


Python的scrapy之爬取boss直聘网站
在我们的项目中,单单分析一个51job网站的工作职位可能爬取结果不太理想,所以我又爬取了boss直聘网的工作,不过boss直聘的网站一次只能展示300个职位,所以我们一次也只能爬取300个职位。
jobbossspider.py:
# -*- coding: utf-8 -*- import scrapy from ..items import JobbossItem class JobbosspiderSpider(scrapy.Spider): name = 'jobbosspider' #allowed_domains = ['https://www.zhipin.com/'] allowed_domains = ['zhipin.com'] # 定义入口URL #start_urls = ['https://www.zhipin.com/c101010100/?query=python&page=1&ka=page-1'] #北京 #start_urls=['https://www.zhipin.com/c100010000/h_101010100/?query=Python&ka=sel-city-100010000'] #全国 #start_urls=['https://www.zhipin.com/c101020100/h_101010100/?query=Python&ka=sel-city-101020100'] #上海 #start_urls=['https://www.zhipin.com/c101280100/h_101010100/?query=Python&ka=sel-city-101280100'] #广州 #start_urls=['https://www.zhipin.com/c101280600/h_101010100/?query=Python&ka=sel-city-101280600'] #深圳 #start_urls=['https://www.zhipin.com/c101210100/h_101010100/?query=Python&ka=sel-city-101210100'] #杭州 #start_urls=['https://www.zhipin.com/c101030100/h_101010100/?query=Python&ka=sel-city-101030100'] #天津 #start_urls=['https://www.zhipin.com/c101110100/h_101010100/?query=Python&ka=sel-city-101110100'] #西安 #start_urls=['https://www.zhipin.com/c101200100/h_101010100/?query=Python&ka=sel-city-101200100'] #武汉 #start_urls=['https://www.zhipin.com/c101270100/h_101010100/?query=Python&ka=sel-city-101270100'] #成都 start_urls=['https://www.zhipin.com/c100010000/h_101270100/?query=python%E7%88%AC%E8%99%AB&ka=sel-city-100010000'] #爬虫工程师,全国 # 定义解析规则,这个方法必须叫做parse def parse(self, response): item = JobbossItem() # 获取页面数据的条数 node_list = response.xpath("//*[@id=\"main\"]/div/div[2]/ul/li") # 循环解析页面的数据 for node in node_list: item["job_title"] = node.xpath(".//div[@class=\"job-title\"]/text()").extract()[0] item["compensation"] = node.xpath(".//span[@class=\"red\"]/text()").extract()[0] item["company"] = node.xpath("./div/div[2]/div/h3/a/text()").extract()[0] company_info = node.xpath("./div/div[2]/div/p/text()").extract() temp = node.xpath("./div/div[1]/p/text()").extract() item["address"] = temp[0] item["seniority"] = temp[1] item["education"] = temp[2] if len(company_info) < 3: item["company_type"] = company_info[0] item["company_finance"] = "" item["company_quorum"] = company_info[-1] else: item["company_type"] = company_info[0] item["company_finance"] = company_info[1] item["company_quorum"] = company_info[2] yield item # 定义下页标签的元素位置 next_page = response.xpath("//div[@class=\"page\"]/a/@href").extract()[-1] # 判断什么时候下页没有任何数据 if next_page != 'javascript:;': base_url = "https://www.zhipin.com" url = base_url + next_page yield scrapy.Request(url=url, callback=self.parse) ''' # 斜杠(/)作为路径内部的分割符。 # 同一个节点有绝对路径和相对路径两种写法。 # 绝对路径(absolute path)必须用"/"起首,后面紧跟根节点,比如/step/step/...。 # 相对路径(relative path)则是除了绝对路径以外的其他写法,比如 step/step,也就是不使用"/"起首。 # "."表示当前节点。 # ".."表示当前节点的父节点 nodename(节点名称):表示选择该节点的所有子节点 # "/":表示选择根节点 # "//":表示选择任意位置的某个节点 # "@": 表示选择某个属性 '''
items.py
