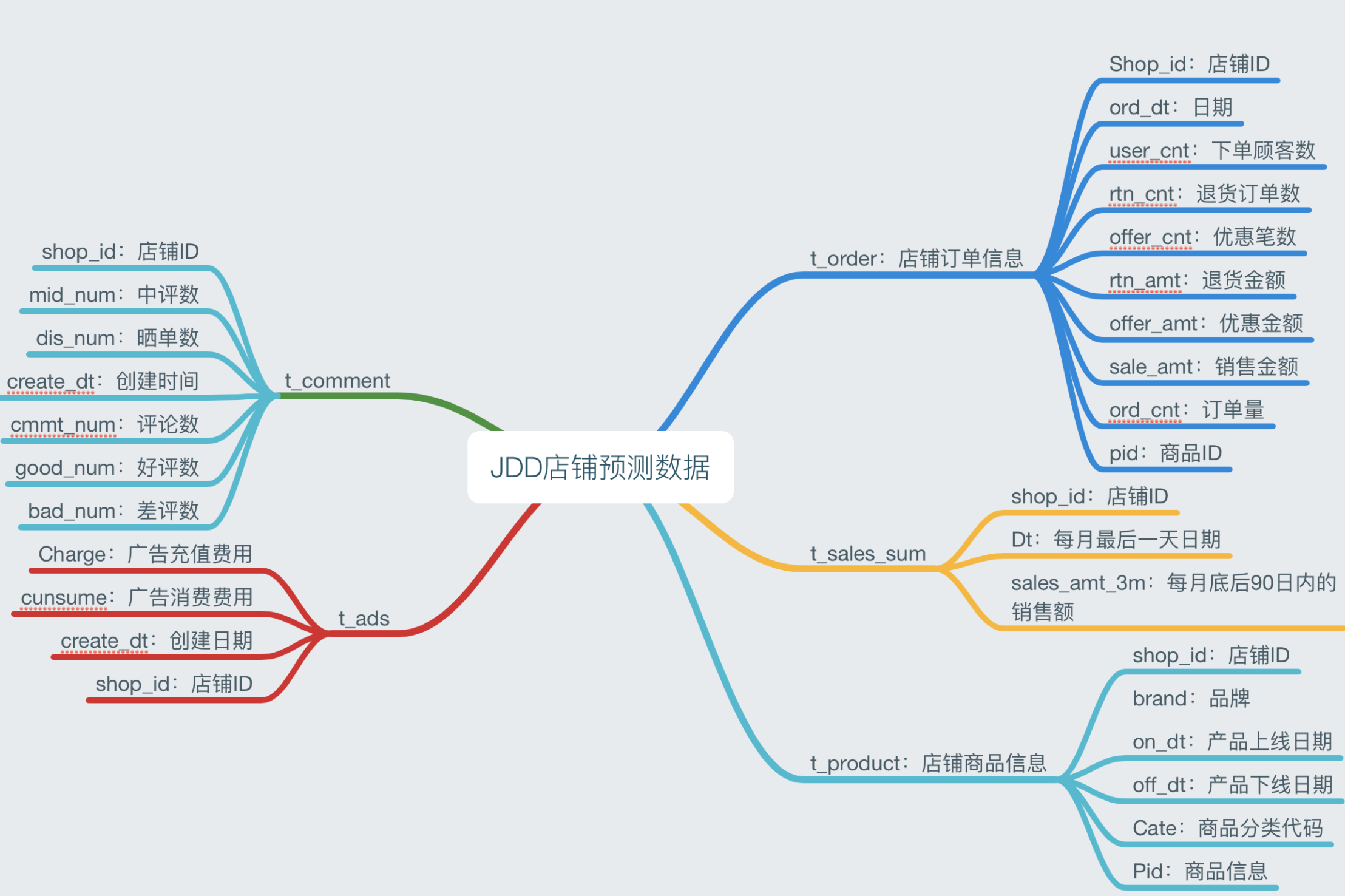
评分标准如下:
对于每个店铺,计算其真实销量和预测销量之间的差异,按如下公式计算分数,其中yi真实值,y_hati为预测值,m为待测店铺数量:
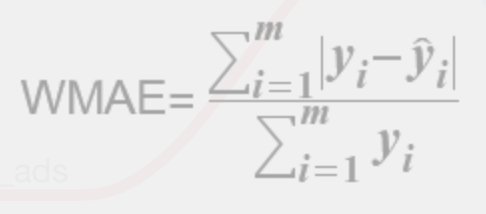
换句话说,谁的得分越低,就是误差更小,谁的预测效果更好。
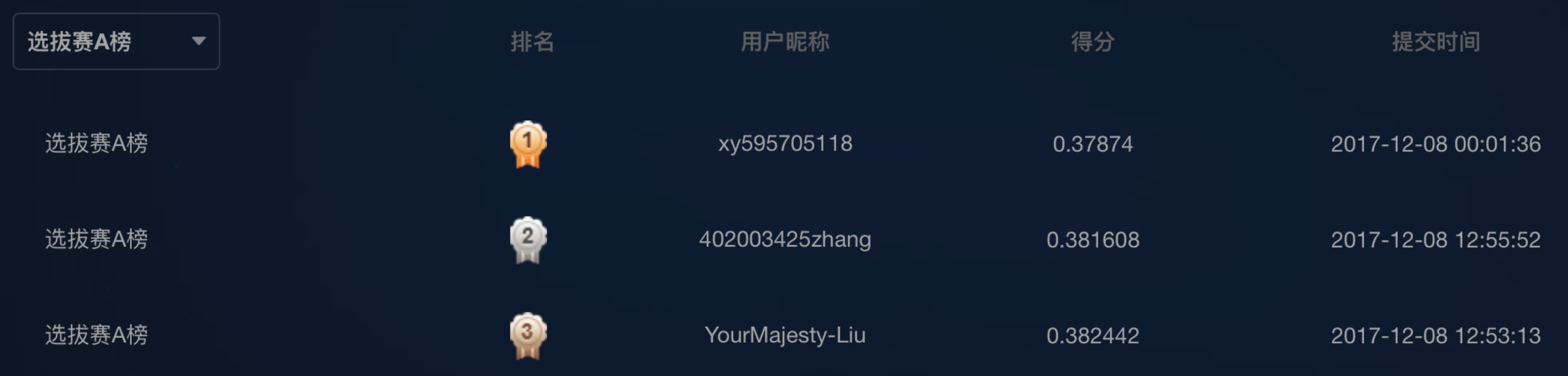
我查看了店铺销售预测商业组的排行榜,发现了一些有意思的事情,你会看到大家的得分基本没有拉开差距,第一名是0.393,而第三名是0.3945,也就是说大家在方法使用上,或者数据理解上,基本上差异性很小。可能在具体的尝试过程中,由于数据的准备不同,带来了一些细微差异,换句话这个榜单前三名的随机性很强,基本没什么差别。我们并没有看到出现那种差距极大的队伍出现。即使我们去看算法组的第一名得分也只是0.37。
商业组前10名得分

算法组前三名得分
那这个基本可以忽略的差距说明了什么问题,为什么没有出现一骑绝尘的队伍,对此我们此时需要回到这道题目本身来思考。
首先销售预测问题的一些成熟算法和模型,我们不需要多言,你是时间序列也好,还是ARIMA,LR,BPNN也罢,总的说算法就那么多,想解决这个问题,是无法脱离这些的。那么为什么预测的水平上不去,仍旧高达30%的误差?其实在官方给出的数据中,貌似给定了一定的预测所使用数据的边界,也许数据本身就代表了这道题目的局限性。
我们会发现,官方给出来的用于预测的数据中,涵盖了广告充值,评论,上下架时间的数据。似乎想从这个数据方面,来极限考验参赛团队的算法和数据准备实力。
但是再换一个维度思考,也许这是京东认为的对于销售预测相对有用的维度数据,当然了也涵盖部分商品信息,比如品牌和分类,似乎从中都是要找到与销售数字的相关性,进而提升预测准确性,不过我们发现商品相关信息,也只是关于品类这样维度的数据。