import scrapy class JobbossItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() job_title = scrapy.Field() # 岗位 compensation = scrapy.Field() # 薪资 company = scrapy.Field() # 公司 address = scrapy.Field() # 地址 seniority = scrapy.Field() # 工作年薪 education = scrapy.Field() # 教育程度 company_type = scrapy.Field() # 公司类型 company_finance = scrapy.Field() # 融资 company_quorum = scrapy.Field() # 公司人数
pipelines输出管道:
class JobbossPipeline(object): def process_item(self, item, spider): print('职位名:',item["job_title"]) print('薪资:',item["compensation"]) print('公司名:',item["company"]) print('公司地点:',item["address"]) print('工作经验:',item["seniority"]) print('学历要求:',item["education"]) print('公司类型:',item["company_type"]) print('融资:',item["company_finance"]) print('公司人数:',item["company_quorum"]) print('-'*50) return item
pipelinemysql输入到数据库中:
# -*- coding: utf-8 -*- from week5_day04.dbutil import dbutil # 作业: 自定义的管道,将完整的爬取数据,保存到MySql数据库中 class JobspidersPipeline(object): def process_item(self, item, spider): dbu = dbutil.MYSQLdbUtil() dbu.getConnection() # 开启事物 # 1.添加 try: sql = "insert into boss_job (job_title,compensation,company,address,seniority,education,company_type,company_finance,company_quorum)values(%s,%s,%s,%s,%s,%s,%s,%s,%s)" #date = [] #dbu.execute(sql, date, True) dbu.execute(sql, (item["job_title"],item["compensation"],item["company"],item["address"],item["seniority"],item["education"],item["company_type"],item["company_finance"],item["company_quorum"]),True) dbu.commit() print('插入数据库成功!!') except: dbu.rollback() dbu.commit() # 回滚后要提交 finally: dbu.close() return item
在settings.py中开启如下设置
SPIDER_MIDDLEWARES = { 'jobboss.middlewares.JobbossSpiderMiddleware': 543, } DOWNLOADER_MIDDLEWARES = { 'jobboss.middlewares.JobbossDownloaderMiddleware': 543, 'scrapy.contrib.downloadermiddleware.useragent.UserAgentMiddleware': None, # 这一行是取消框架自带的useragent 'jobboss.rotateuseragent.RotateUserAgentMiddleware': 400 } ITEM_PIPELINES = { 'jobboss.pipelines.JobbossPipeline': 300, 'jobboss.pipelinesmysql.JobspidersPipeline': 301, } LOG_LEVEL='INFO' LOG_FILE='jobboss.log' #最后这两行是加入日志
最后启动项目,可以在pycharm自带的terminal中输入 :scrapy crawl 爬虫文件的名称
也可以创一个小的启动程序:
from scrapy.cmdline import execute execute(['scrapy', 'crawl', 'jobbosspider'])
爬虫启动结果:
数据库中的数据如下:
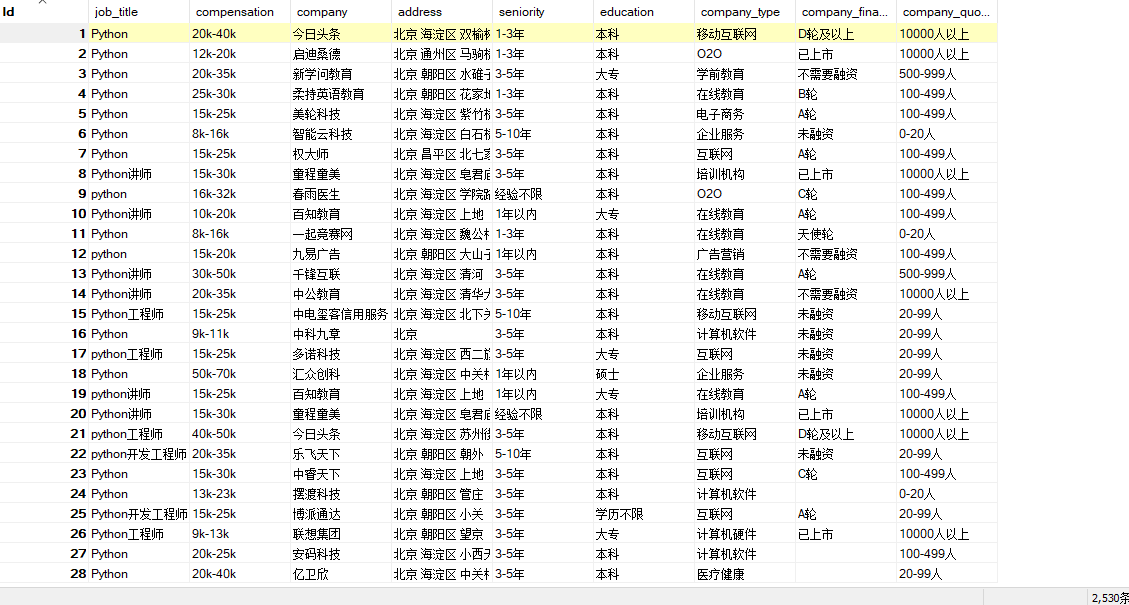
以上就是爬取boss直聘的所有内容了