从销售预测本身来看,如果我们绘制一条某店铺销售曲线,我们会发现,头部有一两件商品的销售占比很高,二其他很多产品销售占比很低,或者是我们将店铺商品进行归类,某一类商品可能占据极高的销售数字。这就是我们以前总提到的一个20/80原则,也叫做帕累托法则,也就是20%的人贡献80%的业绩。在这个数据中,其实这种情况也存在,比如少数商品贡献多数收入的问题,少数店铺贡献多数收入。因此,在预测时,20/80原则实际上也是一种预测问题的处理思路,少数店铺的销售贡献依赖少数商品,当然也依赖广告或者评论的影响。不过从目前大家的分看,也许这几个因素的权重总计在60%左右。
那么剩下40%的因素在哪里?因为理论上,我们的得分是0才对。
在这里和大家的讨论是如何提高预测准确率的一种思考,换句话,也是寻找40%的因素的一种思路。
首先把销售预测问题换个角度来看,就是判断消费者购买的意愿高低,再细致来看,就是消费者的购买动机或者购买决策的判断,一旦找到那个准确的相关度最高的动机,那么就意味着,销售的预测精度就会大幅度提升。从初赛这些人员的预测结果看,以现有的算法,意味着这些因素与购买动机的的相关度,仅限于这个得分了。
我们之前用于销售预测的数据考虑了营销因素(广告),社交因素(评论),商品开发(上下架时间),但我们发现这些都是宏观因素,但是今天的消费者慢慢趋于理性,会考虑评论因素,也会货比三家,尽管价格还是一个很重要的因素。
但是我们发现作用很大的评论数据,在这里,被官方处理为正面评论,中性评论,负面评论,得说一句,这种数据的处理在数据集开放之前就做好了用1,0,-1来代替,但是对于语义的处理,划分三类标签,会出现一些偏差,毕竟如何理解正面,中性,负面,这个人的经验是不同的。这或许是本赛题中一个思考的方向。
不过如果排除这个因素我们会发现,似乎还是无法说明误差为什么很大,这时我们需要跳出来看,我们似乎忘记了很多的微观因素,比如商品本身的品质,参数,元素,颜色等等,这些不起眼的东西,也许正是最重要的驱动消费者购买的最重要动机。
在销售预测问题上,如果我们能够挖掘到用户购买的微观动机,也就是商品本身是否具备潜力和畅销特性,那么就能很好的捕捉到店铺的经营状态。
回看这道比赛题目,我们是要完成对未来的预测,所以我们要掌握到未来的除了营销计划,还有本身商品的属性,未来的空间,当你能够精准捕捉到哪些商品能够具备爆款属性时,就意味着,你看到了80%的销售收入机会,同时,基于微观商品的属性,我们也会挖掘到哪些商品是滞销的,是不适合进行推广和上架的。对店铺的授信同时,对于店铺的经营,如果能够形成的有效干预,则未来的双向合作业务基础才扎实。
简单说,我们需要进行商品本身DNA的拆解,找到那些重要的影响购买的元素,而一旦捕捉到,则意味着,我们能够掌握的潜力和经营方向可以更加明确。这个可以举个例在,比如服饰行业,我们可以对一一件衣服进行解构,比如版型,面料,图案,类型,风格,季节等,基于这些潜藏在衣服中的要素,进行从微观元素组合起来的预测分析,寻找爆款元素和相对应的产品,因为这些控制了较大的销售份额,同时那些滞销的元素也能寻找出来,并且可以进行防范和处理,减少不必要的损失。
当然销售预测的问题,我们都预测的是未来,如果在开始我们能够提供未来可以很好销售的产品,那么销售的预测也将迎刃而解。这看似是废话,其实,当中我们会发现怎么找到爆款产品,如何挖掘爆款,就潜藏在我们已有的数据之中。
而整体销售的预测,除了宏观因素的配合,这些内在微观因素则是基础,因为他们是构成消费者购买的驱动力之一,而每个商品的精准捕捉销售可能性,也就计算出来整体的销售可能性。
最后再说一点的是,其实你看评论数据,我们不能简单的归结成1,0,-1,消费者的评论中隐藏了很多对于产品某一方面的钟爱或者厌恶,而这恰恰是其他消费群体看到后,是否产生驱动力购买的关键,以此出发,我们刚才的思路就可以顺下来。
关于销售预测的问题,今天就聊这么多。
如果大家感兴趣交流,可以加微信号:i-analysis,继续交流
网游数据挖掘与分析高级群(171461228)& 微信公众号:i-analysis,欢迎热衷于网游或者数据分析的各位前辈和新人加入,共同讨论学习。如有疑问请联系625528354@qq.com

 浙公网安备 33010602011771号
浙公网安备 33010602011771号